I took these notes while setting up Grafana and InfluxDB on Proxmox.
I hit a few minor issues so thought I’d post it here as a mini “How To” or reference for others.
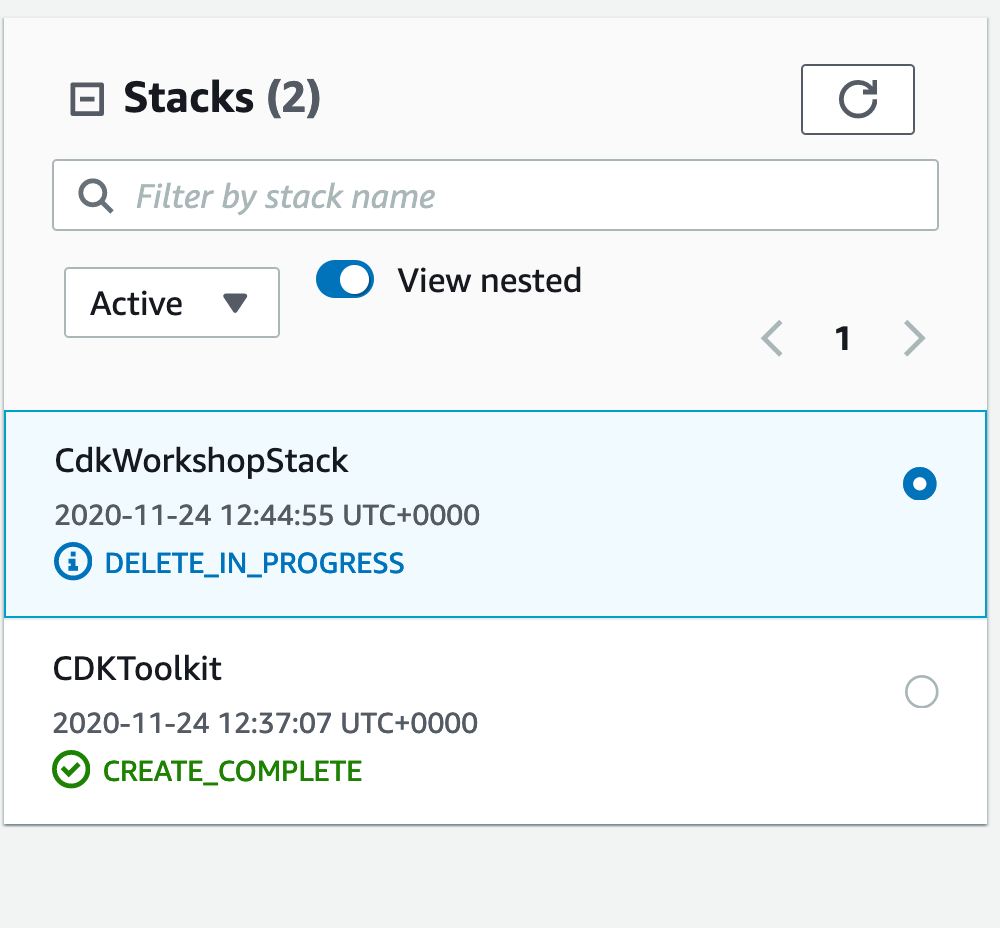
NOTE: If you are just looking for a simple and light-weight way to monitor Proxmox stats (including memory, CPU, disk for your LXCs and VMs), check out the brief section on “Pulse” at the end of this page!
This setup allows me to easily monitor my Proxmox host and the VMs and LXCs it runs via a nice Grafana dashboard, with the data/metrics stored in InfluxDB.
Note that the default user:password for Grafana is admin:admin
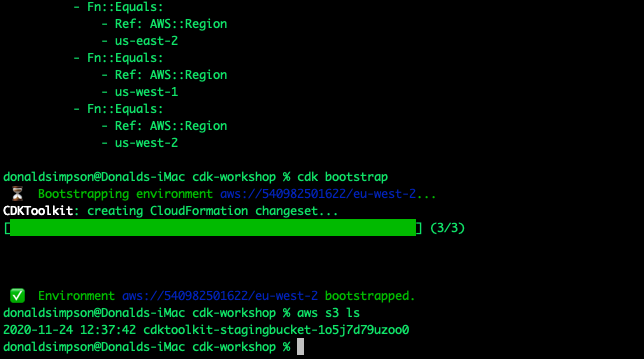
Configure Proxmox
Next you need to set the Metrics Server used byProxmox, this will tell proxmox to send all metrics on itself and the VMs and LXCs it runs to InfluxDB.
This is set under “Datacenter” in the proxmox UI:
This looked straightforward too, but there were conflicting opinions on how to do it. I initially went with UDP which didn’t work for me; there was nowhere to set any authentication and I wasn’t allowing anonymous access to InfluxDB, so I switched to using HTTP which then allowed me to specify the (InfluxDB) credentials.
Configure InfluxDB
I created a “proxmox” organisation and a “proxmox” bucket in InfluxDB
I then created an API key/Token specifically for that proxmox bucket, which I used in the above pic.
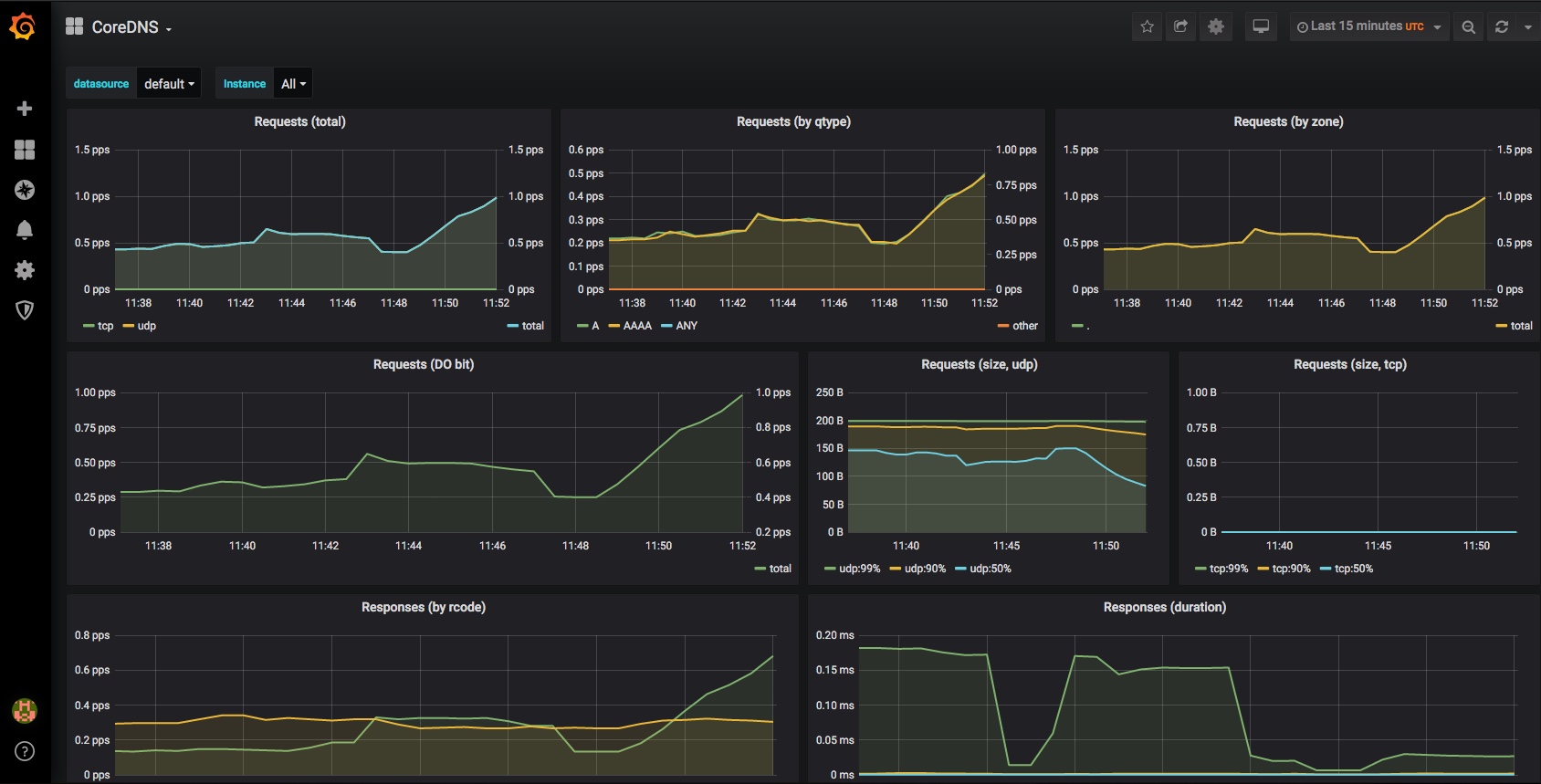
To verify things were working between Proxmox and InfluxDB, I took a look in the data explorer:
You can see in that pic that InfluxDB has data on my VMs and LXCs, which it must have received from Proxmox, so I then knew my remaining issues were with the connection between InfluxDB <-> Grafana.
Configure Grafana
Initially I was getting “InfluxDB returned error: Unauthorized error reading influxDB” – hence the check above to confirm that Proxmox -> InfluxDB was working ok.
I couldn’t see anywhere in this version of Grafana to specify the Token for InfluxDB though – other screenshots on the ‘net had & used that option, but it wasn’t available for me 🙁
After some reading I learned you could set the Token by creating a new Custom HTTP Header called “Authorization” with the value “Token BXx…….7yBkw==” (that’s the word Token, a space, then the full Token you got from InfluxDB, all set as the Value for a new Custom HTTP Header called Authorization…)
This seemed surprisingly flaky to me, but it worked.
My (working) connection details look like this:
Prior to adding that HTTP Header, I was getting a successful connection but “0 measurements found”.
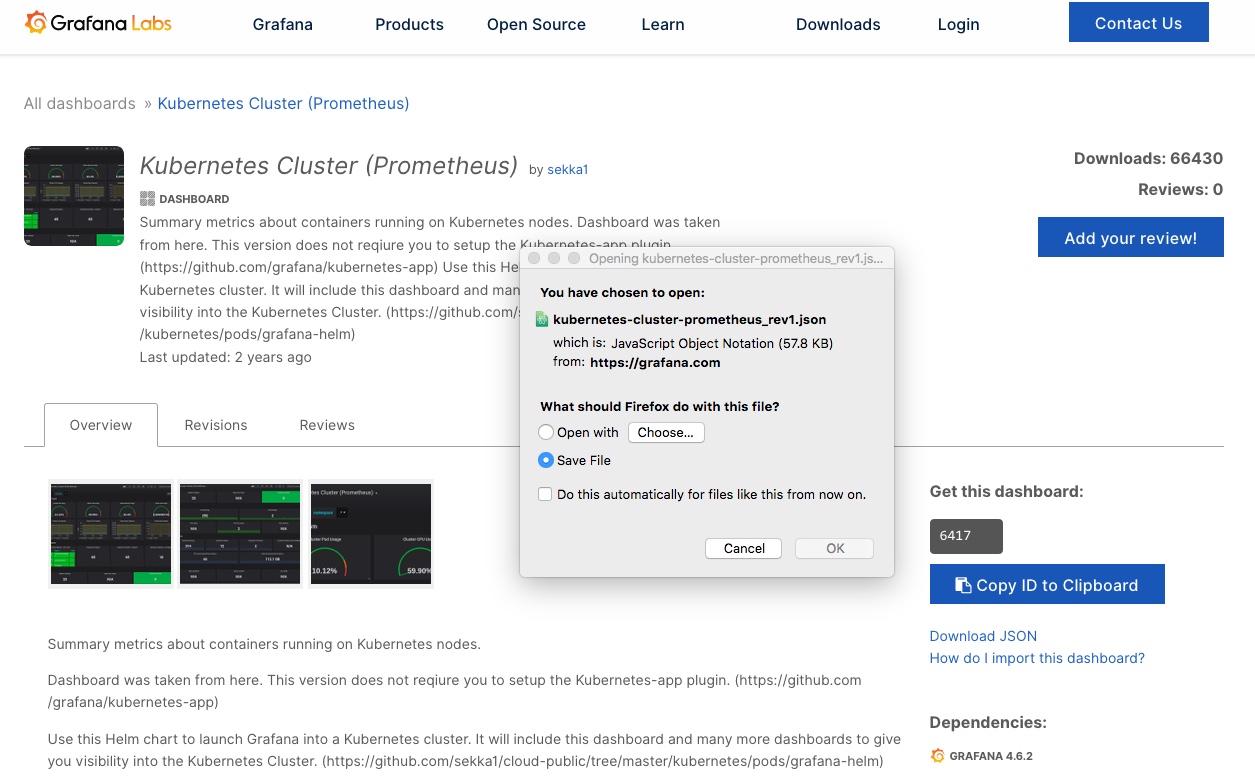
you don’t need to sign up there or anything else, just enter the ID: 10048 like in this pic and it’ll pull the Dashboard down:
Now I was finally able to see data being populated in Grafana from my Proxmox node & its VMs & LXCs:
Happy days.
The Pulse option
A possible alternative to the above Grafana and InfluxDB stack is to use “Pulse” – this was new to me and I have recently set it up too (you can never have enough monitoring!).
This is a very lightweight and more focused option that is really quick and easy to set up.
While the InfluxDB and Grafana approach can be extended to cover a vast range of monitoring and alerting for all sorts of things – I have set up and used it in several large companies I’ve worked for – if all you really want is Proxmox monitoring without those possibilities, this looks perfect.
Being a fan of Solana and interested in exploring and using the technology, I wanted to find some practical use for it in my role as a DevOps Engineer.
This post attempts to do that, by integrating Solana in to a CI/CD workflow to provide an audit of build artefacts. Yes, there are many other ways & tools you could do this, but I found this particular combination interesting.
Overview
Solana is a high-performance blockchain platform known for its speed and scalability.
Integrating Solana with GitHub Workflows can bring a new level of security, transparency, and efficiency to your CI/CD pipelines.
This blog post demonstrates how to leverage Solana in a GitHub Workflow to enhance your development and deployment processes.
What is Solana?
Solana is a decentralised blockchain platform designed for high throughput and low latency. It supports smart contracts and decentralized applications (dApps) with a focus on scalability and performance. Solana’s unique consensus mechanism, Proof of History (PoH), allows it to process thousands of transactions per second.
Why Integrate Solana with GitHub Workflows?
Integrating Solana with GitHub Workflows can provide several benefits:
Immutable Build Artifacts: Store cryptographic hashes of build artifacts on the Solana blockchain to ensure their integrity and immutability.
Automated Smart Contract Deployment: Use Solana smart contracts to automate deployment processes.
Transparent Audit Trails: Record CI/CD pipeline activities on the blockchain for transparency and auditability.
Setting Up Solana in a GitHub Workflow
Let’s walk through an example of how to integrate Solana with a GitHub Workflow to store build artifact hashes on the Solana blockchain.
Step 1: Install Solana CLI
Ensure you have the Solana CLI installed on your local machine or CI environment:
sh -c "$(curl -sSfL https://release.solana.com/v1.8.0/install)"
Step 2: Set Up a Solana Wallet
Then, you need a Solana wallet to interact with the blockchain. You can use the Solana CLI to create a new wallet:
solana-keygen new --outfile ~/my-solana-wallet.json
This command generates a new wallet and saves the keypair to ~/my-solana-wallet.json.
Step 3: Create a GitHub Workflow
Create a new GitHub Workflow file in your repository at .github/workflows/solana.yml:
name: Solana Integration
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Solana CLI
run: |
sh -c "$(curl -sSfL https://release.solana.com/v1.8.0/install)"
export PATH="/home/runner/.local/share/solana/install/active_release/bin:$PATH"
solana --version
- name: Build project
run: |
# Replace with your build commands
echo "Building project..."
echo "Build complete" > build-artifact.txt
- name: Generate SHA-256 hash
run: |
sha256sum build-artifact.txt > build-artifact.txt.sha256
cat build-artifact.txt.sha256
- name: Store hash on Solana blockchain
env:
SOLANA_WALLET: ${{ secrets.SOLANA_WALLET }}
run: |
echo $SOLANA_WALLET > ~/my-solana-wallet.json
solana config set --keypair ~/my-solana-wallet.json
solana airdrop 1
HASH=$(cat build-artifact.txt.sha256 | awk '{print $1}')
solana transfer <RECIPIENT_ADDRESS> 0.001 --allow-unfunded-recipient --memo "$HASH"
Step 4: Configure GitHub Secrets
To securely store your Solana wallet keypair, add it as a secret in your GitHub repository:
Go to your repository on GitHub.
Click on Settings.
Click on Secrets in the left sidebar.
Click on New repository secret.
Add a secret with the name SOLANA_WALLET and the content of your ~/my-solana-wallet.json file.
Step 5: Run the Workflow
Push your changes to the main branch to trigger the workflow. The workflow will:
Check out the code.
Set up the Solana CLI.
Build the project.
Generate a SHA-256 hash of the build artifact.
Store the hash on the Solana blockchain.
Example Output and Actions
After the workflow runs, you can verify the transaction on the Solana blockchain using a block explorer like Solscan. The memo field of the transaction will contain the SHA-256 hash of the build artifact, ensuring its integrity and immutability.
Example Output:
Run sha256sum build-artifact.txt > build-artifact.txt.sha256
b1946ac92492d2347c6235b4d2611184a1e3d9e6 build-artifact.txt
Run solana transfer <RECIPIENT_ADDRESS> 0.001 --allow-unfunded-recipient --memo "b1946ac92492d2347c6235b4d2611184a1e3d9e6"
Signature: 5G9f8k9... (shortened for brevity)
Possible Actions:
Verify Artifact Integrity: Use the stored hash to verify the integrity of the build artifact before deployment.
Audit Trail: Maintain a transparent and immutable audit trail of all build artifacts.
Automate Deployments: Extend the workflow to trigger automated deployments based on the stored hashes.
Conclusion
Integrating Solana with GitHub Workflows provides a powerful way to enhance the security, transparency, and efficiency of your CI/CD pipelines.
By leveraging Solana’s blockchain technology, you can ensure the integrity and immutability of your build artifacts, automate deployment processes, and maintain transparent audit trails.
I have used solutions similar to this previously; by automatically adding a containers hash to an immutable database when it passes testing, while at the same time ensuring that the only images permissable for deployment in the next environment up (e.g. Production) exist on that list, you can (at least help to) ensure that only approved code is deployed.
In the ever-evolving landscape of software development, ensuring the integrity and security of build artifacts is paramount. As CI/CD pipelines become more sophisticated, integrating cryptocurrency technologies can provide a robust solution for managing and securing build artifacts. This blog post delves into the concept of immutable build artifacts and how crypto technologies can enhance CI/CD pipelines.
Understanding CI/CD Pipelines
CI/CD pipelines are automated workflows that streamline the process of integrating, testing, and deploying code changes. They aim to:
Continuous Integration (CI): Automatically integrate code changes from multiple contributors into a shared repository, ensuring a stable and functional codebase.
Continuous Deployment (CD): Automatically deploy integrated code to production environments, delivering new features and fixes to users quickly and reliably.
The Importance of Immutable Build Artifacts
Build artifacts are the compiled binaries, libraries, and other files generated during the build process. Ensuring these artifacts are immutable—unchangeable once created—is crucial for several reasons:
Security: Prevents tampering and unauthorized modifications.
Reproducibility: Ensures that the same artifact can be deployed consistently across different environments.
Auditability: Provides a clear and verifiable history of artifacts.
Leveraging Crypto Technologies for Immutable Build Artifacts
Decentralization: Distributes data across multiple nodes, reducing the risk of a single point of failure.
Immutability: Ensures that once data is written, it cannot be altered or deleted.
Transparency: Provides a transparent and auditable history of all transactions.
Implementing Immutable Build Artifacts in CI/CD Pipelines
Generate Build Artifacts: During the CI process, generate the build artifacts as usual.
# Example: Building a Docker image
docker build -t my-app:latest .
Create a Cryptographic Hash: Generate a cryptographic hash (e.g., SHA-256) of the build artifact to ensure its integrity.
# Example: Generating a SHA-256 hash of a Docker image
docker save my-app:latest | sha256sum
Store the Hash on a Blockchain: Store the cryptographic hash on a blockchain to ensure immutability and transparency.
# Example: Using a blockchain-based storage service
blockchain-store --hash <generated-hash> --metadata "Build #123"
Retrieve and Verify the Hash: When deploying the artifact, retrieve the hash from the blockchain and verify it against the artifact to ensure integrity.
Verify the artifact’s integrity using the retrieved hash.
Deploy the verified artifact to the production environment.
Benefits of Using Immutable Build Artifacts
Enhanced Security: Blockchain’s immutable nature ensures that build artifacts are secure and tamper-proof.
Improved Reproducibility: Immutable artifacts guarantee consistent deployments across different environments.
Increased Transparency: Blockchain provides a transparent and auditable history of all build artifacts.
Conclusion
Integrating cryptocurrency technologies with CI/CD pipelines to manage immutable build artifacts offers a range of benefits that enhance security, reproducibility, and transparency. By leveraging blockchain’s decentralized and immutable nature, organizations can ensure the integrity and authenticity of their build artifacts, providing a robust foundation for their CI/CD processes.
As the software development landscape continues to evolve, embracing these cutting-edge technologies will be crucial for maintaining a competitive edge and ensuring the reliability and security of software deployments. By implementing immutable build artifacts, organizations can build a more secure and efficient CI/CD pipeline, paving the way for future innovations.
This is the next step in a series on using the AWS CDK and AWS CodePipeline.
In the previous post I set up a new local AWS CDK environment and a remote AWS Cloud account, user etc, and connected the two. That got as far as deploying a simple local AWS CDK application to my AWS account and then cleaning it up. This post looks at the next step which is setting up CodeCommit – AWS’s managed and git-based version control system, much like github or gitlab – in preparation for some AWS CodePipeline and AWS CodeBuild posts that will follow on.
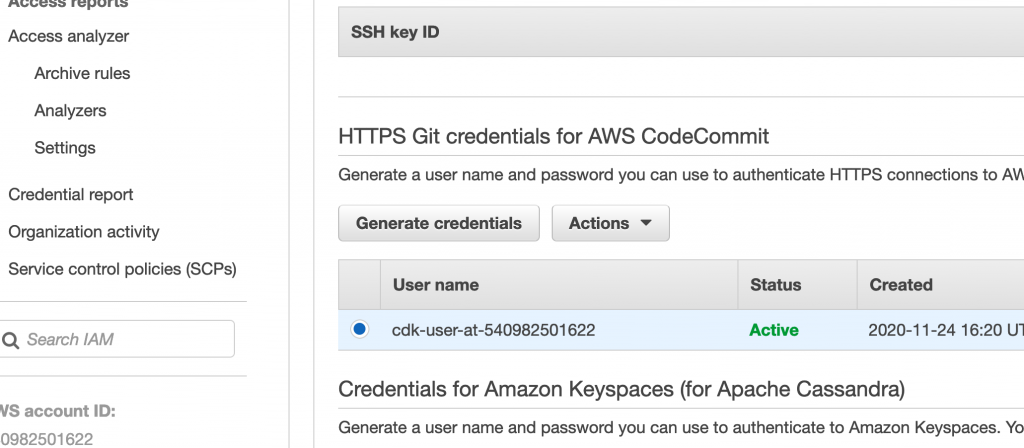
The first step is to add permissions to AWS CodeCommit for your IAM user – I’m using the “cdk-user” that was created previously – as detailed here:
In the AWS UI, go to IAM > User > Security Credentials: Select the “HTTPS Git credentials for AWS CodeCommit (Generate)” option then download the newly generated credentials:
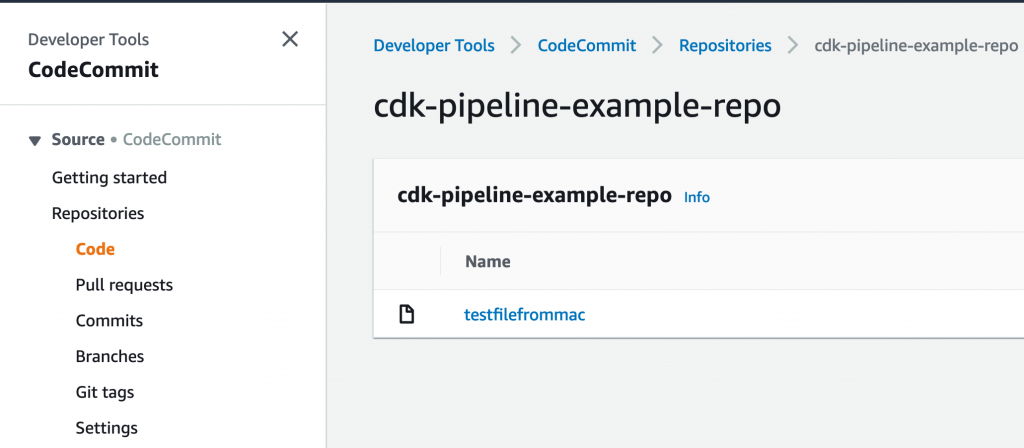
In CodeCommit, create a new Repo if you don’t already have one, click Clone and select/copy the HTTPS link
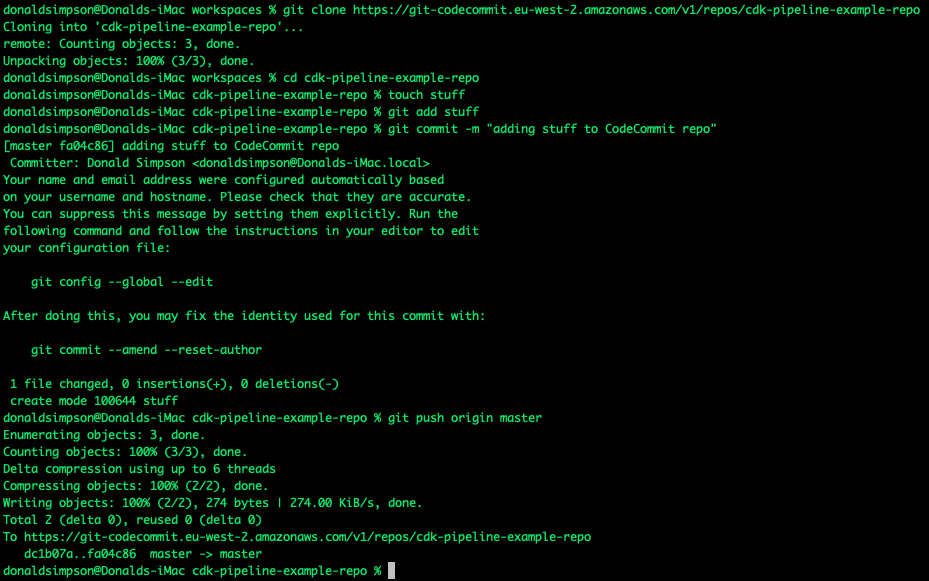
In your local cli, do a “git clone” of the HTTPS repo
when prompted, supply the credentials from above.
You should now be able to interact with the AWS CodeCommit repo in your AWS account using your local git cli in the same way you would for github, bitbucket or gitlab – an example clone, add, merge and push to master (!) as a quick test:
In the next post, this setup will be used to manage and host the source code for new AWS CDK applications, and to manage and trigger the AWS CodePipelines (also written in CDK!) that will build and deploy them.
These are my notes on setting up a new development environment to use the AWS CDK.
Most of this is very well documented already but I’m planning on using this setup for a few upcoming posts, so thought I’d start at the very beginning.
I’m using a Mac but the steps are much the same regardless of OS.
Go to the IAM console in your AWS account and select Users> Create User
I called mine “cdk-user“. Select to enable Programattic Access and add an Admin policy. At the end of the process, select to download the new users credentials.
In your local command line, run:
aws configure
this will prompt you to supply the newly created credentials. Once that is done, you can test connectivity from your local shell to your AWS account with some simple aws commands like:
aws s3 ls
which should simply list the S3 buckets in your account to prove connectivity is working; it may return nothing if there are no buckerts, or an error if it can’t connect.
Verify with a simple example
Now is a good time to decide on an IDE like vscode or atom.
They both have extensions and plugins that make CDK development easier, no matter which language you choose to develop your CDK apps in.
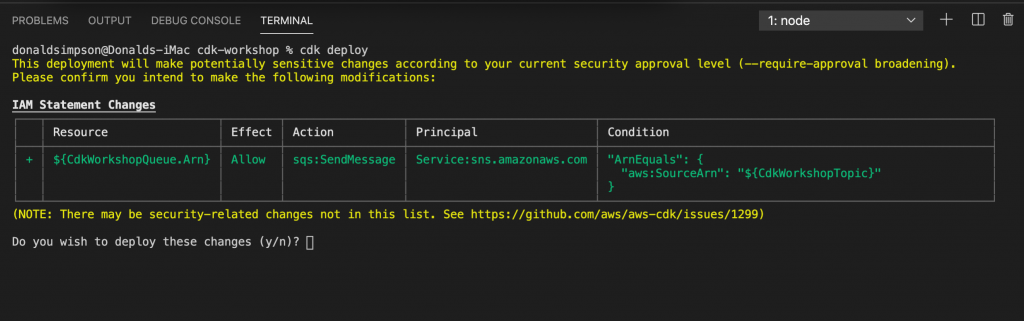
This creates an S3 bucket in our AWS account with the supporting files needed by CDK. This only needs done once.
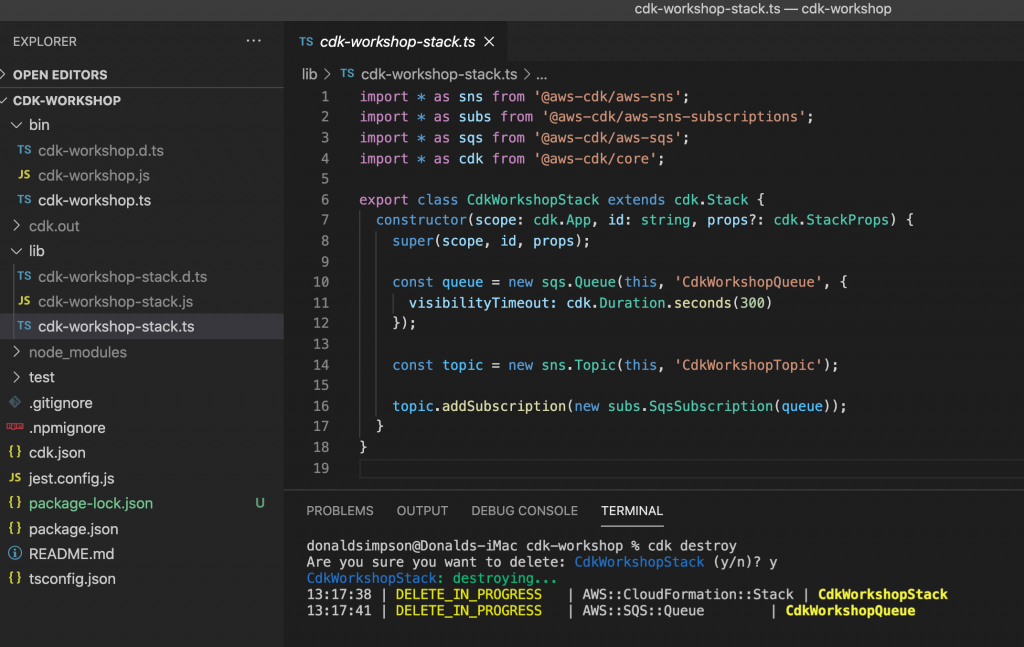
take a look around the example app’s code, there are a few files of interest: lib/cdk-workshop-stack.ts contains the tiny amount of code used to create an SQS queue and an SNS topic package.json details the project dependencies and node shortcuts for building, watching, testing etc README.md details some useful commands and describes the overall project
After boot-strapping, if you run another
aws s3 ls
you should now see the bootstrap S3 bucket.
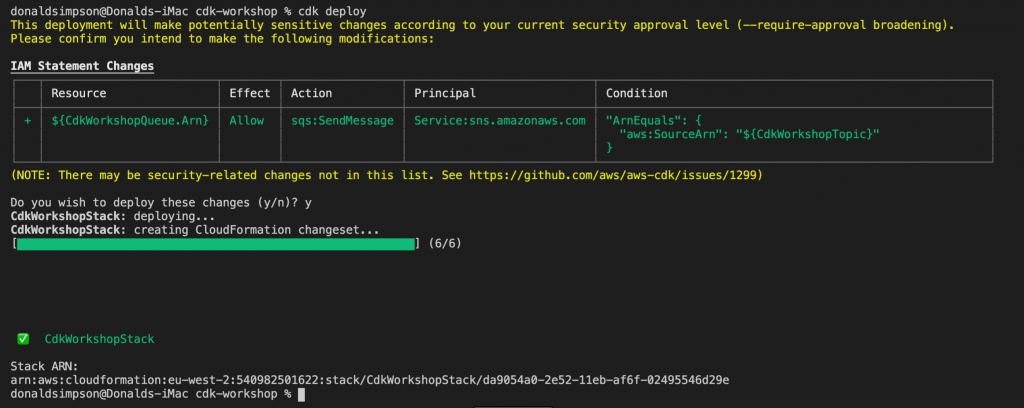
and when ready, you can deploy the simple example app with
cdk deploy
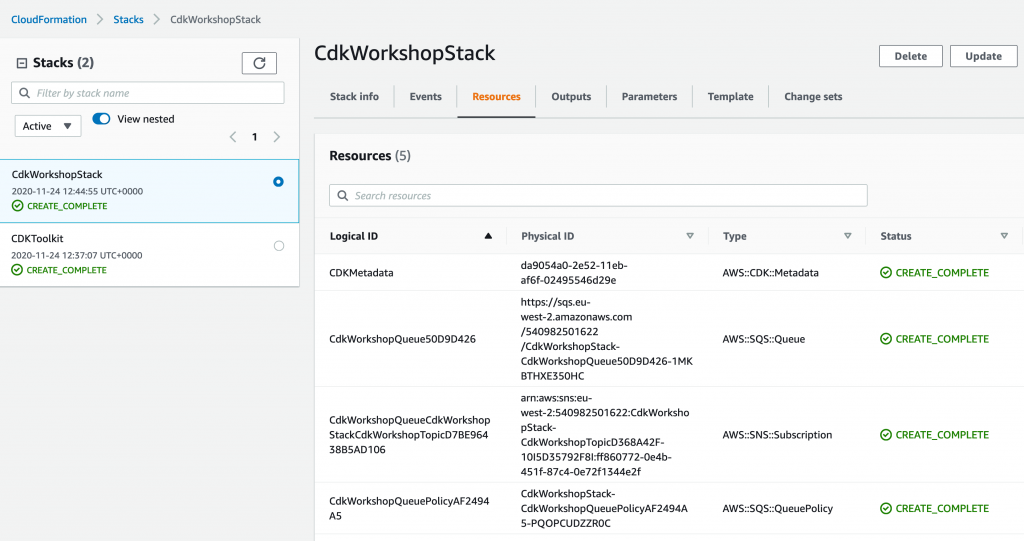
CDK will let you know in advance what is is planning on doing – which resources will be created, deleted or altered, giving you a chance to backout
After confirming you want to go ahead with these changes, you should soon see the new stack within your CloudFormation console, along with the CDK toolkit stack we bootstrapped
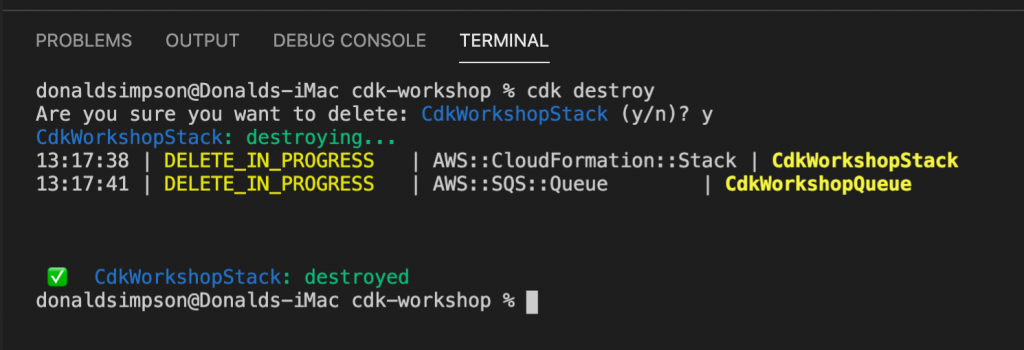
to delete the example stack and clean up, simply do
cdk destroy
That’s it – the local environment is set up and can connect to the AWS account, a very simple app has been built, tested, deployed and deleted, and the one-off CDK bootstrapping has been done.
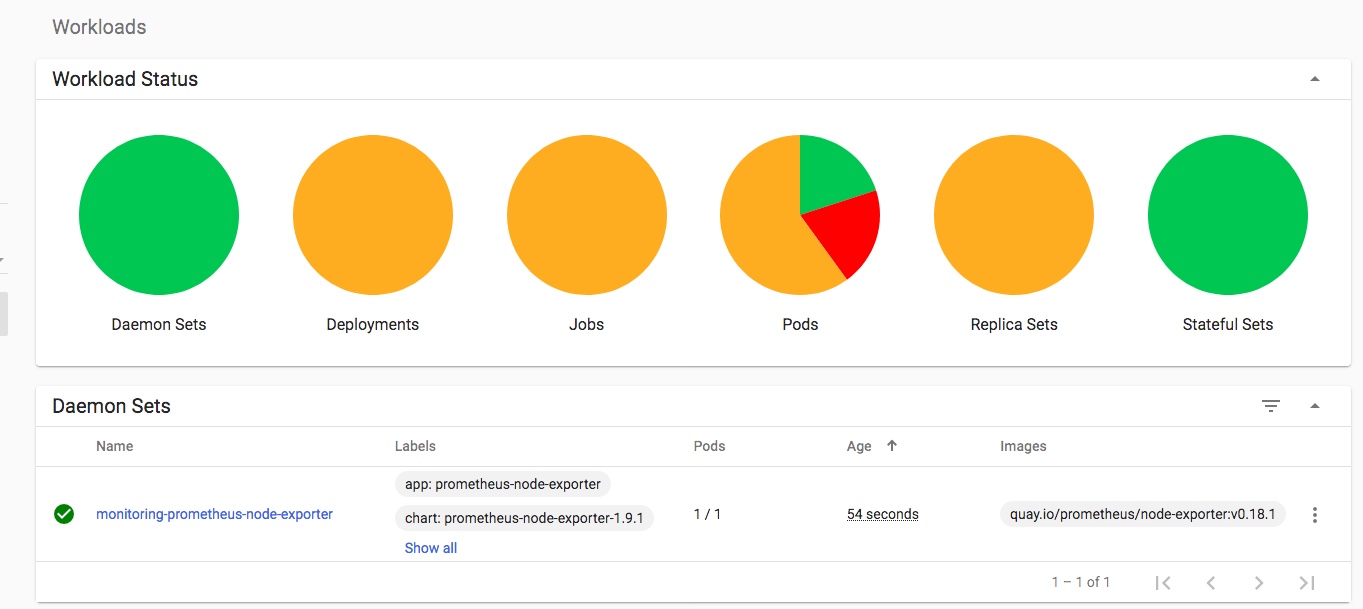
This post takes a look at setting up monitoring and alerting in Kubernetes, using Helm and Kubernetes Operators to deploy and configure Prometheus and Grafana.
This platform is quickly and easily deployed to the cluster using a Helm Chart, which in turn uses a Kubernetes Operator, to setup all of the required resources in an existing Kubernetes Cluster.
I’m re-using the Minikube Kubernetes cluster with Helm that was built and described in previous posts here and here, but the same steps should work for any working Kubernetes & Helm setup.
An example Grafana Dashboard for Kubernetes monitoring is then imported and we take a quick look at monitoring of Cluster components with other dashboards
It may sound like Helm and Operators do much the same thing, but they are different and complimentary
Helm and Operators are complementary technologies. Helm is geared towards performing day-1 operations of templatization and deployment of Kubernetes YAMLs — in this case Operator deployment. Operator is geared towards handling day-2 operations of managing application workloads on Kubernetes.
I’m reusing the Minikube cluster from previous posts, so start it back up with:
minikube start
which outputs the following in the console
🎉 minikube 1.10.1 is available! Download it: https://github.com/kubernetes/minikube/releases/tag/v1.10.1 💡 To disable this notice, run: ‘minikube config set WantUpdateNotification false’
🙄 minikube v1.9.2 on Darwin 10.13.6 ✨ Using the virtualbox driver based on existing profile 👍 Starting control plane node m01 in cluster minikube 🔄 Restarting existing virtualbox VM for “minikube” … 🐳 Preparing Kubernetes v1.18.0 on Docker 19.03.8 … 🌟 Enabling addons: dashboard, default-storageclass, helm-tiller, metrics-server, storage-provisioner 🏄 Done! kubectl is now configured to use “minikube”
this all looks ok, and includes the minikube addons I’d selected previously. Now a quick check to make sure my local helm repo is up to date:
helm repo update
I then used this command to find the latest version of the stable prometheus-operator via a helm search: helm search stable/prometheus-operator --versions | head -2
there’s no doubt a neater/builtin way to find out the latest version, but this did the job – I’m going to install 8.13.8:
install the prometheus operator using Helm, in to a new dedicated “monitoring” namespace just takes this one command: helm install stable/prometheus-operator --version=8.13.8 --name=monitoring --namespace=monitoring
Ooops
that should normally be it, but for me, this resulted in some issues along these lines:
Error: Get http://localhost:8080/version?timeout=32s: dial tcp 127.0.0.1:8080: connect: connection refused
– looks like Helm can’t communicate with Tiller any more; I confirmed this with a simple helm ls which also failed with the same message. This shouldn’t be a problem when v3 of Helm goes “tillerless”, but to fix this quickly I simply re-enabled Tiller in my cluster via Minikube Addons:
verified things worked again with helm ls, then the helm install... command worked and started to do its thing…
New Operator and Namespace
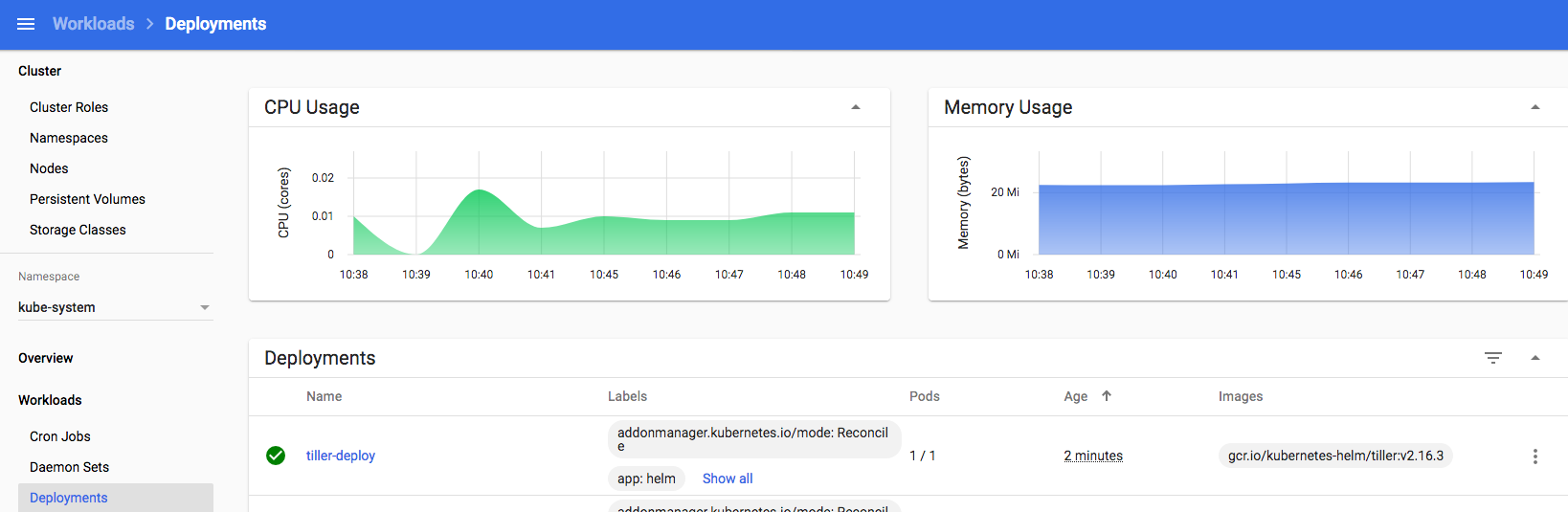
Keeping an eye on progress in my k8s dashboard, I can see the new “monitoring” namespace has been created, and the various Operator components are being downloaded, started up and configured:
you can also keep an eye on progress with: watch -d kubectl get po --namespace=monitoring
this takes a while on my machine, but eventually completes with this console output:
NOTES: The Prometheus Operator has been installed. Check its status by running: kubectl –namespace monitoring get pods -l “release=monitoring”
Visit https://github.com/coreos/prometheus-operator for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
kubectl get po --namespace=monitoring shows the pods now running in the cluster, and for this quick example the easiest way to get access to the new Grafana instance is to forward the pods port 3000 to localhost like this:
the default user for this Grafana is “admin” and the password for that user is “prom-operator“, so log in with those credentials…
Grafana Dashboards for Kubernetes
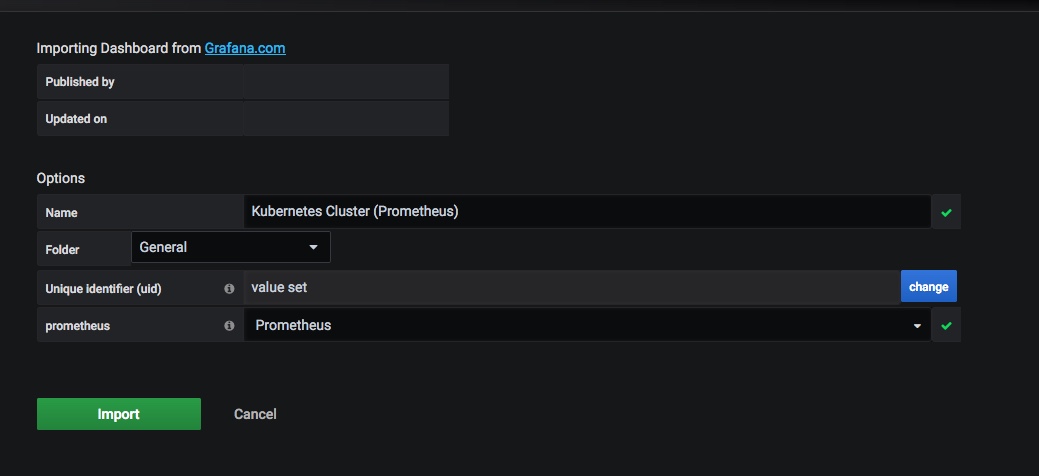
We can now use the ready-made Grafana dashboards, or add/import ones from the extensive online collection, like this one here for example: https://grafana.com/grafana/dashboards/6417 – simply save the JSON file
then go to Grafana and import it with these settings:
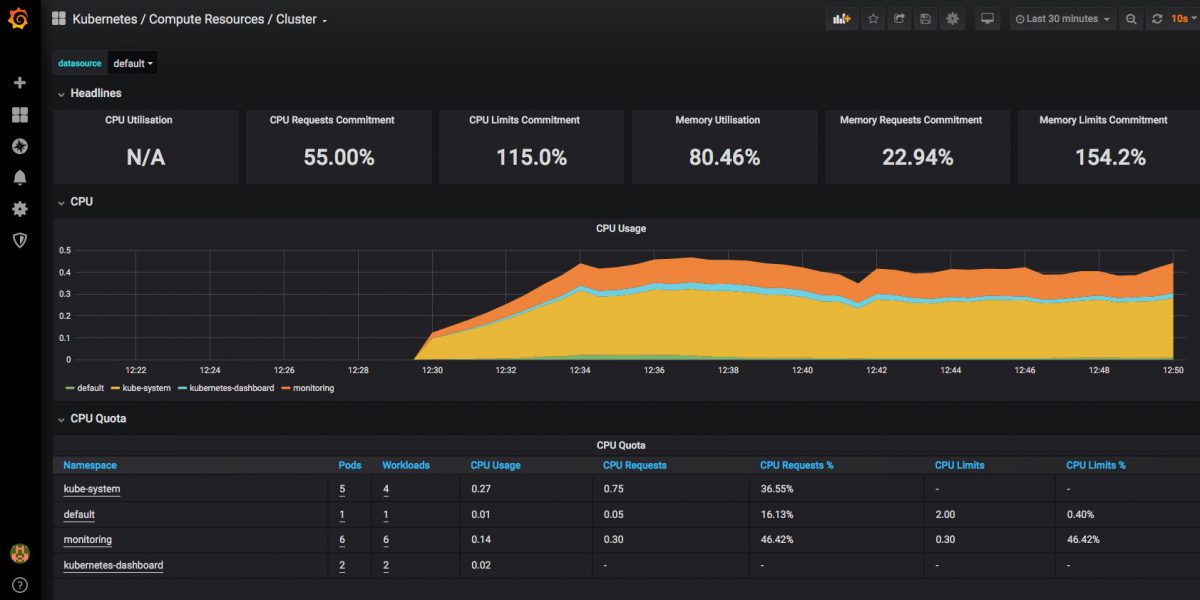
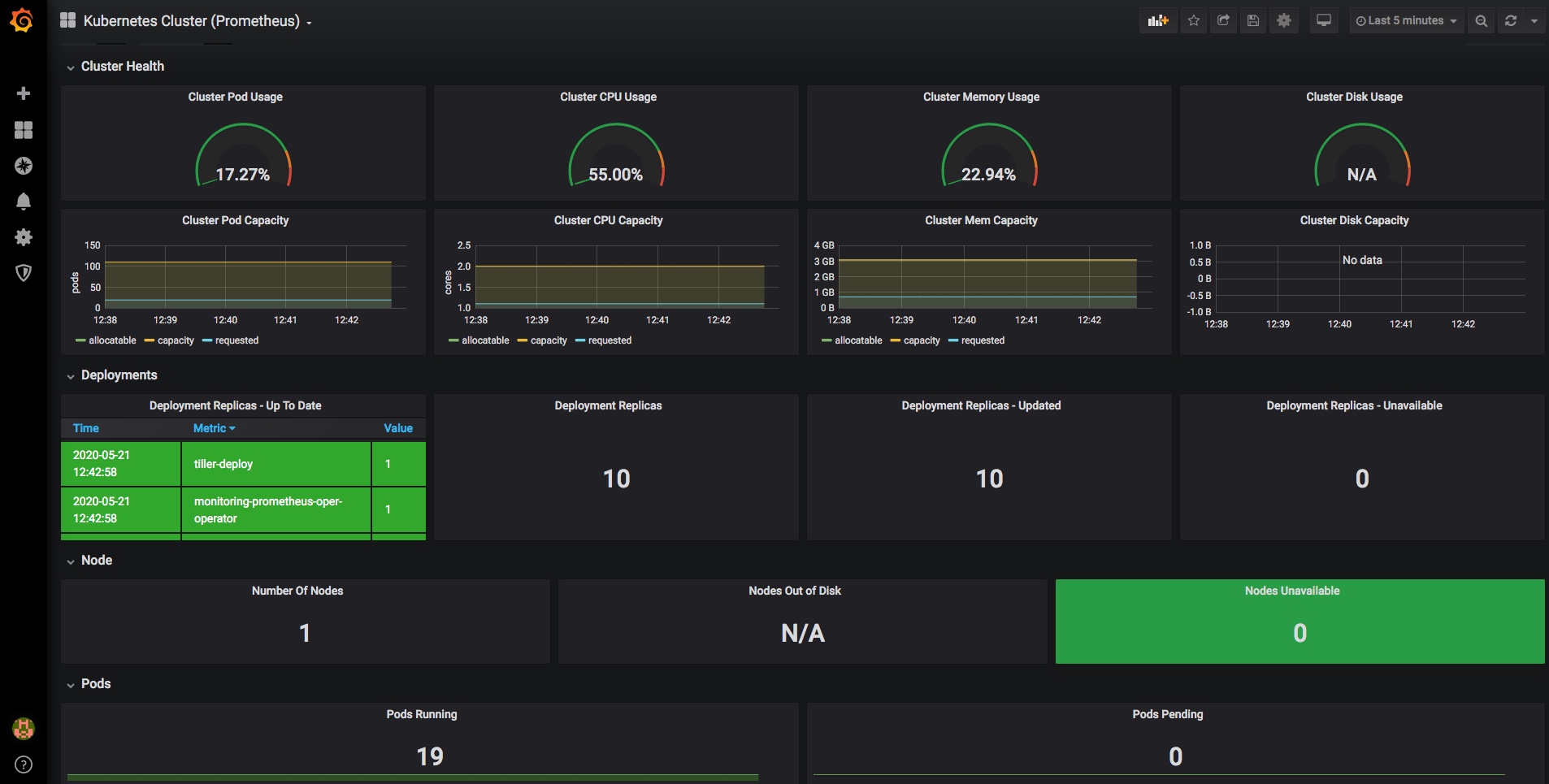
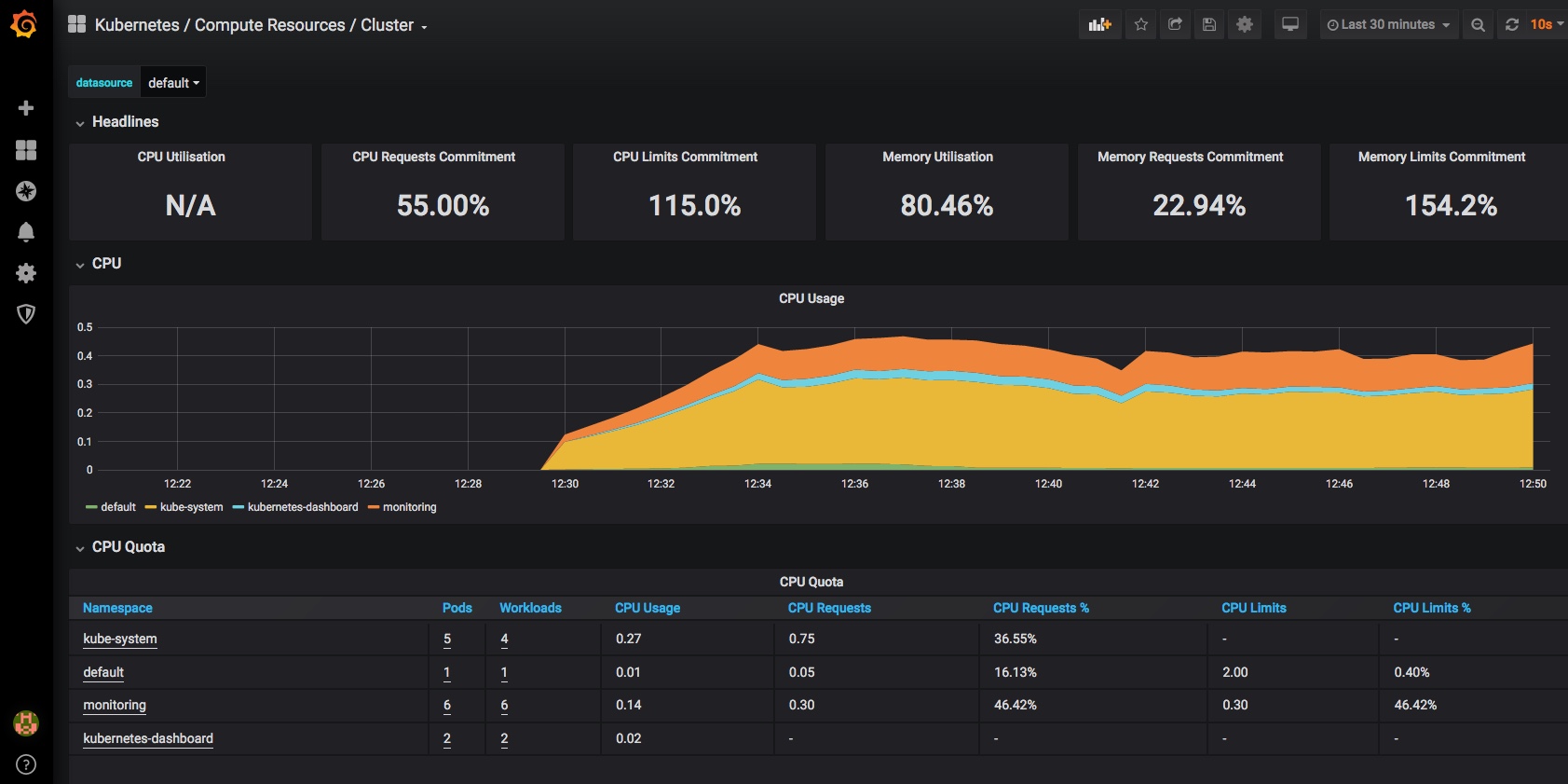
and you should now have a dashboard showing some pretty helpful stats on your kubernetes cluster, it’s health and resource usage:
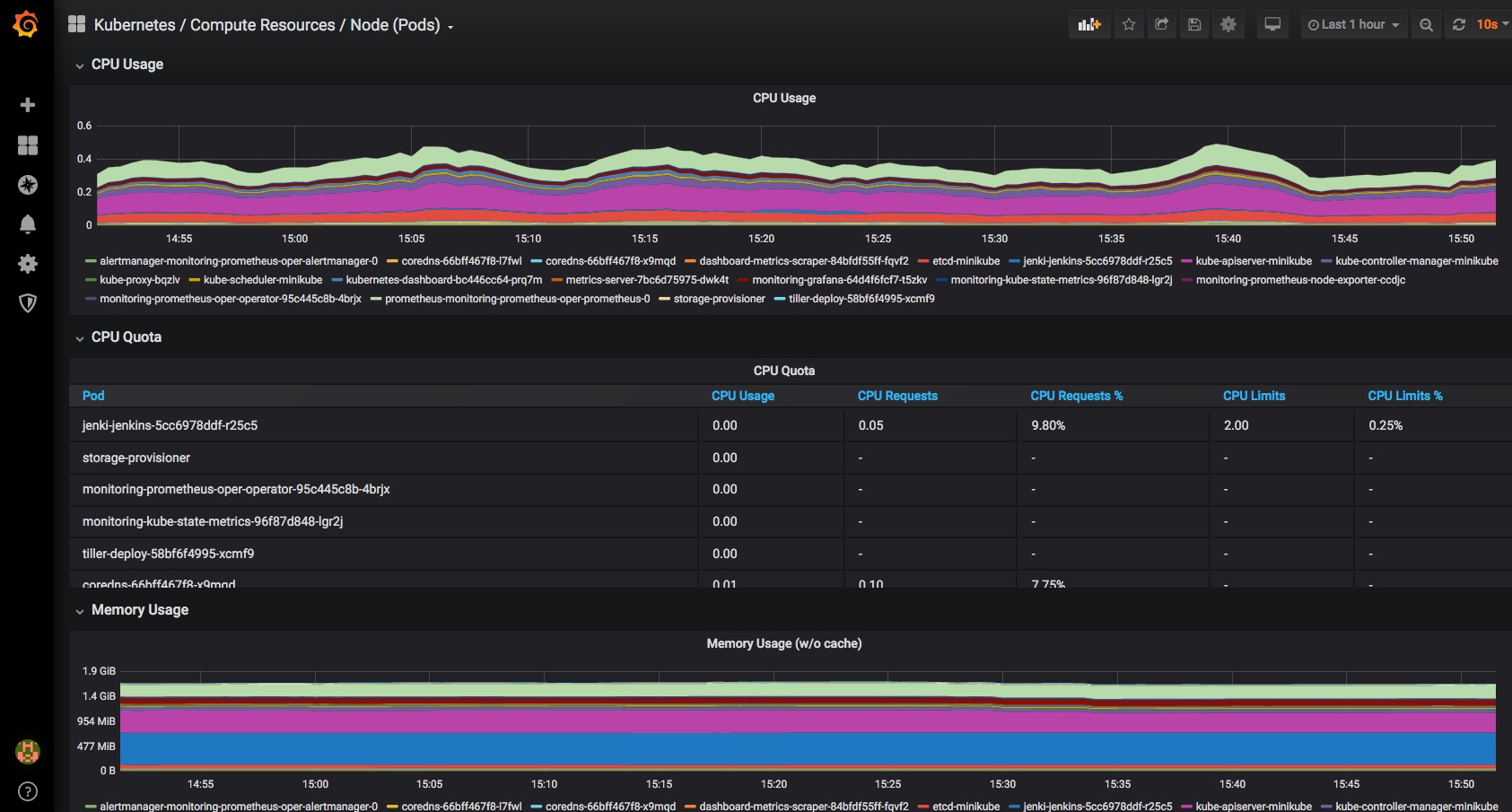
Finally a very quick look at some of the other inbuilt dashboards – you can use and adjust these to monitor all of the components that comprise your cluster and set up alerting when limits or triggers are reached:
All done & next steps
There’s a whole lot more that can be done here, and many other ways to get to this point, but I found this pretty quick and easy.
I’ve only been looking at monitoring of k8s resources here, but you can obviously set up grafana dashboards for many other things, like monitoring your deployed applications. Many applications (and charts and operators) come with prom endpoints built in, and can easily and automatically be added to your monitoring and alerting dashboards along with other datasources.
That post went as far as having a Kubernetes cluster up and running for local development. That was primarily focused on Mac, but once you reach the point of having a running Kubernetes Cluster with kubectl configured to talk to it, the hosting platform/OS makes little difference.
This second section takes a more detailed look at running Jenkins Pipelines inside the Kubernetes Cluster, and automatically provisioning Jenkins JNLP Agents via Kubernetes, then takes an in-depth look at what we can do with all of that, with a complete working example.
This post covers quite a lot:
Adding Helm to the Kubernetes cluster for package management
Deploying Jenkins on Kubernetes with Helm
Connecting to the Jenkins UI
Setting up a first Jenkins Pipeline job
Running our pipeline and taking a look at the results
What Next
Adding Helm to the Kubernetes cluster for package management
Helm is a package manager for Kubernetes, and like Minikube it is ideal for quickly setting up development environments, plus much more if you want to. Take a look through the Helm hub to see just some of the other things it can do.
On Mac you can use brew to install the local helm component:
you should then see a tiller pod start up in your Kubernetes kube-system namespace:
Before you can use Helm we first need to initialise the local Helm client, so simply run:
helm init --client-only
as our earlier minikube addons command has configured the connectivity and cluster already. Before we can use Helm to install Jenkins (or any of the many other things it can do), we need to update the local repo that contains the Helm Charts:
helm repo update
Hang tight while we grab the latest from your chart repositories…
…Skip local chart repository
…Successfully got an update from the "stable" chart repository
Update Complete.
That should be Helm setup complete and ready to use now.
Deploying Jenkins on Kubernetes with Helm
Now that Helm is setup and can speak to our k8s instance, installing 100’s of software packages suddenly becomes very simple – including, Jenkins. We’ll just give the install a friendly name “jenki” and use NodePort to simplify the networking, nothing more is required for this dev setup:
obviously we’re skipping over all the for-real things you may want for a longer lived Jenkins instance, like backups, persistence, resilience, authentication and authorisation etc., but this bare-bones setup is sufficient for now.
Connect to the Jenkins UI
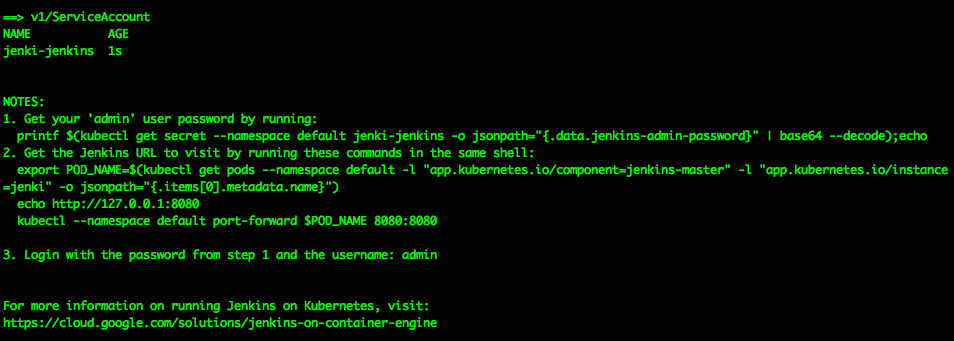
The Helm install should spit out some helpful info like this, explaining how to get the Jenkins Admin password and how to connect to the UI:
Get your ‘admin’ user password by running: printf $(kubectl get secret –namespace default jenki-jenkins -o jsonpath=”{.data.jenkins-admin-password}” | base64 –decode);echo
Get the Jenkins URL to visit by running these commands in the same shell: export POD_NAME=$(kubectl get pods –namespace default -l “app.kubernetes.io/component=jenkins-master” -l “app.kubernetes.io/instance=jenki” -o jsonpath=”{.items[0].metadata.name}”) echo http://127.0.0.1:8080 kubectl –namespace default port-forward $POD_NAME 8080:8080
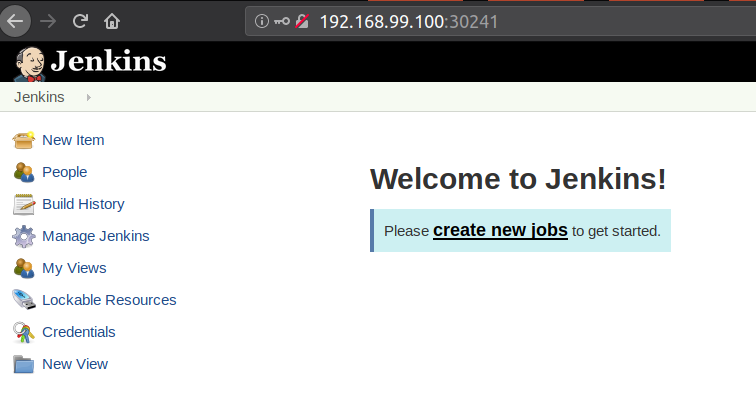
Login with the password from step 1 and the username: admin
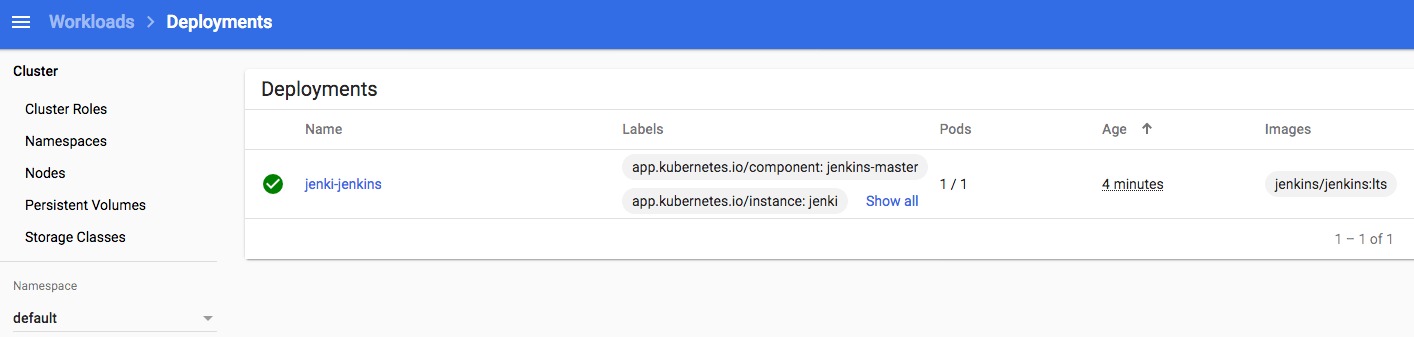
After following the steps to get the admin password and hit the Jenkins URL http://127.0.0.1:8080 in your desktop browser, you should see the familiar “Welcome to Jenkins!” page…
Pause a moment to appreciate that this Jenkins is running in a JVM inside a Docker container on a Kubernetes Pod as a Service in a Namespace in a Kubernetes Instance that’s running inside a Virtual Machine running under a Hypervisor on a host device….
turtles all the way down
there are many things I’ve skipped over here, including looking at storage, auth, security and all the usual considerations but the aim has been to quickly and easily get to this point so we can start developing the pipelines and processes we’re really wanting to focus on.
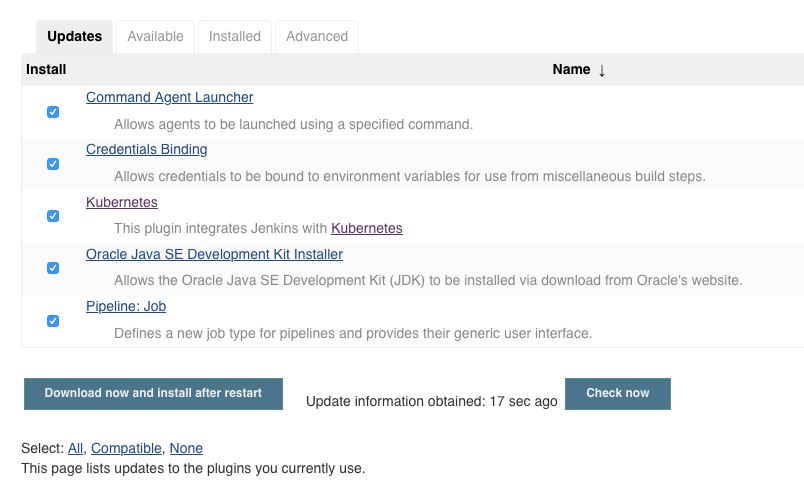
Navigating to Manage Jenkins then Plugins Manager should show some updates already available – this proves we have connectivity to the public Jenkins Update Centre out of the box. The Kubernetes Jenkins plugin is the key thing I’m looking for – select and update if required:
If you go to http://127.0.0.1:8080/configure you should see a link at the foot of the page to the new location for “Clouds”: http://127.0.0.1:8080/configureClouds/ – that should already be configured with sufficient settings for Jenkins to use your Kubernetes cluster, but it’s worthwhile taking a look through the settings and options there. No changes should be required here now though.
Setup a first Jenkins Pipeline job
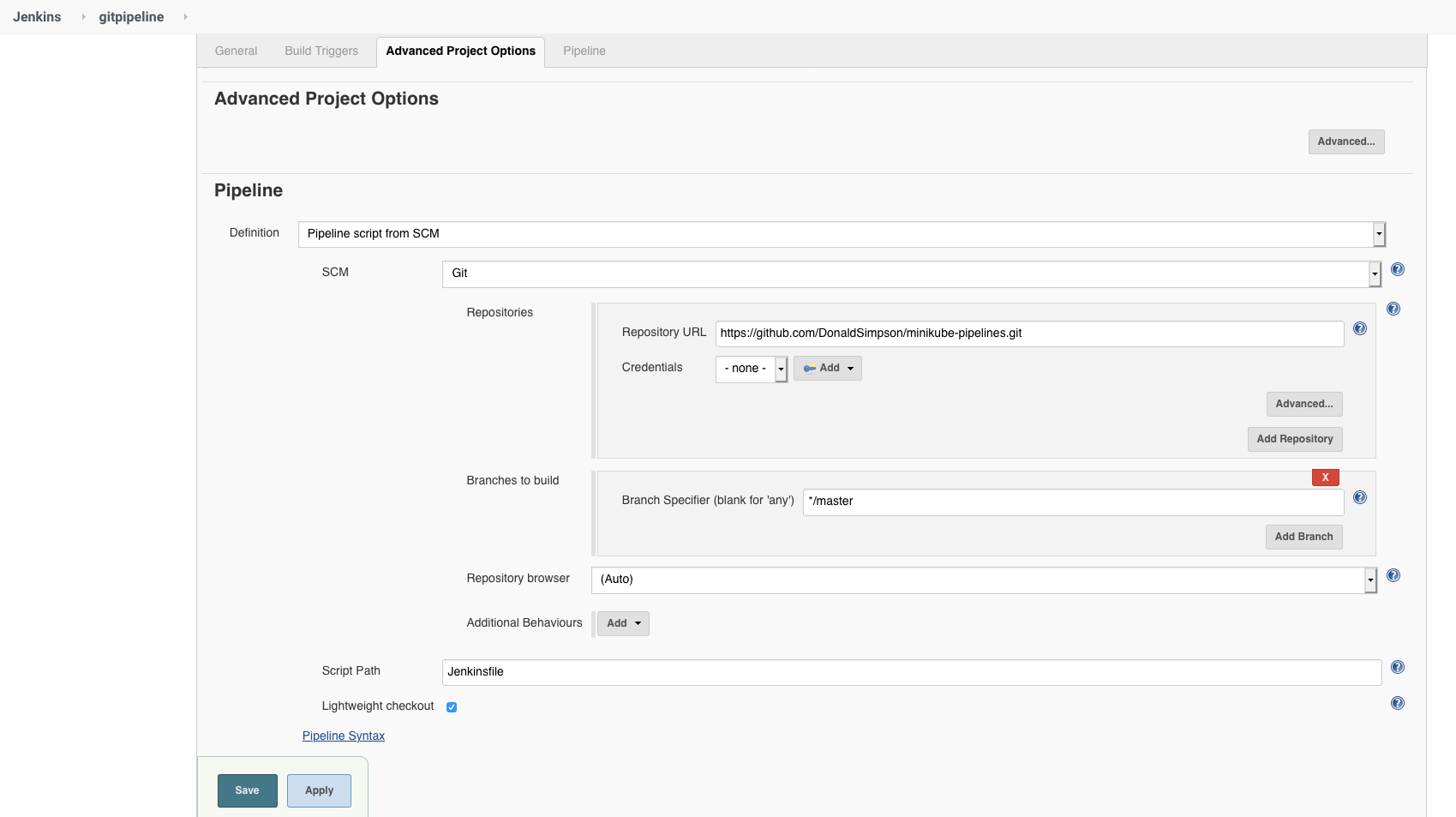
Create a new Jenkins Pipeline job and add the following settings as shown in the picture below…
In the job config page under “Pipeline”, for “Definition” select “Pipeline script from SCM” and enter the URL of this github project which contains my example pipeline code:
This file has been heavily commented to explain every part of the pipeline and shows what each step is doing. Taking a read through it should show you how pipelines work, how Jenkins is creating Docker Containers for the different Stages, and give you some ideas on how you could develop this simple example further.
Run it and take a look at the results
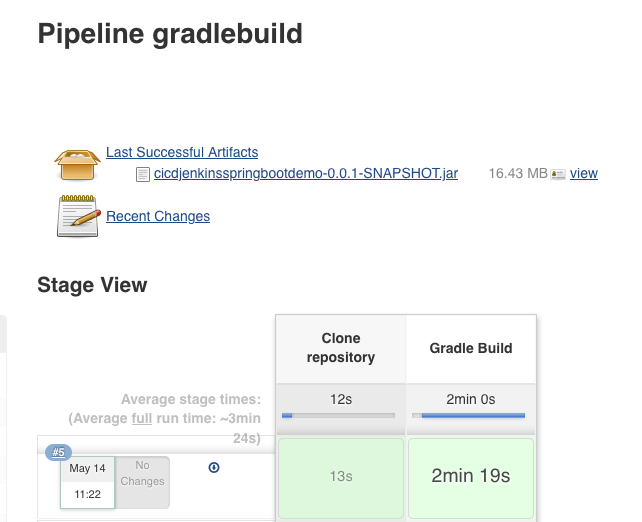
Save and run the job, and you should (eventually) see something like this:
The jobs Console Output will have a ton of info, showing everything from the container images being pulled, the git repo being cloned, the very verbose gradle build output and all the local files.
So in summary, what just happened?
Jenkins connected to Kubernetes via the Kubernetes plugin and its settings
A gradle Docker container was started and connected as a Jenkins JNLP Agent, running as another k8s pod
The gradle build stage was run inside that gradle container, using the source files checked out from git in the previous Stage
The newly built JAR file was archived so we could use it later if wanted
The pipeline ends, and k8s will clean up the containers
This pipeline could easily be expanded to run that new JAR file as an application as demonstrated here: https://github.com/AutomatedIT/springbootjenkinspipelinedemo/blob/master/Jenkinsfile#L5, or, you could build a new Docker image containing this version of the JAR file and start that up and test it and so on. You could also automate this so that whenever the source code is changed a build is triggered that does all of this automatically and records the result… hello CI/CD!
What next?
From the above demo you can hopefully see how easy it is to create an end to end pipeline that will automatically provision Jenkins Agents running on Kubernetes for you.
You can use this functionality to quickly and safely develop pipeline processes like the one we have examined, that run across multiple Agents, using each for a particular function/step in your workflow, leaving the provisioning and housekeeping work to the underlying Kubernetes cluster. With this, you can build or pull docker images, run them, test them, start them up as other Jenkins JNLP Agents and so on, all “as code” and all fully automated.
And after all that… ?
Being able to fire up Docker containers and use them as Jenkins Agents running on a Kubernetes platform is extremely powerful in itself, but you can go a step further and start using this setup to build, deploy and manage Kubernetes resources directly, too – from Jenkins Pipelines running on the same Kubernetes Cluster – or even from one Kubernetes to another.
We’ve seen during setup that we can use kubectl to manage the k8s cluster and its components – we can also do that from within containers and stages in our pipelines, wherever they are.
and contains an example pipeline and supporting files to build, lint, security scan, push to registry, deploy to Kubernetes, run, test and clean up the example “doncoin” application via a Jenkins pipeline running on Kubernetes.
It also includes outlines and suggestions for expanding things even further, in to a more mature and production-ready setup, introducing things like Jenkins shared libraries, linting and testing, automating vulnerability scanning within the pipeline, and so on.
This is a follow on to the previous writeup on Kubernetes with Minikube and shows how to quickly and easily get a Kubernetes cluster up and running using VirtualBox and Minikube.
The setup is very similar for all platforms, but this post is specifically focused on Mac, as I’m planning on using this as the basis for a more complex post on Jenkins & Kubernetes Pipelines (and that post is now posted, here!).
Installing required components
There are three main components required:
VirtualBox is a free and open source hypervisor. It is a light weight app that allows you to run Virtual Machines on most platforms (Mac, Windows, Linux). We will use it here to run the Minikube Virtual Machine.
Kubectl is a command line tool for controlling Kubernetes clusters, we install this on the host (Mac) and use it to control and interact with the Kubernetes cluster we will be running inside the Minikube VM.
Minikube is a tool that runs a single-node Kubernetes cluster in a virtual machine on your personal computer. We’re using this to provision our k8s cluster and will also take advantage of some of the developer friendly addons it offers.
Downloads and Instructions
Here are links to the required files and detailed instructions on setting each of these components up – I went for the ‘brew install‘ options but there are many alternatives in these links. The whole process is very simple and took about 10 minutes.
most popular hypervisors are well supported by Minikube.
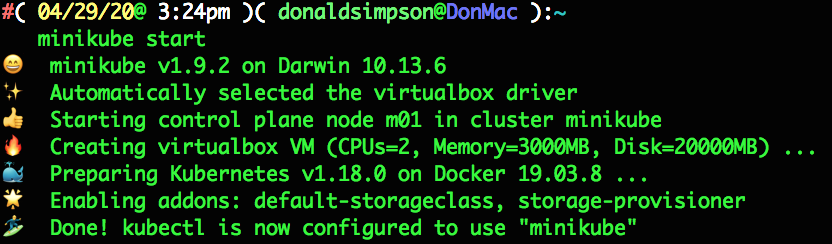
Here’s what that looks like on my Mac – this may take a few minutes as it’s downloading a VM (if not already available locally), starting it up and configuring a Kubernetes Cluster inside it:
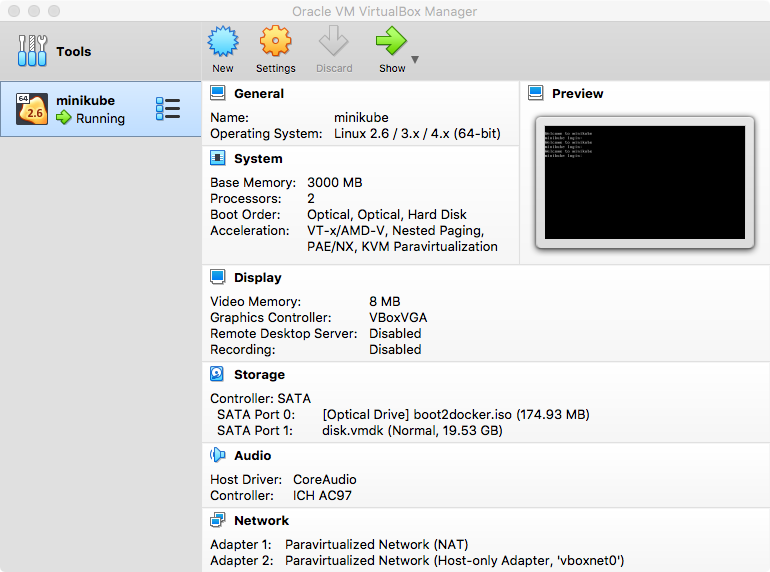
there’s quite a lot going on and not very much to see; you don’t even need to look at VirtualBox as it’s running ‘headless’, but if you open it up you can see the new running VM and its settings:
these values are all set to sensible defaults, but you may want to tweak things like memory or cpu allocations – running
minikube config -h
should help you see what to do, for example
minikube start --memory 1024
to change the allocated memory.
If you then take a look at the config file in ~/.minikube/config/config.js you will see how your preferences – resource limits, addons etc – are persisted and managed there.
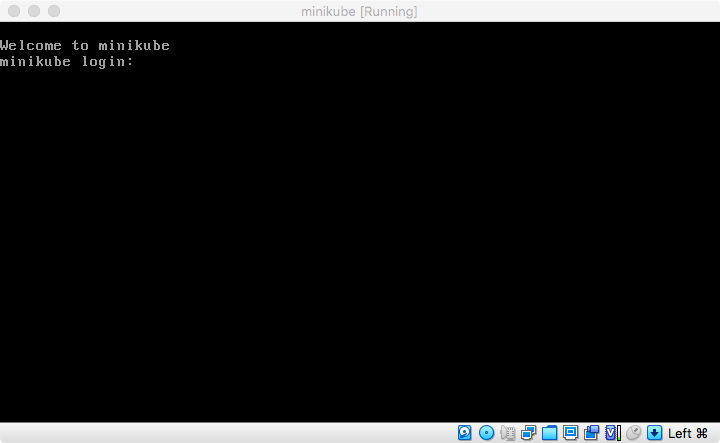
Looking back at VirtualBox, if you click on “Show” or the running VM you can open that up to see the console for the Minikube VM:
to stop the vm simply do a minikube stop, or just type minikube to see a list of args and options to manage the lifecycle, e.g. minikube delete, status, pause, ssh and so on.
Minikube Addons
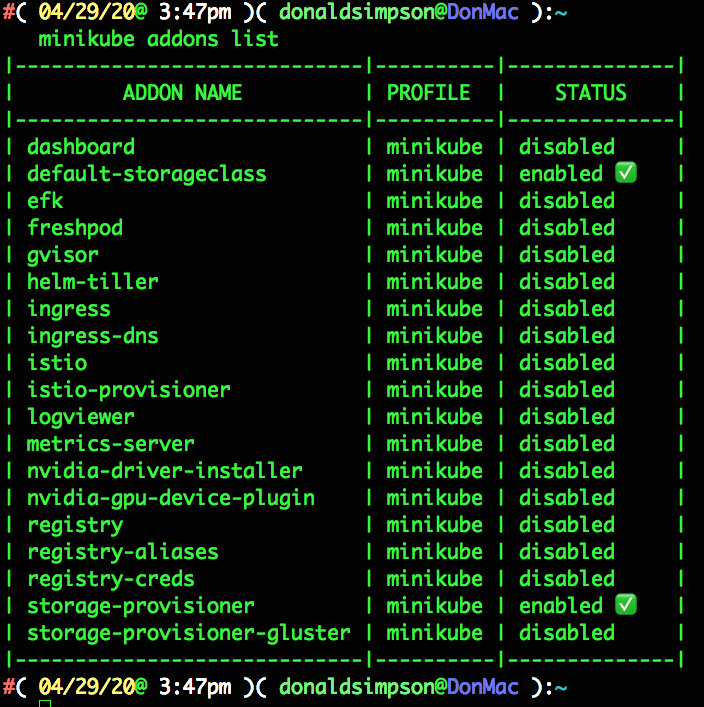
One of the handy features Minikube provides are its selection of easy to use addons. As explained in the official docs here you can see the list and current status of each addon by typing minikube addons list
the storage-provisioner and default-storeageclass addons were automatically enabled on startup, but I usually like to add the metrics server and dashboard too, like so:
I often use helm & tiller, efk, istio and the registry too – this feature save me a lot of time and messing about!
Accessing the Kubernetes Dashboard – all done!
Once that’s completed you can run minikube dashboard to open up the Kubernetes dashboard on your host.
Minikube makes this all very easy; we didn’t have to forward ports, configure firewalls, consider ingress and egress, create RBAC roles, manage accounts/passwords/keys or set up DNS, or any of the many things you would normally want or have to consider to get to this point.
These features make Minikube a great choice for development work, where you don’t want to care about things like this as you would in a “for real” environment.
Your browser should open up the Kubernetes Dashboard, and you can click around and see the status of the many components that comprise your new Kubernetes cluster:
And then…
Next up I’ll be building on this setup by deploying a Jenkins instance inside the Kubernetes Cluster, then configuring that to use Kubernetes to build, manage and deploy applications on the same Kubernetes Cluster.
Helm and Tiller – what they are, when & why you’d maybe use them
Helm and Tiller – prep, install and Helm Charts
Deploying Jenkins via Helm Charts
and WordPress w/MariaDB too
Wrap up
The below are mostly my technical notes from this session, with some added blurb/explanation.
Helm and Tiller – what they are, when & why you’d maybe use them
From the Helm site:
“Helm helps you manage Kubernetes applications — Helm Charts help you define, install, and upgrade even the most complex Kubernetes application. Charts are easy to create, version, share, and publish — so start using Helm and stop the copy-and-paste.”
Helm is basically a package manager for Kubernetes applications. You can choose from a large list of Stable (or not so!) ready made packages and use the Helm Charts to quickly and easily deploy them to your own Kubernetes Cluster.
This makes light work of some very complex deployment tasks, and it’s also possible to extend these ready-made charts to suit your needs, and to write your own Charts from scratch, or pass your own values to override default ones, or… many other interesting options!
For this session we are looking at installing Helm, reviewing some example Helm Charts and deploying a few “vanilla” ones to the cluster we created in the first half of the session. We also touch upon the life-cycle of Helm Charts – it’s similar to dockers – and point out some of the ways this could be extended and customised to suit your needs – more on this at a later date hopefully.
Helm and Tiller – prep, install and Helm Charts
First, installing Helm – it’s as easy as this, run on your laptop/host that’s running the Minikube k8s we setup earlier:
Tiller is the client part of Helm and is deployed inside your k8s cluster. It’s set to be removed with the release of Helm 3, but the basic functionality wont really change. More details here https://helm.sh/blog/helm-3-preview-pt1/
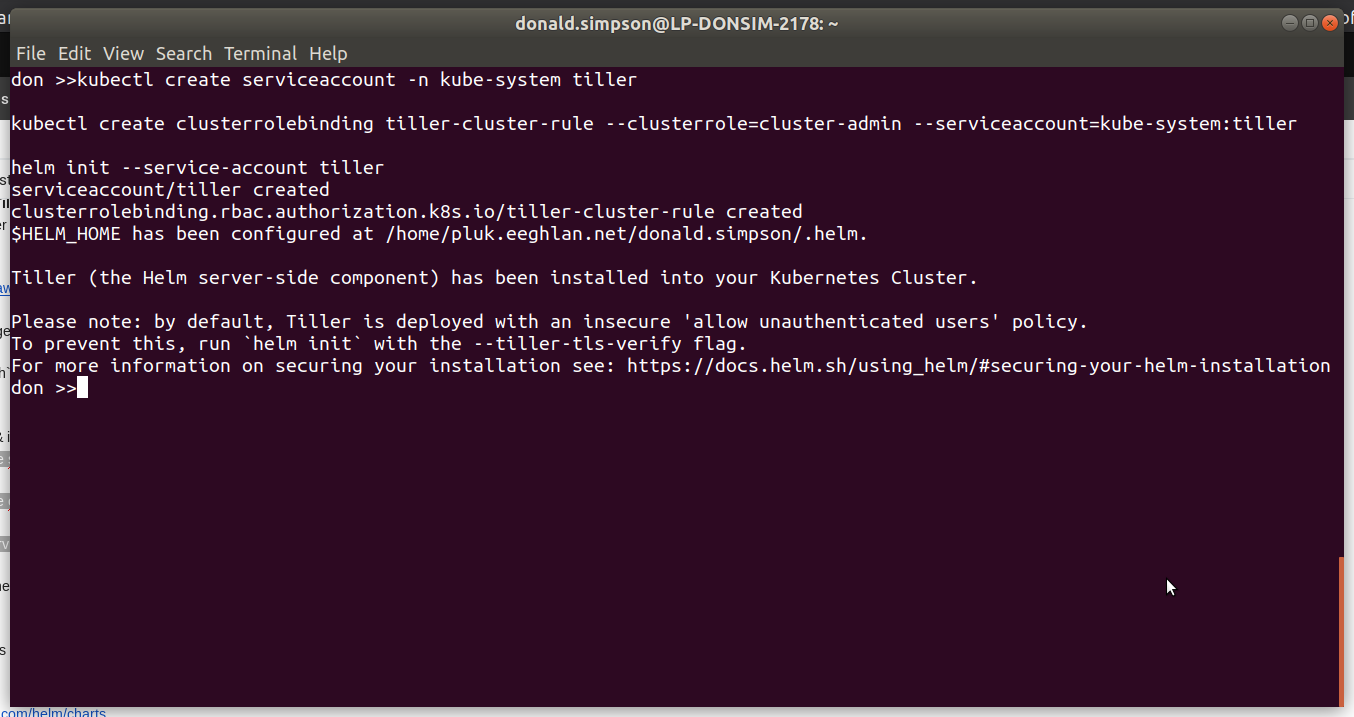
Next we do the Tiller prep & install – add RBAC for tiller, deploy via helm and take a look at the running pods:
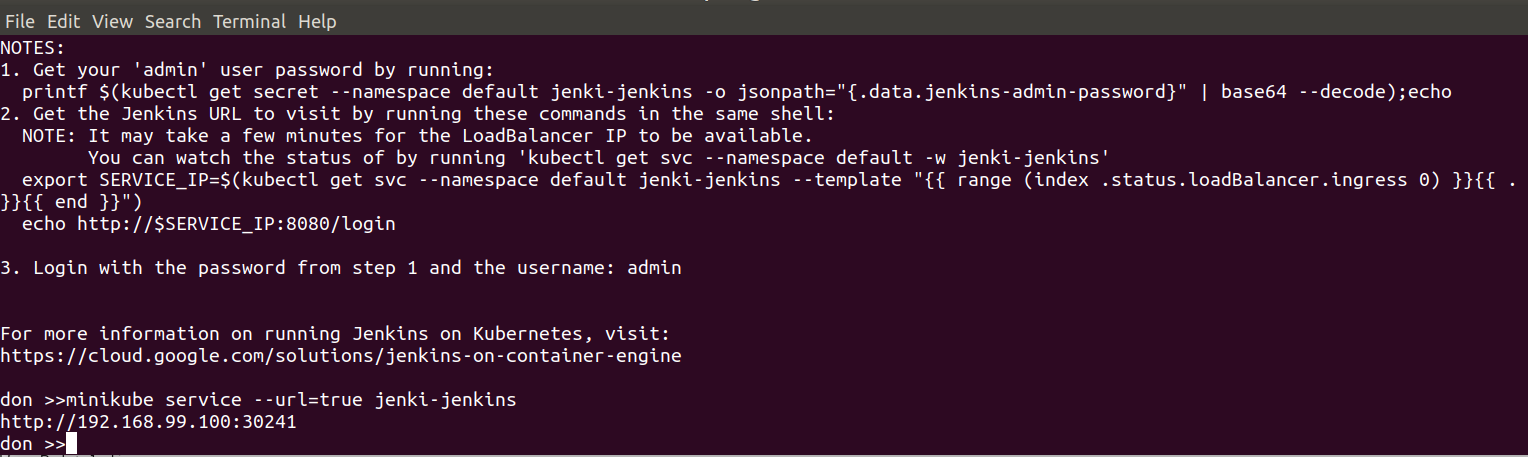
now get the URL for the Jenkins service from Minikube:
minikube service --url=true jenki-jenkins
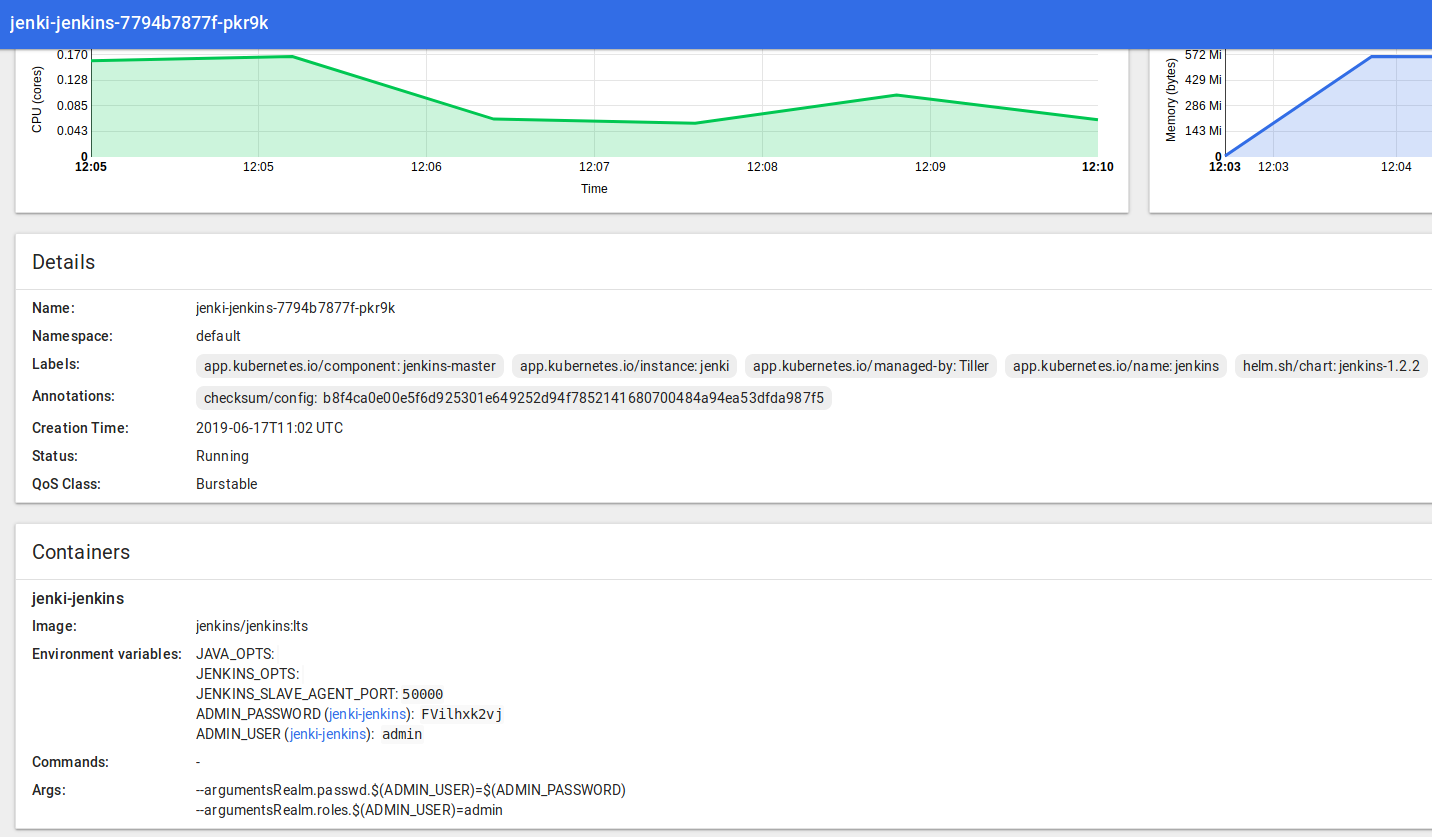
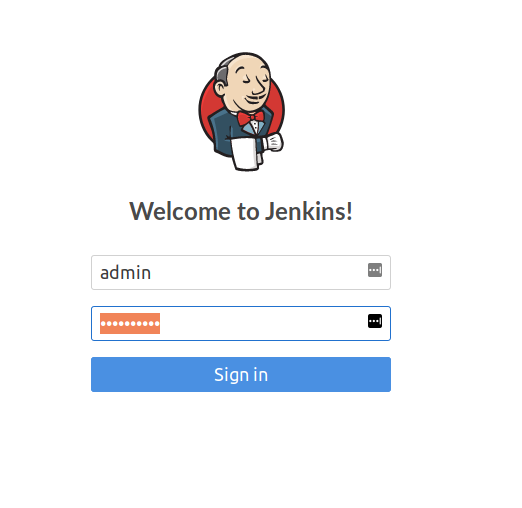
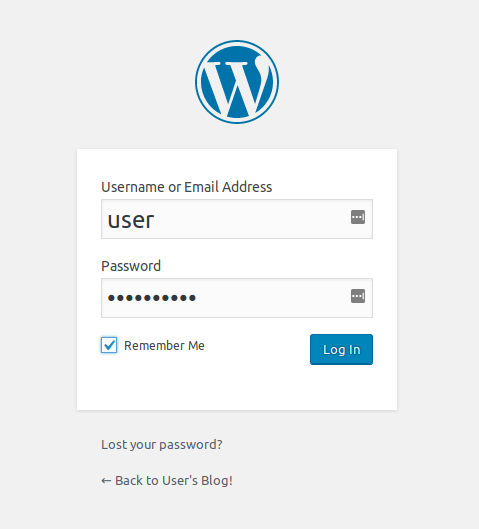
Hit that URL in your browser, and grab the password in UI from Pods > Jenki and log in to Jenkins with the user “admin”:
That’s a Jenkins instance deployed via Helm and Tiller and a Helm Chart to our Kubernetes Cluster running inside Minikube via a VirtualBox VM… all done in a few minutes. And it’s all customisable, repeatable, highly scaleable and awesome.
and WordPress w/MariaDB too
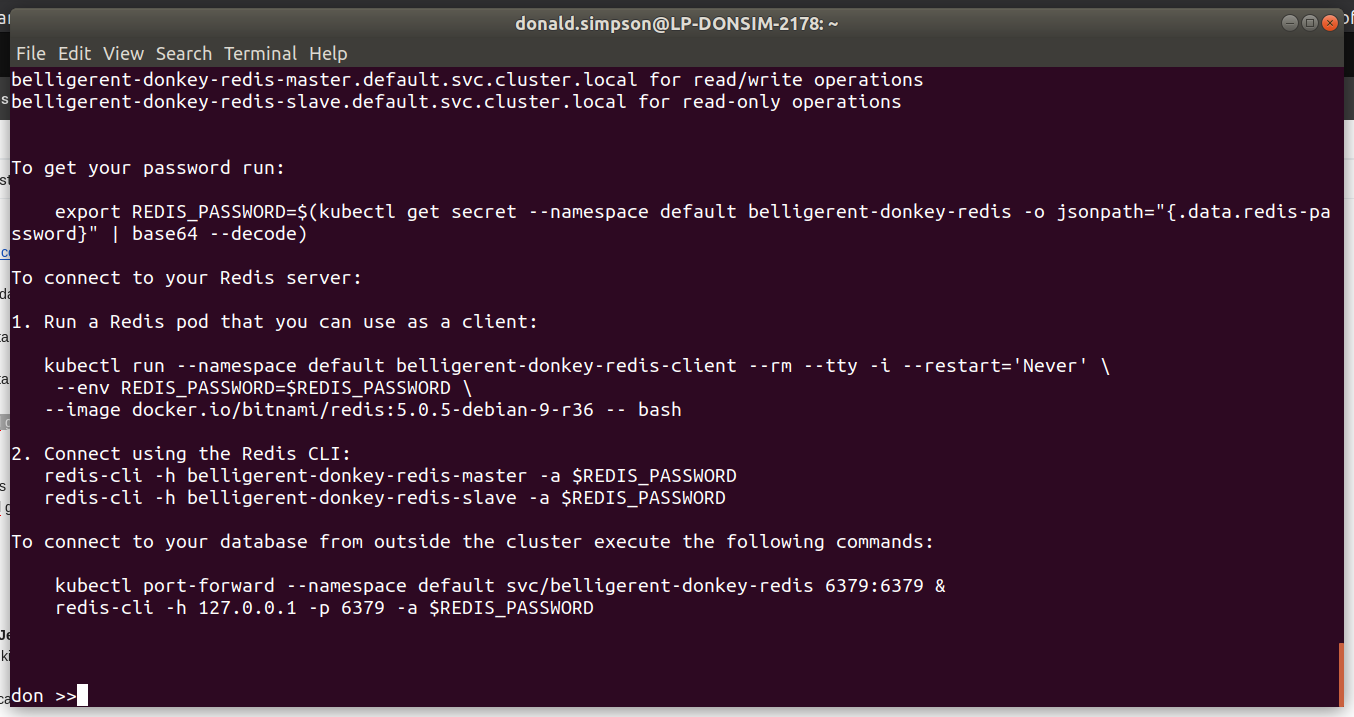
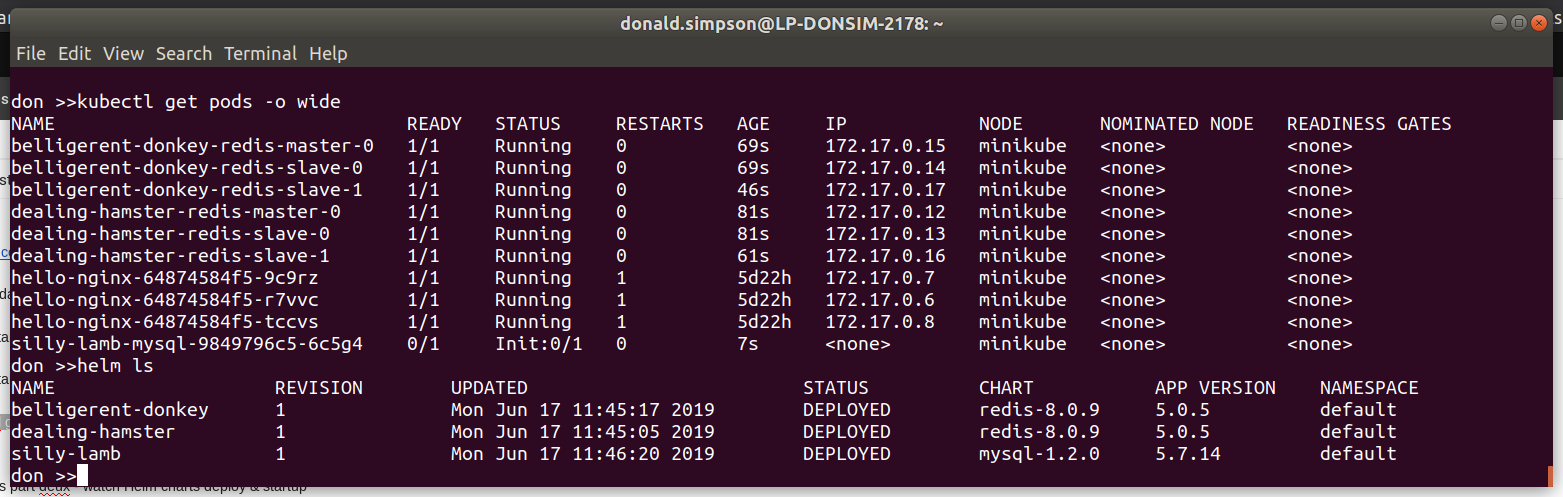
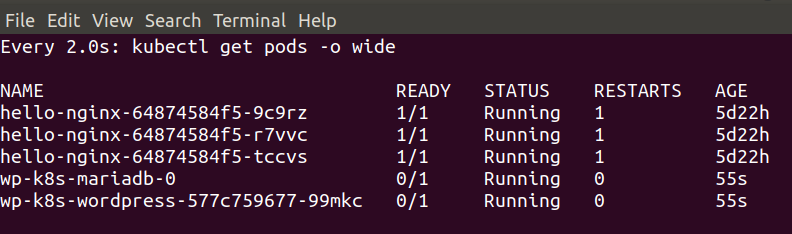
This was the “bonus demo” if my laptop wasn’t on fire – and thanks to some rapid cleaning up it managed fine – showing how quickly we could deploy a functional WordPress with MariaDB backend to our k8s cluster using the Helm Chart.
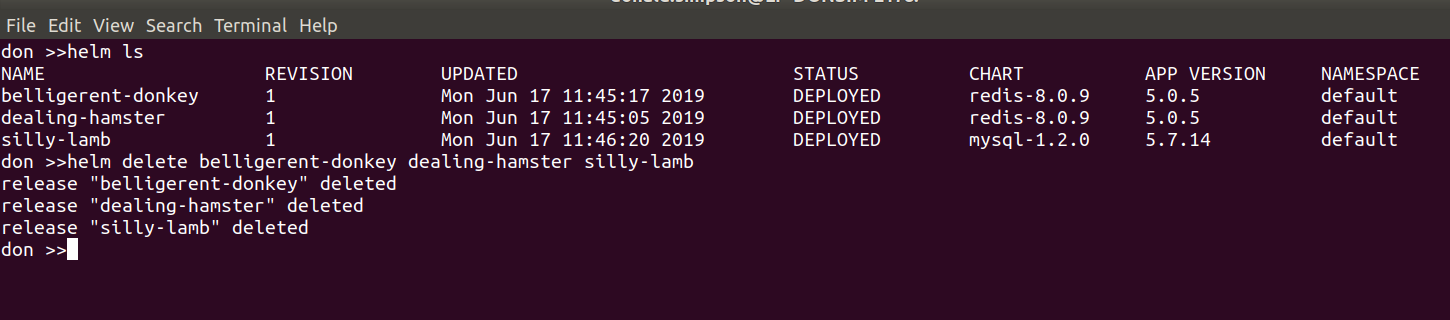
To prepare for this I did a helm ls to see all the things I had running. then helm delete --purge jenki, gave it a while to recover then had to do
kubectl delete pods <jenkinpod>
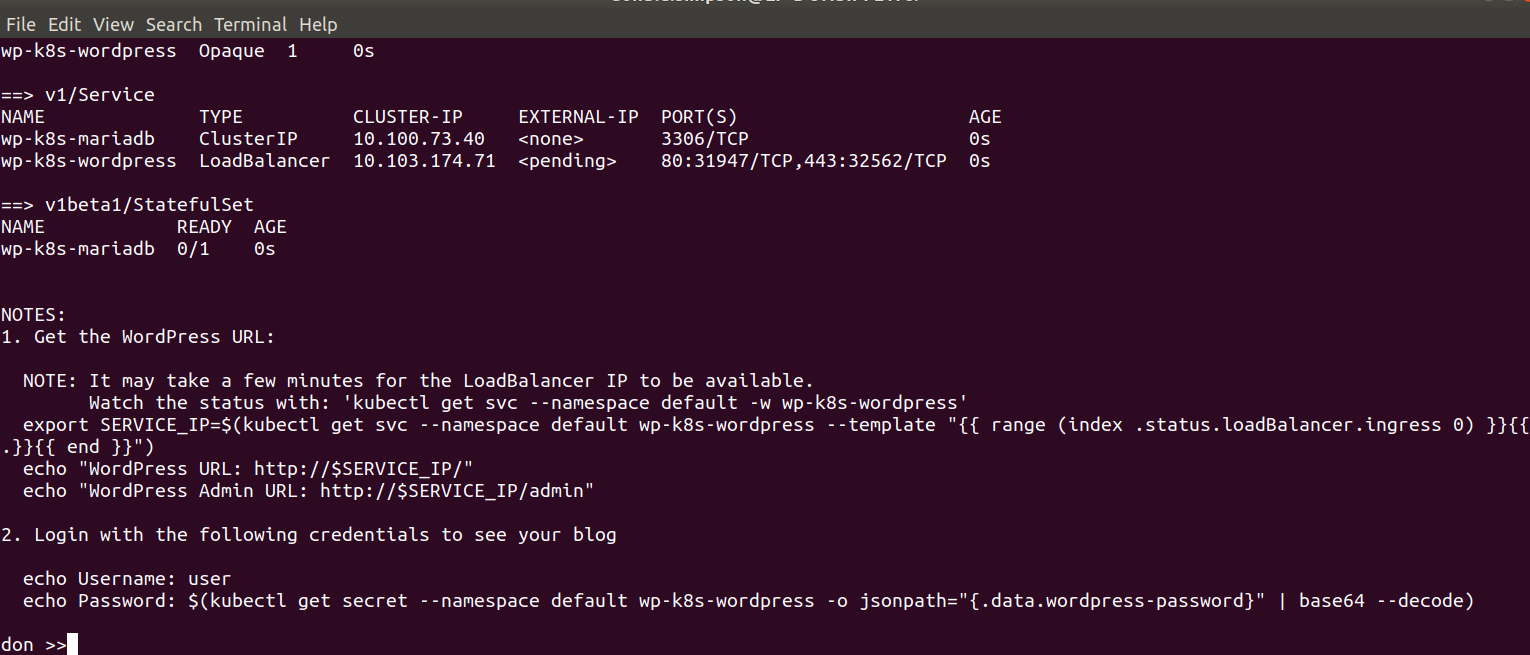
before starting the WordPress Chart deployment with
That’s it – we covered a lot in this session, and plan to use this as a platform to explore Helm in more detail later, writing our own Helm Charts and providing our own customisations to them.
Update: this follow-on post runs through setting up Jenkins with Helm then creating Jenkins Pipelines that dynamically provision dockerised Jenkins Agents:
This is the first of two posts on Kubernetes and HelmCharts, focusing on setting up a local development environment for Kubernetes using Minikube, then exploring Helm for package management and quickly and easily deploying several applications to the cluster – NGINX, Jenkins, WordPress with a MariaDB backend, MySQL and Redis.
The content is taken from the practical/demo session I wrote and published in Github here:
One of the key objectives and challenges here was getting a useful local Kubernetes environment up and running as quickly and easily as possible for as wide an audience as we could- there’s so much to the Kubernetes ecosystem that it’s very easy to get side-tracked, and we could have (happily) spent a long time discussing the myriad of alternative possible solutions.
We plan to go “deeper” on all of this in future sessions and have an in-depth Helm session in the works, but for this session we were focused on creating a practical starting point.
</ramble>
Don
What is covered here:
Minikube – what it is (& isn’t) & why you’d use it (or not)
Kubernetes and Minikube components and concepts
setup for Mac and Linux
creating a first Kubernetes cluster in Minikube
minikube addons – what they are and how they can help you
minikube docker env – using DOCKER_HOST with minikube VM
Kubernetes dashboard with Heapster and Metrics Server – made easy by Minikube
kubectl – some examples and alternatives
example app – “hello (Kubernetes) world” minikube style with NGINX, scaling your world
Helm and Tiller – what they are, when & why you’d maybe use them
Helm and Tiller – prep, install and Helm Charts
Deploying Jenkins via Helm Charts
and WordPress w/MariaDB too
wrap up
Minikube – what it is (& isn’t) & why you’d use it (or not)
What it is, why you’d use it etc.
Local development of k8s – runs a single node Kubernetes cluster in a Virtual Machine on your laptop/PC.
All about making things easy for local development, it is not a production solution, or even close to it.
There are many other ways to run k8s, they all have their pros and cons and use cases. The slides from the Meetup covered this in more detail and include links for further info – they are available here:
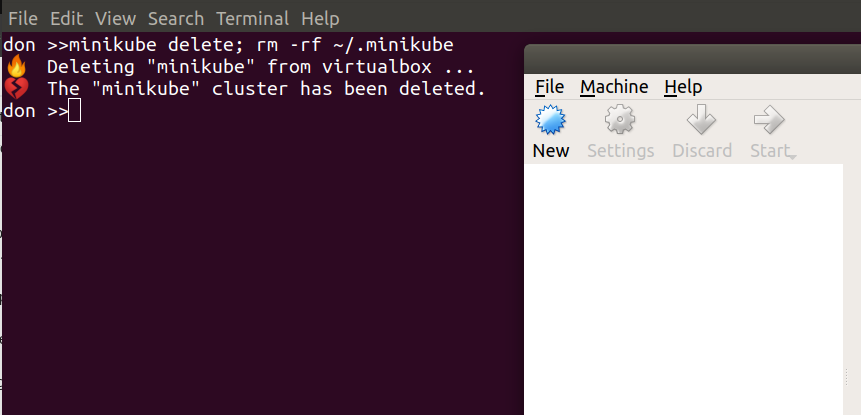
Cleanup/prep – if required, remove any previous cluster & settings
`minikube delete; rm -rf ~/.minikube`
Creating a first Kubernetes cluster in Minikube
Here we create a first Kubernetes cluster with Minikube, then take a look around in & outside of the VM.
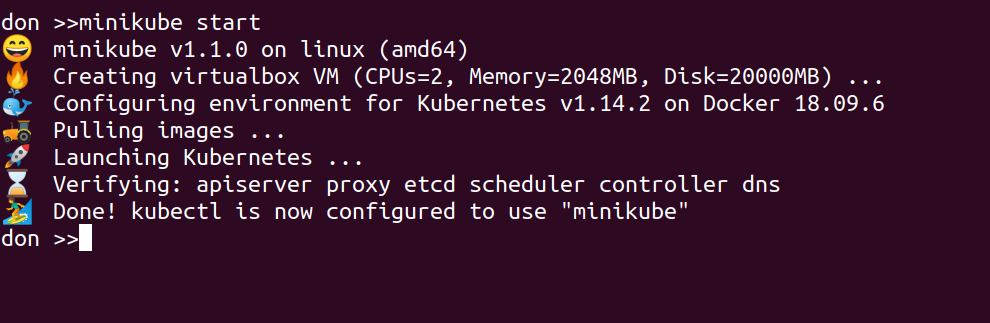
With the above initial setup done, it’s as simple as running this in a shell:
minikube start
Note you could optionally give this Cluster a name, if you are likely to have more than one for different branches of development for example. This is also where you could specify the VM provider if you want to use something other than VirtualBox – there are more details here:
This should produce output like the following, and it may well take a few minutes as the VM is downloaded and started, then a stack of Docker images are started up inside that….
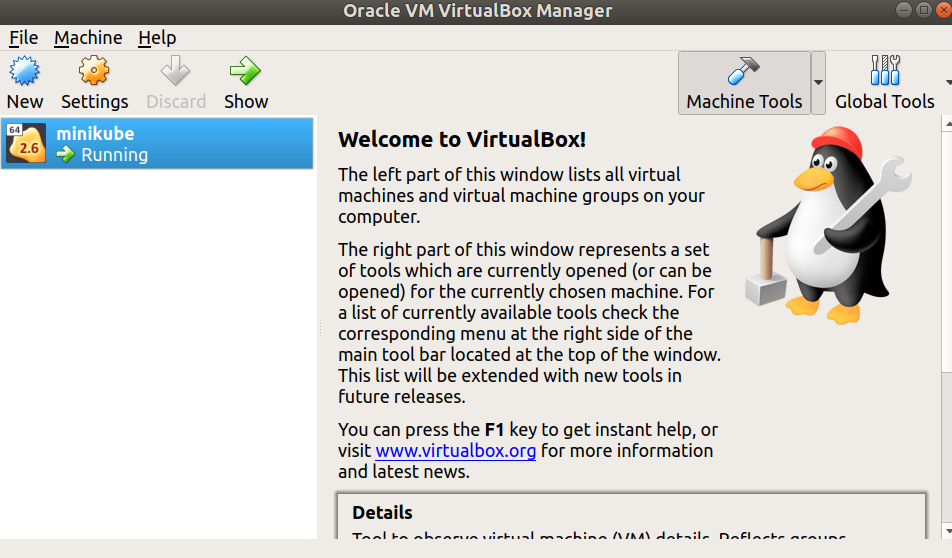
At this point you should be able to see the minikube VM running in the VirtualBox GUI:
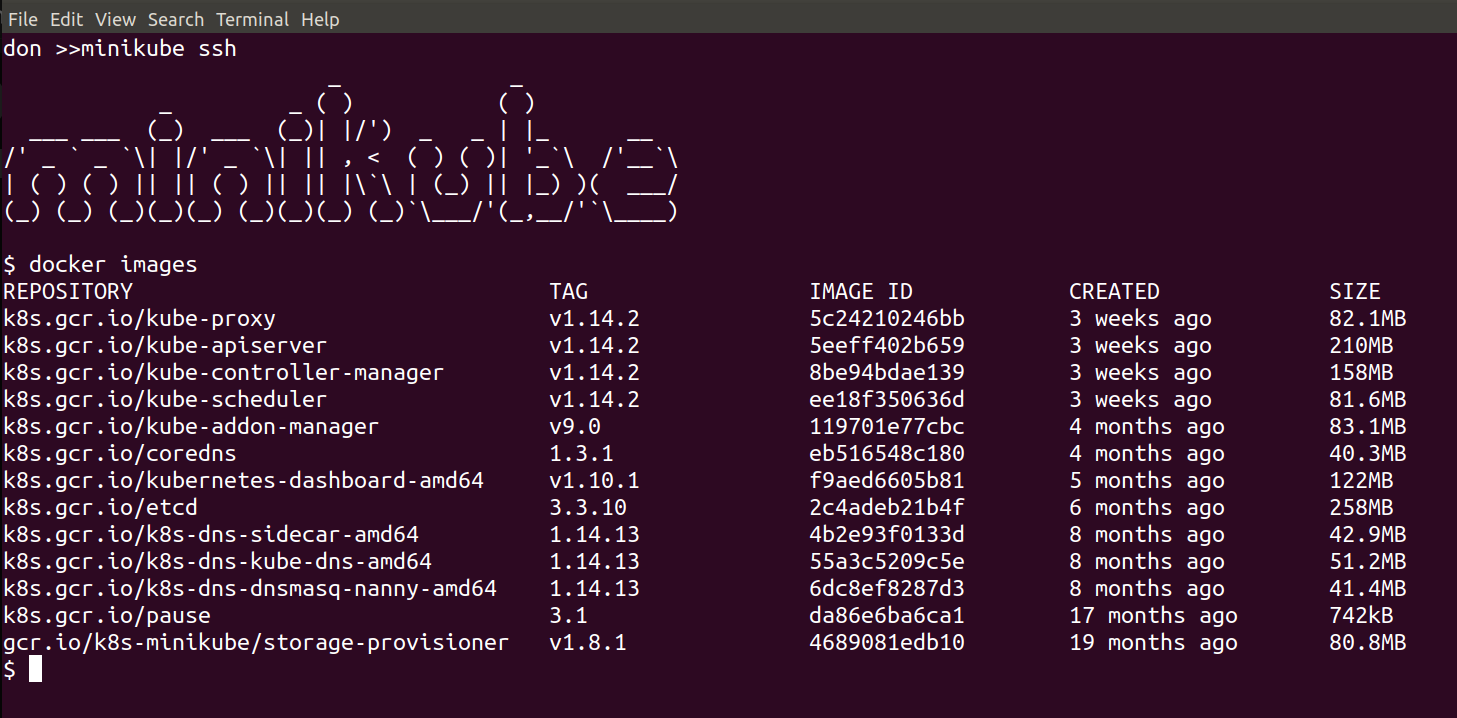
Now it’s running, we can connect from our local shell directly to the one inside the running VM by simply issuing:
minikube ssh
This will put you inside the VM where the Kubernetes Cluster is being run, and we can see and interact with the running components, for example:
docker images
should show all of the downloaded images:
and you could do this to see the running containers:
docker ps
Quitting out of the VM puts us back on the local host, where we can use kubectl to query the status of the Minikube cluster – the initial setup has told kubectl about the Minikube-managed Kubernetes Cluster, meaning there’s no other setup required here:
kubectl cluster-info
kubectl get nodes
kubectl describe nodes
minikube addons – what they are and how they can help you
Show some of the ways minkube makes things easier for local dev
First, take a moment to look around these two local folders:
ls -al ~/.minikube; ls -al ~/.kube
These are where Minikube keeps its settings and the VM Image, and where kubectl settings are persisted – and updated by Minikube.
With Minikube you’ve often got the option to either use kubectl directly, or to use some Minikube built-in features to make your life easier.
Addons are one of these features, allowing you to very easily add – or remove – functionality from the cluster like this:
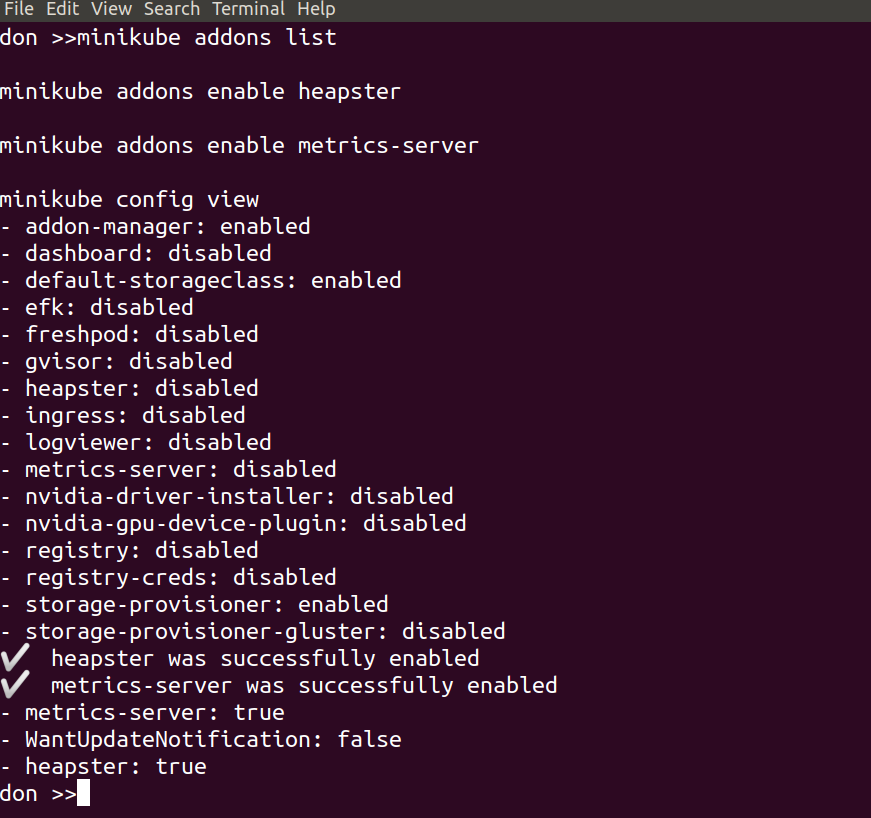
minikube addons list
minikube addons enable heapster
minikube addons enable metrics-server
With those three lines we’ve taken a look at the available addons and their current status, and selected to enable both heapster and the metrics server. This was done to give us cpu and mem stats in the Kubernetes Dashboard, which we will set up in a moment. The output should look something like this:
minikube config view
shows the current state of the config – i.e. what changes have been made, so we can keep a track of them easily.
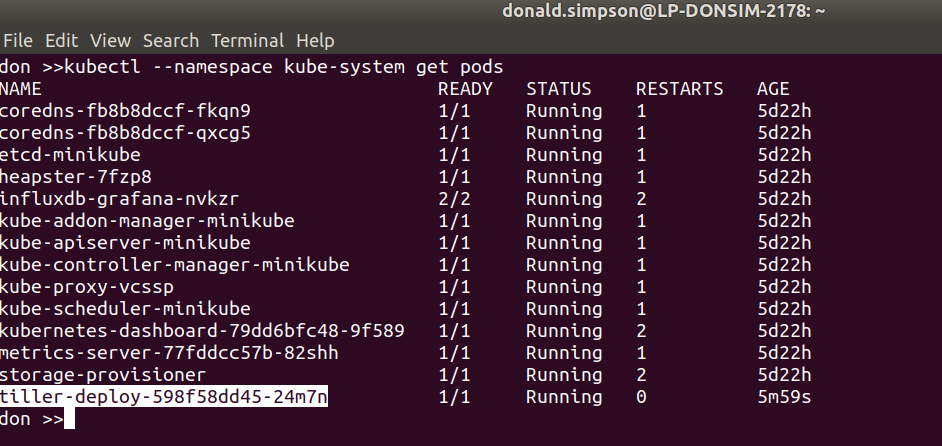
kubectl --namespace kube-system get pods
now we can enable the dashboard:
minikube addons enable dashboard
and check again to see the current state
minikube addons list
we’ll connect to the Dashboard and take a look around in a moment, but first…
minikube docker env – using the DOCKER_HOST in you minikube VM – how & why
Minikube docker-env – setup local docker client to use minikube docker host
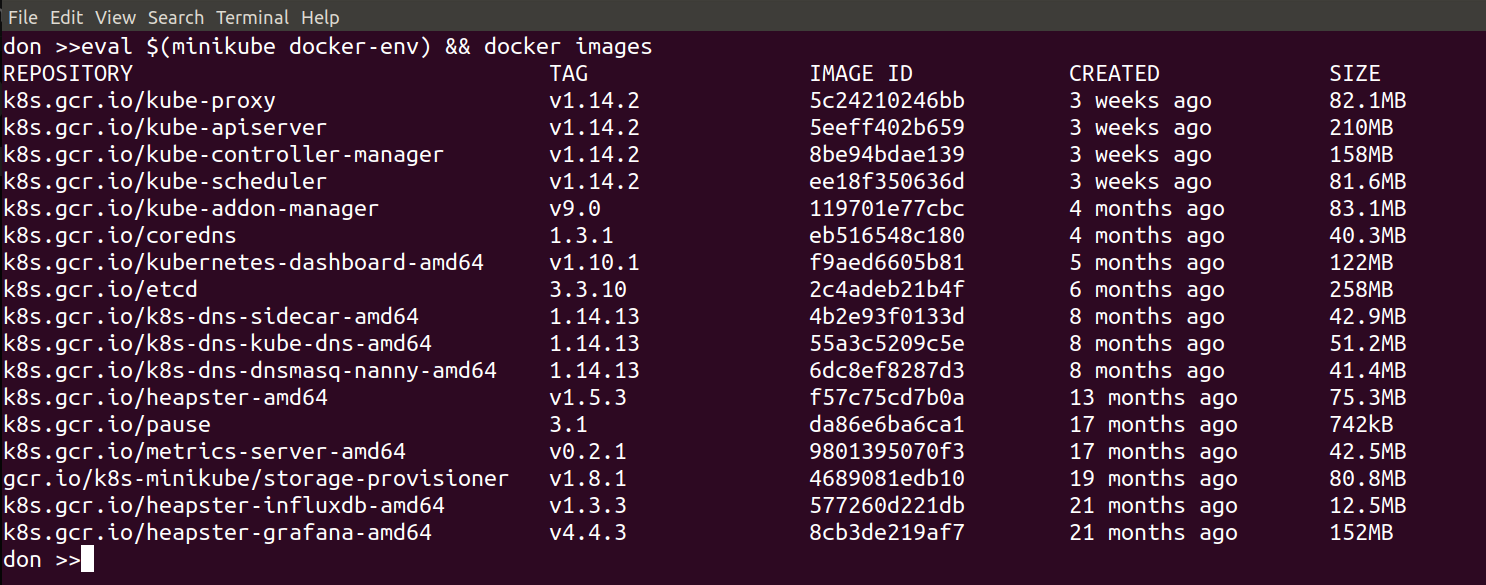
We’re going to look at connecting our local docker client to the docker host inside the Minikube VM. This is made easy by:
minikube docker-env
if you run that command on its own it wiull show you what settings it will export and you can set them by doing:
eval ${minikube docker-env}
From then on, in that shell, your local docker commands will use the docker host inside Minikube.
This is very useful for debugging and local development – when you change and deploy anything to your Kubernetes Cluster, you can easily tail the logs or check for errors or issues. You can also do all of this via the dashboard or kubectl too if you prefer, but it’s another handy and powerful feature from Minikube.
The following image shows the result of running this command:
so we can now use our local docker client to run docker commands like…
docker ps
docker ps | grep -i metrics
docker logs -f <some container id>
etc.
Kubernetes dashboard with Heapster and Metrics Server – made easy by Minikube
Minikube k8s dashboard – here we will start up the k8s dashboard and take look around.
We’ve delayed starting the dashboard up until after we enabled the metrics-server & heapster components we deployed earlier. By doing it in this order, the dashboard will automatically detect and use these components, giving us cpu & mem stats and a nicer looking dash, with no additional config required.
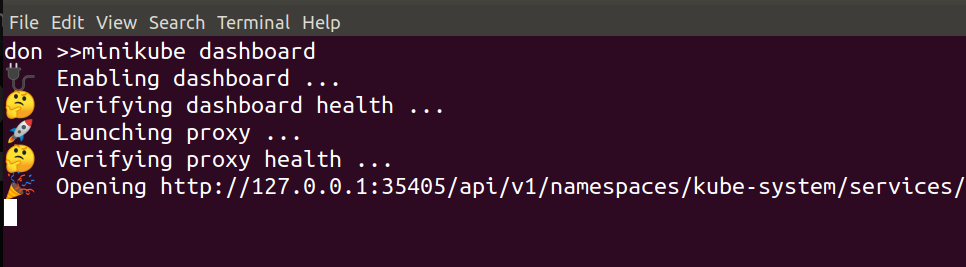
Starting the dashboard simply involved running
minikube dashboard
and waiting for a minute…
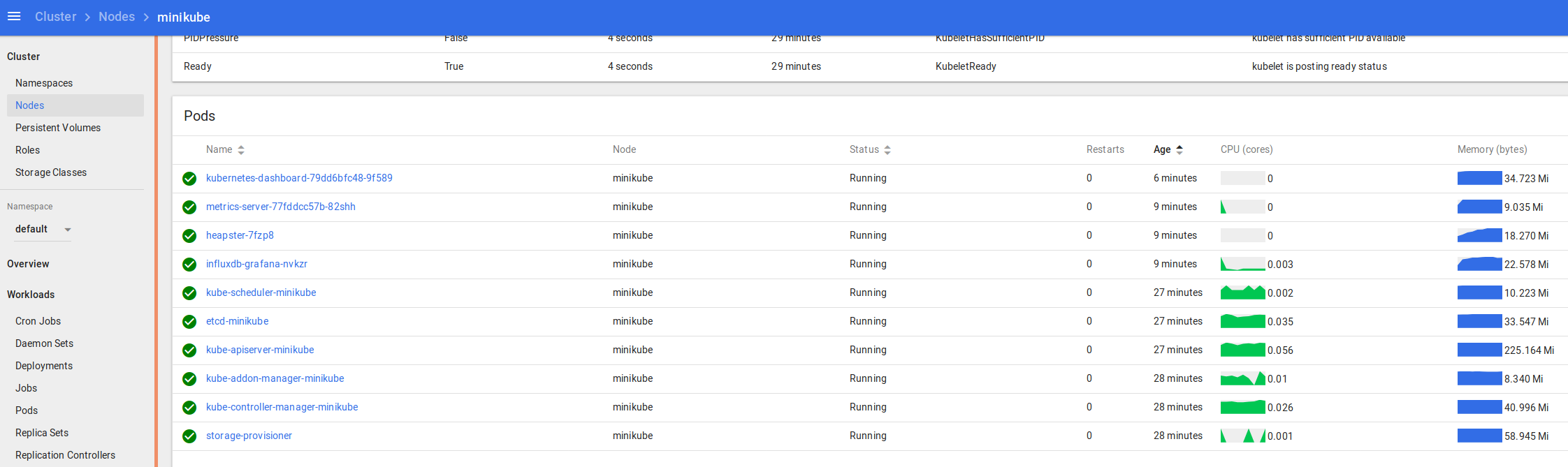
That should fire up your browser automatically, then you can take a look around at things like Default namespace > Nodes
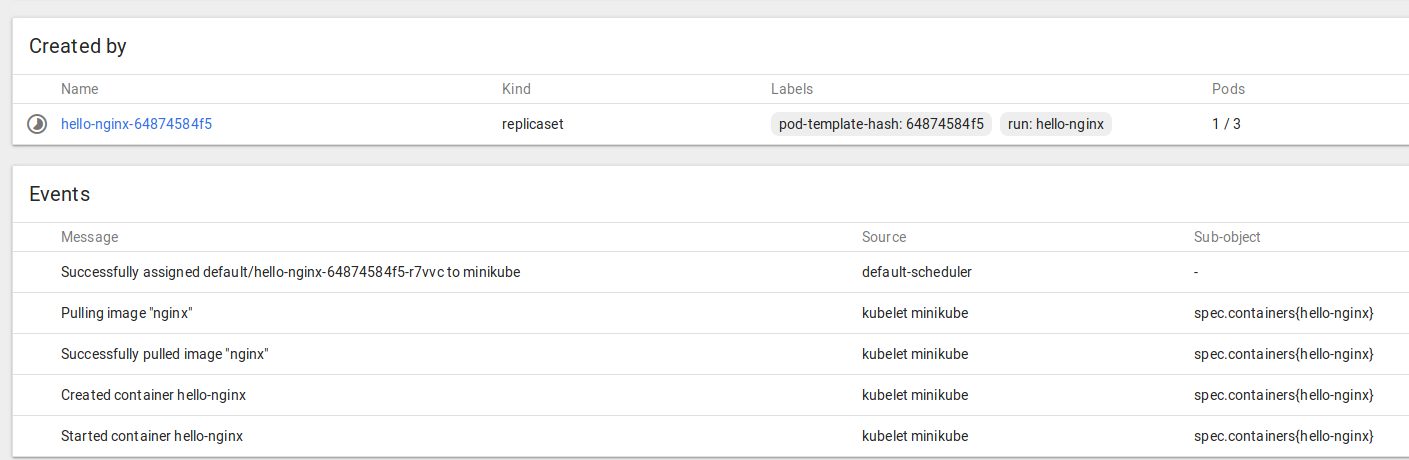
and in the namespace kube-system > Deployments
and kube-system > Pods
You can see the logs and statuses of everything running in your k8s cluster – from the core components we covered at the start, to the dashboard, metrics and heapster we enabled recently, and the application we’re going to deploy and scale up soon.
kubectl – some examples and alternatives
# kubectl command line – look at kubectl and keep an eye on things kubectl get deployment -n kube-system
kubectl get pods -o wide -n kube-system
kubectl get services
kubectl
example app – “hello (Kubernetes) world” minikube style with NGINX, scaling your world
Now we’ll deploy the most basic application we can – a “Hello World” style NGINX docker image.
It’s as simple as this, where nginx is the name of the docker image you want to deploy, hello-nginx is the label you want to give it, and port 80 is where you want it to listen:
kubectl run hello-nginx --image=nginx --port=80
that shouldn’t take long, and you can watch the progress like this:









 And here’s what it looks like on my Proxmox host:
And here’s what it looks like on my Proxmox host: