
Introduction
This post takes a look at setting up monitoring and alerting in Kubernetes, using Helm and Kubernetes Operators to deploy and configure Prometheus and Grafana.
This platform is quickly and easily deployed to the cluster using a Helm Chart, which in turn uses a Kubernetes Operator, to setup all of the required resources in an existing Kubernetes Cluster.
I’m re-using the Minikube Kubernetes cluster with Helm that was built and described in previous posts here and here, but the same steps should work for any working Kubernetes & Helm setup.
An example Grafana Dashboard for Kubernetes monitoring is then imported and we take a quick look at monitoring of Cluster components with other dashboards
Kubernetes Operators & Helm combo
K8s Operators are described ‘in plain English’ here:
https://enterprisersproject.com/article/2019/2/kubernetes-operators-plain-english
and defined by CoreOS as “a method of packaging, deploying and managing a Kubernetes application“
The Operator used in this post can be seen here:
https://github.com/coreos/prometheus-operator
and this is deployed to the Cluster using this Helm Chart:
https://github.com/helm/charts/tree/master/stable/prometheus-operator
It may sound like Helm and Operators do much the same thing, but they are different and complimentary
Helm and Operators are complementary technologies. Helm is geared towards performing day-1 operations of templatization and deployment of Kubernetes YAMLs — in this case Operator deployment. Operator is geared towards handling day-2 operations of managing application workloads on Kubernetes.
from https://medium.com/@cloudark/kubernetes-operators-and-helm-it-takes-two-to-tango-3ff6dcf65619
Let’s get (re)started
I’m reusing the Minikube cluster from previous posts, so start it back up with:
minikube start
which outputs the following in the console
🎉 minikube 1.10.1 is available! Download it: https://github.com/kubernetes/minikube/releases/tag/v1.10.1
💡 To disable this notice, run: ‘minikube config set WantUpdateNotification false’🙄 minikube v1.9.2 on Darwin 10.13.6
✨ Using the virtualbox driver based on existing profile
👍 Starting control plane node m01 in cluster minikube
🔄 Restarting existing virtualbox VM for “minikube” …
🐳 Preparing Kubernetes v1.18.0 on Docker 19.03.8 …
🌟 Enabling addons: dashboard, default-storageclass, helm-tiller, metrics-server, storage-provisioner
🏄 Done! kubectl is now configured to use “minikube”
this all looks ok, and includes the minikube addons I’d selected previously.
Now a quick check to make sure my local helm repo is up to date:
helm repo update
I then used this command to find the latest version of the stable prometheus-operator via a helm search:helm search stable/prometheus-operator --versions | head -2
there’s no doubt a neater/builtin way to find out the latest version, but this did the job – I’m going to install 8.13.8:
install the prometheus operator using Helm, in to a new dedicated “monitoring” namespace just takes this one command:helm install stable/prometheus-operator --version=8.13.8 --name=monitoring --namespace=monitoring
Ooops
that should normally be it, but for me, this resulted in some issues along these lines:
Error: Get http://localhost:8080/version?timeout=32s: dial tcp 127.0.0.1:8080: connect: connection refused
– looks like Helm can’t communicate with Tiller any more; I confirmed this with a simple helm ls which also failed with the same message. This shouldn’t be a problem when v3 of Helm goes “tillerless”, but to fix this quickly I simply re-enabled Tiller in my cluster via Minikube Addons:
➞ minikube addons disable helm-tiller
➞ minikube addons enable helm-tiller
verified things worked again with helm ls, then the helm install... command worked and started to do its thing…
New Operator and Namespace
Keeping an eye on progress in my k8s dashboard, I can see the new “monitoring” namespace has been created, and the various Operator components are being downloaded, started up and configured:
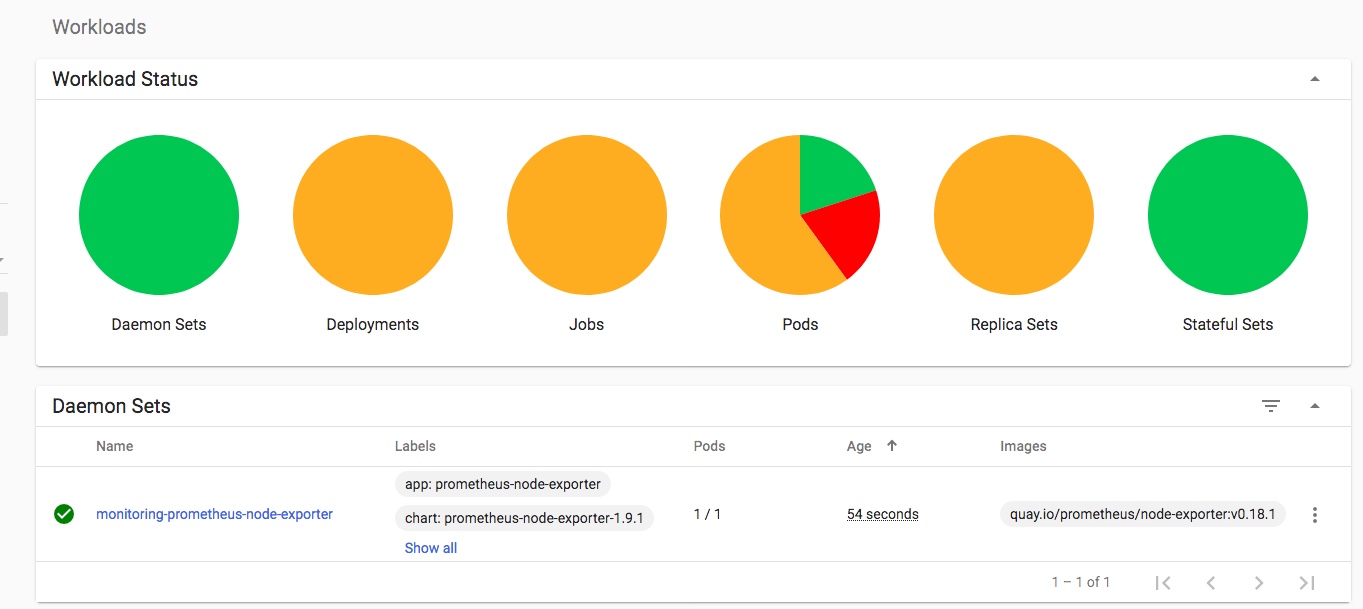
you can also keep an eye on progress with:watch -d kubectl get po --namespace=monitoring
this takes a while on my machine, but eventually completes with this console output:
NOTES:
The Prometheus Operator has been installed. Check its status by running:
kubectl –namespace monitoring get pods -l “release=monitoring”Visit https://github.com/coreos/prometheus-operator for instructions on how
to create & configure Alertmanager and Prometheus instances using the Operator.
kubectl get po --namespace=monitoring shows the pods now running in the cluster, and for this quick example the easiest way to get access to the new Grafana instance is to forward the pods port 3000 to localhost like this:
➞ kubectl --namespace monitoring port-forward monitoring-grafana-64d4f6fcf7-t5zkv 3000:3000
(check and adjust the above to use the full/correct name of your monitoring-grafana-* pod)
Connecting to Grafana
now I can hit http://localhost:3000 and have that connect to port 3000 in the Grafana pod:

from the documentation on the Helm Chart and Operator here:
https://github.com/helm/charts/tree/master/stable/prometheus-operator
the default user for this Grafana is “admin” and the password for that user is “prom-operator“, so log in with those credentials…
Grafana Dashboards for Kubernetes
We can now use the ready-made Grafana dashboards, or add/import ones from the extensive online collection, like this one here for example: https://grafana.com/grafana/dashboards/6417 – simply save the JSON file
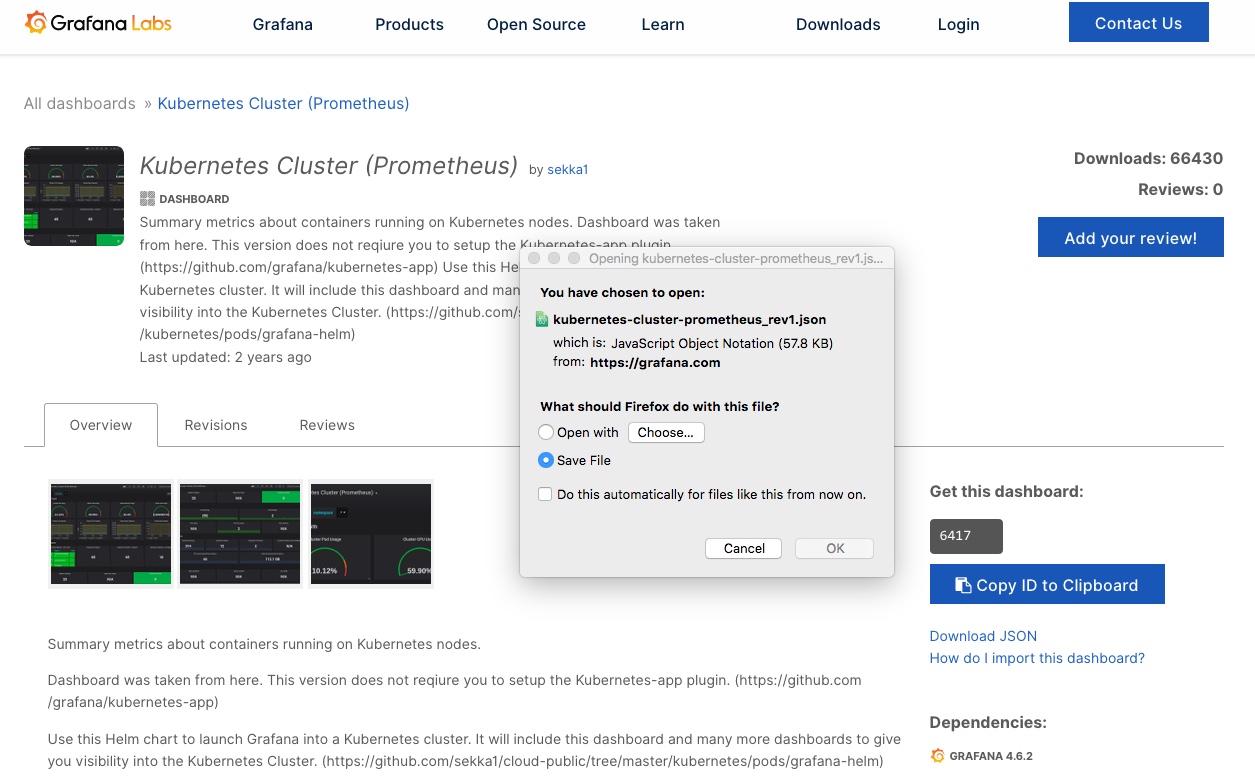
then go to Grafana and import it with these settings:
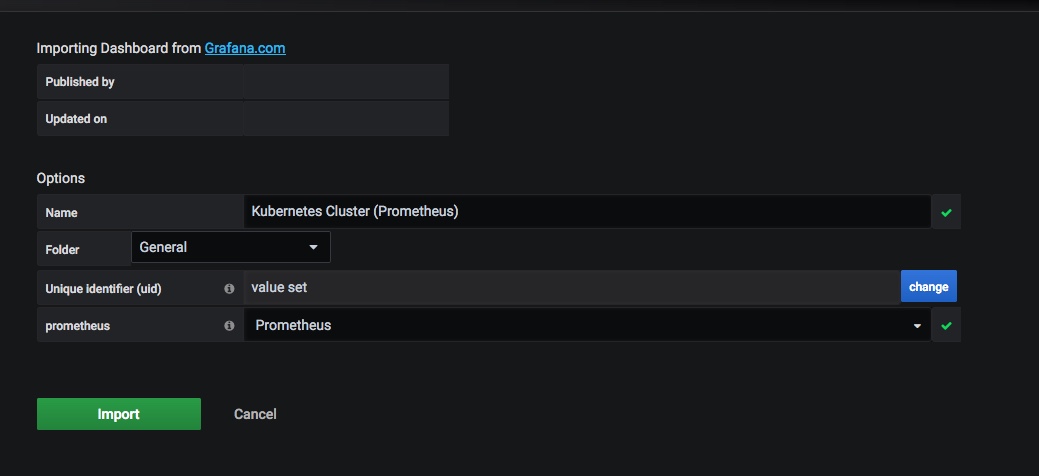
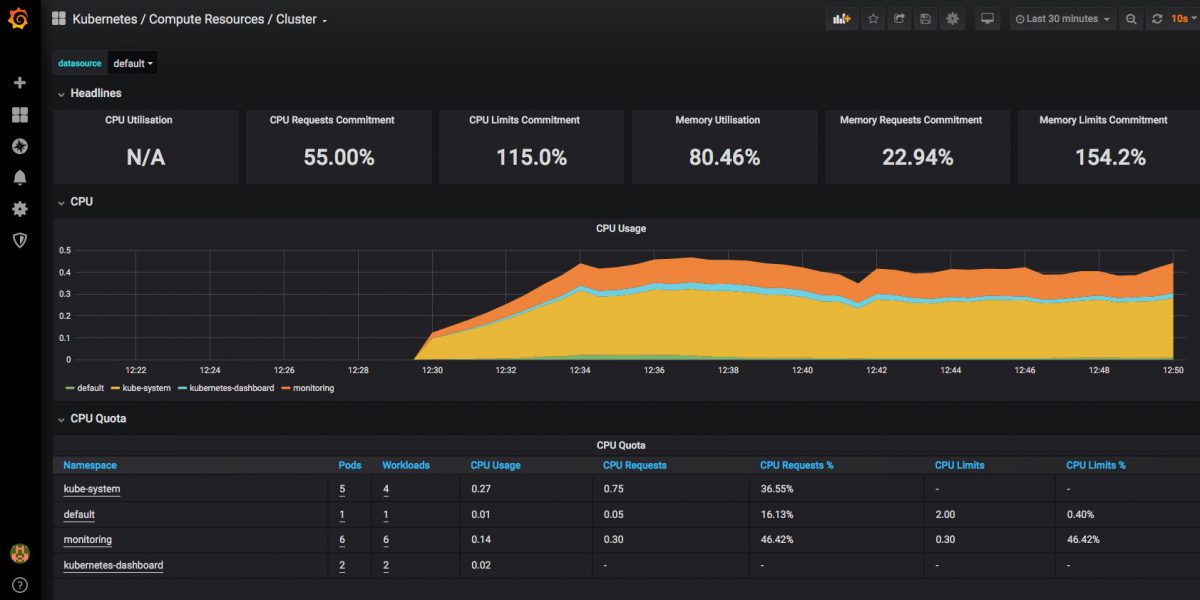
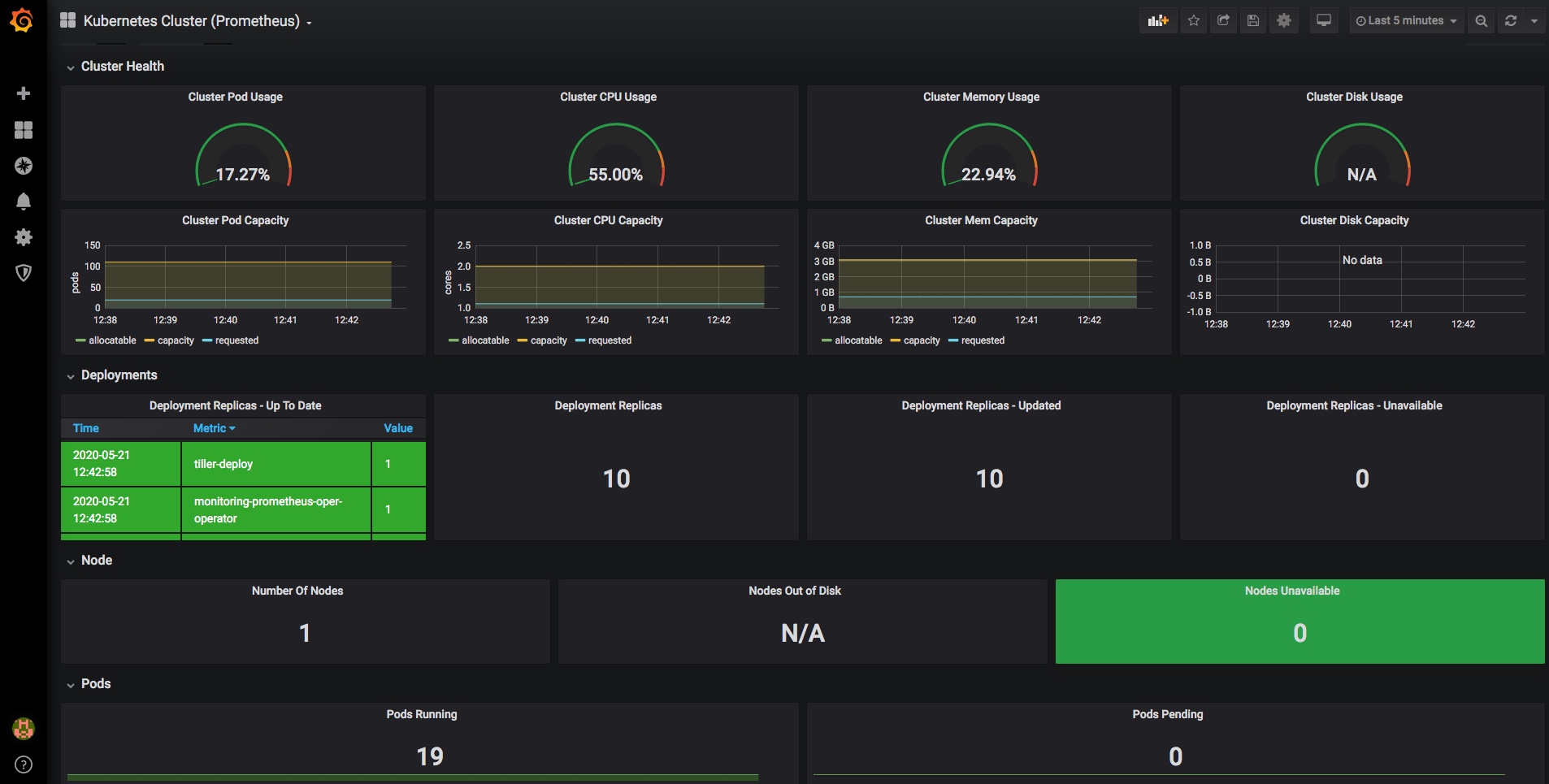
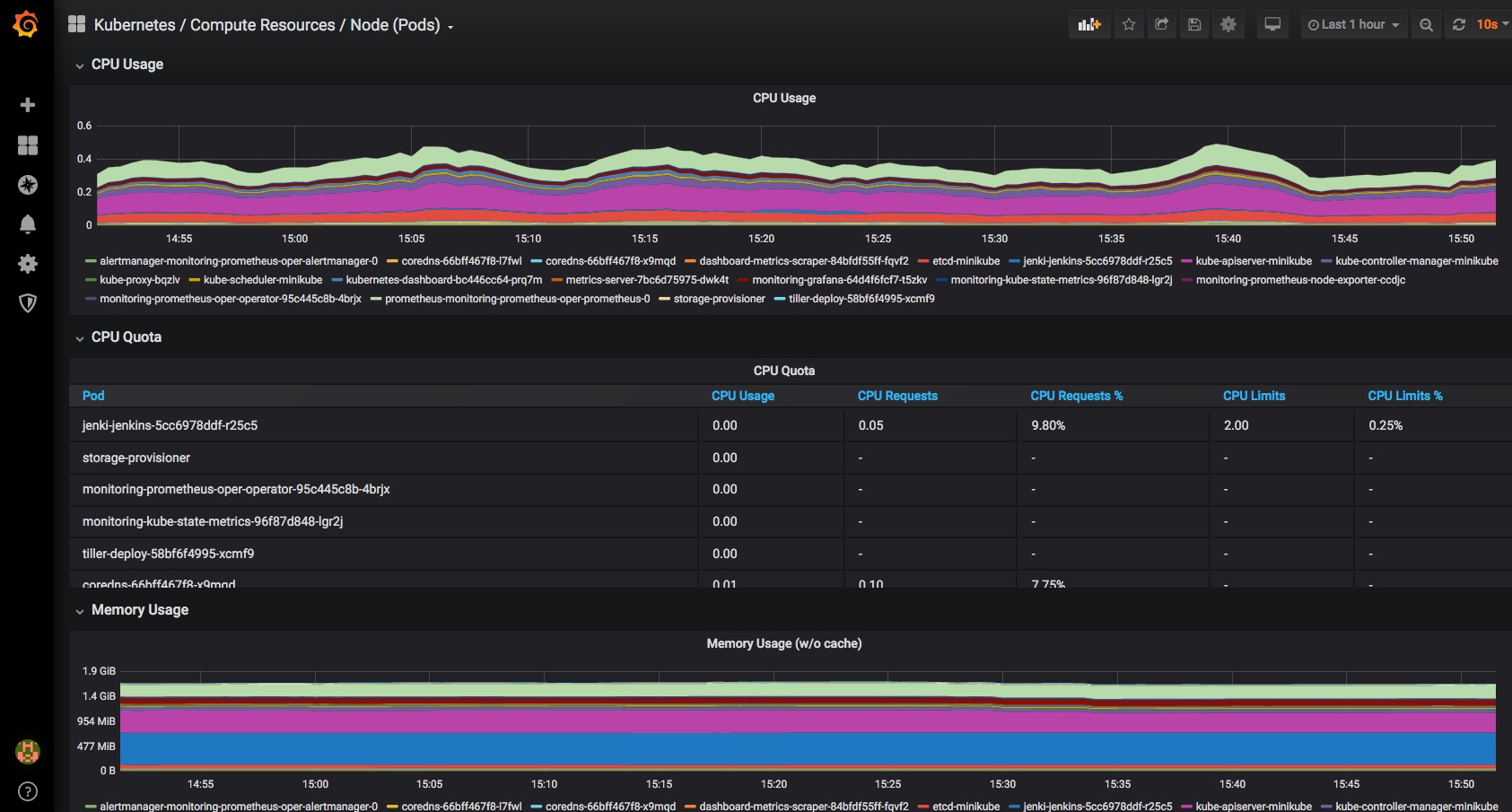
and you should now have a dashboard showing some pretty helpful stats on your kubernetes cluster, it’s health and resource usage:
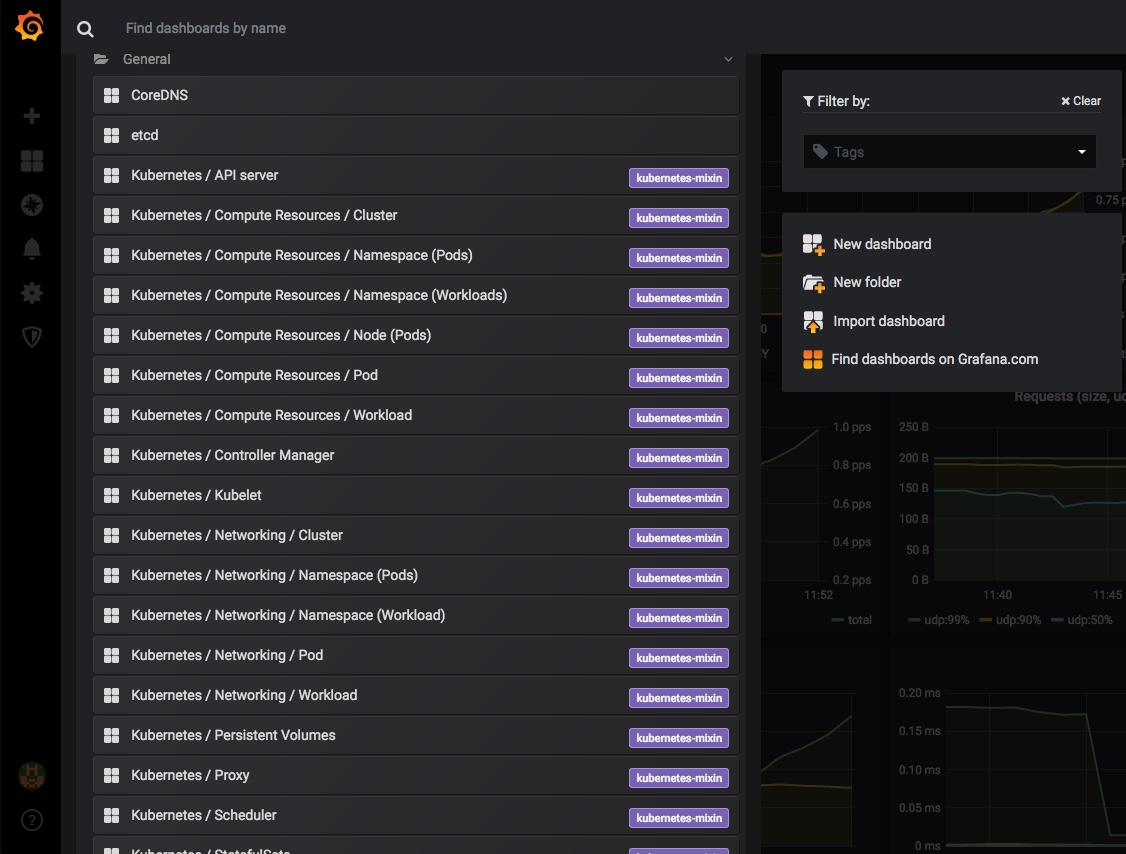
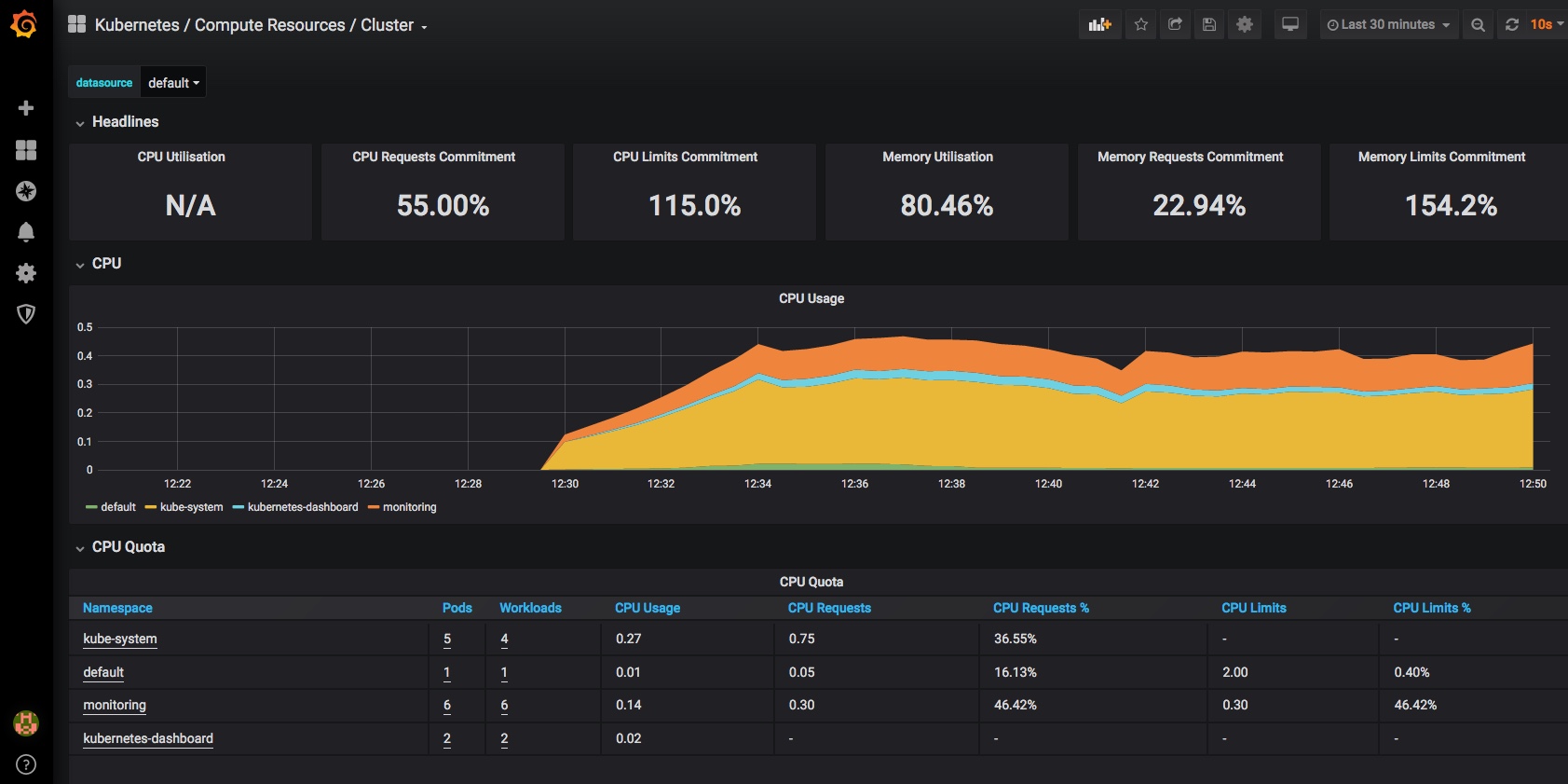
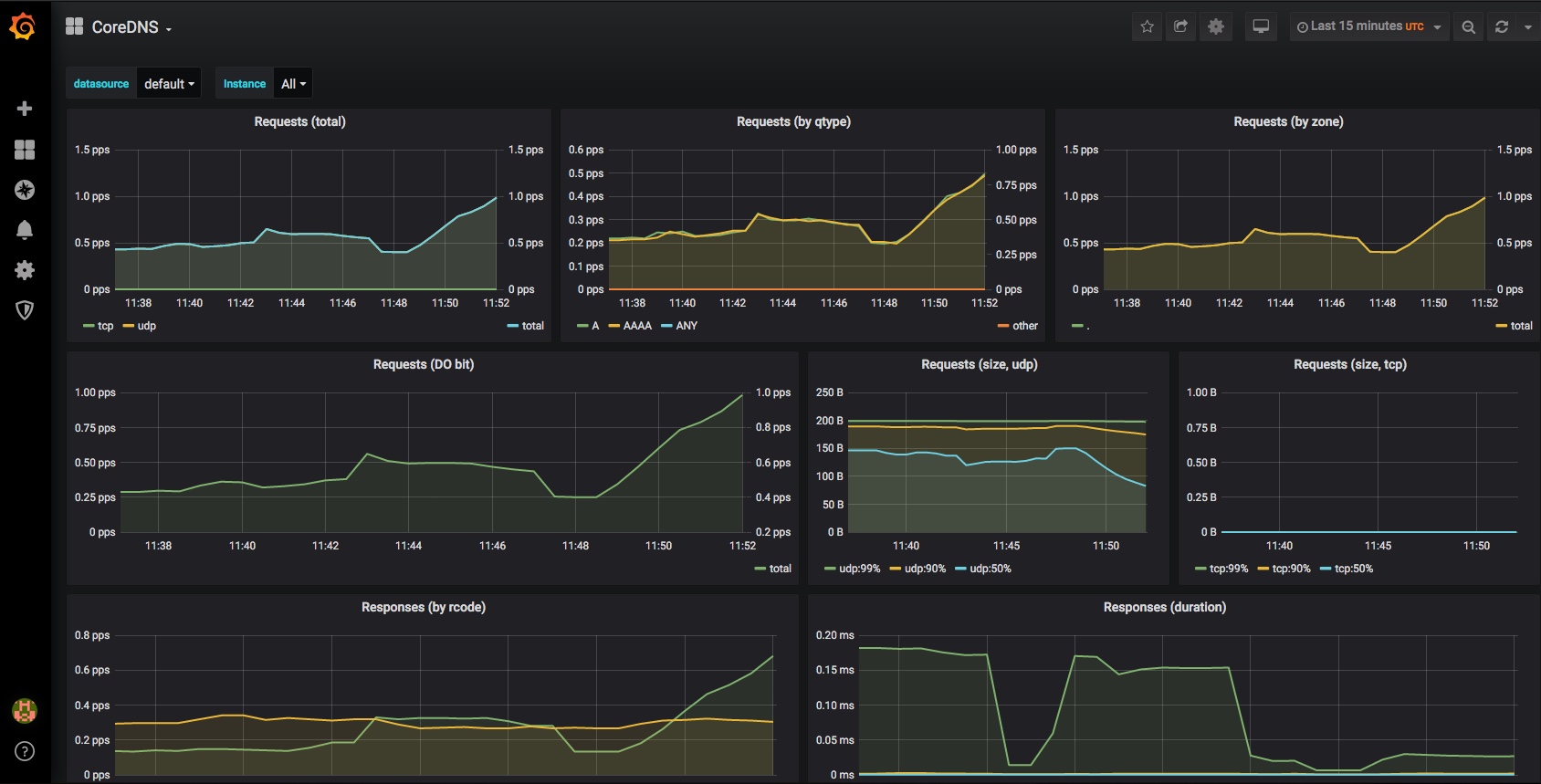
Finally a very quick look at some of the other inbuilt dashboards – you can use and adjust these to monitor all of the components that comprise your cluster and set up alerting when limits or triggers are reached:
All done & next steps
There’s a whole lot more that can be done here, and many other ways to get to this point, but I found this pretty quick and easy.
I’ve only been looking at monitoring of k8s resources here, but you can obviously set up grafana dashboards for many other things, like monitoring your deployed applications. Many applications (and charts and operators) come with prom endpoints built in, and can easily and automatically be added to your monitoring and alerting dashboards along with other datasources.
Cheers,
Don
Discover more from Don's Blog
Subscribe to get the latest posts sent to your email.
We seems to be working on the same stuff! We’ve been trying out Elasticsearch APM for application tracing. We’re about to finally get upgraded to OpenShit 3.11 . Plans are to make a kind of ‘The Bridge’ style dashboard. Will be using prometheus in anger for some serious monitoring and alerting.
Hi,
Sounds good, I haven’t used APM, please keep me posted!
Prometheus and k8s operators are v.cool, the above was planned for a Meetup… maybe one day…
Been looking at AWS ES with Kinesis recently too, it’s impressive – lots to learn though!
Cheers,
Don