This is the next step in a series on using the AWS CDK and AWS CodePipeline.
In the previous post I set up a new local AWS CDK environment and a remote AWS Cloud account, user etc, and connected the two. That got as far as deploying a simple local AWS CDK application to my AWS account and then cleaning it up. This post looks at the next step which is setting up CodeCommit – AWS’s managed and git-based version control system, much like github or gitlab – in preparation for some AWS CodePipeline and AWS CodeBuild posts that will follow on.
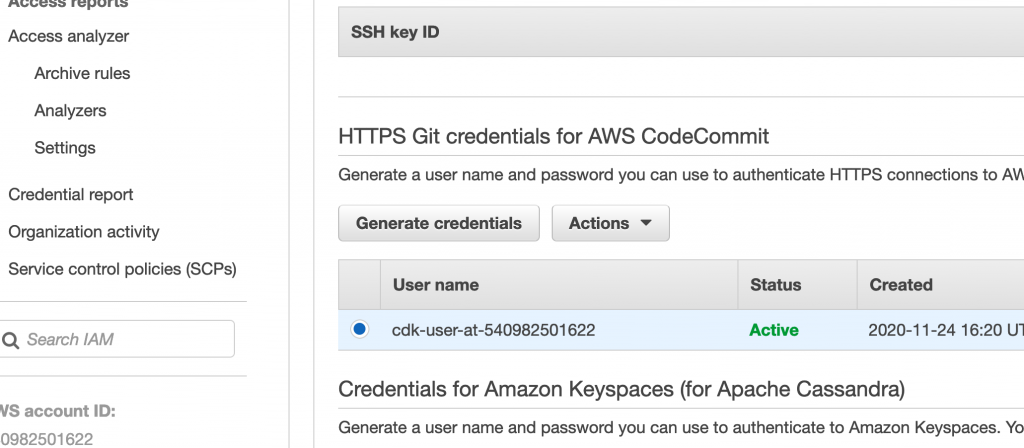
The first step is to add permissions to AWS CodeCommit for your IAM user – I’m using the “cdk-user” that was created previously – as detailed here:
In the AWS UI, go to IAM > User > Security Credentials: Select the “HTTPS Git credentials for AWS CodeCommit (Generate)” option then download the newly generated credentials:
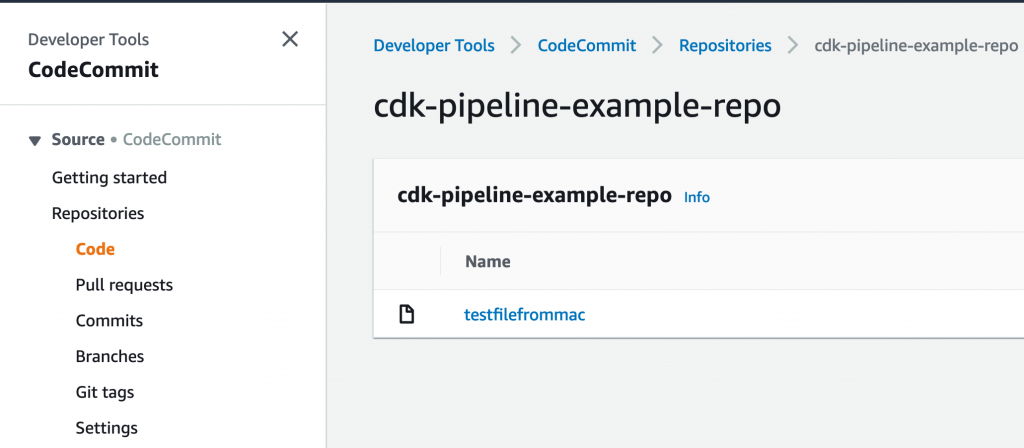
In CodeCommit, create a new Repo if you don’t already have one, click Clone and select/copy the HTTPS link
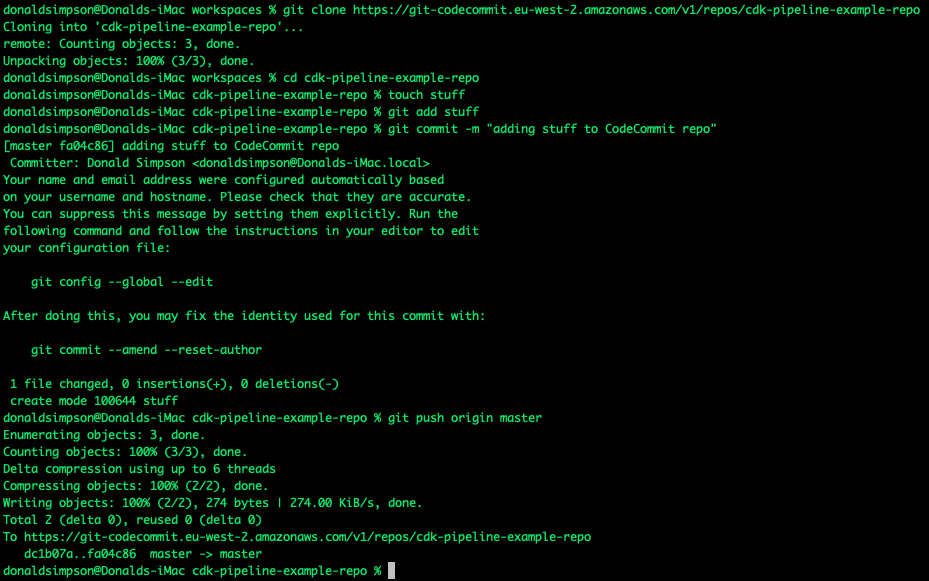
In your local cli, do a “git clone” of the HTTPS repo
when prompted, supply the credentials from above.
You should now be able to interact with the AWS CodeCommit repo in your AWS account using your local git cli in the same way you would for github, bitbucket or gitlab – an example clone, add, merge and push to master (!) as a quick test:
In the next post, this setup will be used to manage and host the source code for new AWS CDK applications, and to manage and trigger the AWS CodePipelines (also written in CDK!) that will build and deploy them.
These are my notes on setting up a new development environment to use the AWS CDK.
Most of this is very well documented already but I’m planning on using this setup for a few upcoming posts, so thought I’d start at the very beginning.
I’m using a Mac but the steps are much the same regardless of OS.
Go to the IAM console in your AWS account and select Users> Create User
I called mine “cdk-user“. Select to enable Programattic Access and add an Admin policy. At the end of the process, select to download the new users credentials.
In your local command line, run:
aws configure
this will prompt you to supply the newly created credentials. Once that is done, you can test connectivity from your local shell to your AWS account with some simple aws commands like:
aws s3 ls
which should simply list the S3 buckets in your account to prove connectivity is working; it may return nothing if there are no buckerts, or an error if it can’t connect.
Verify with a simple example
Now is a good time to decide on an IDE like vscode or atom.
They both have extensions and plugins that make CDK development easier, no matter which language you choose to develop your CDK apps in.
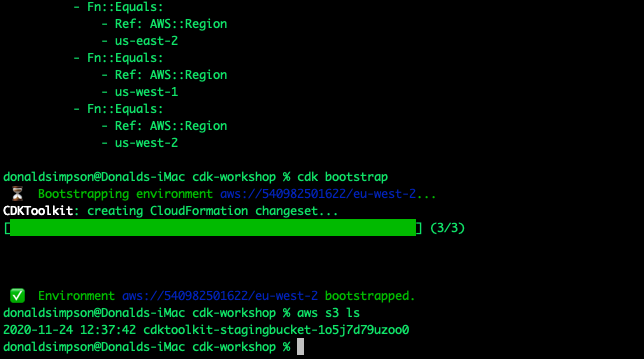
This creates an S3 bucket in our AWS account with the supporting files needed by CDK. This only needs done once.
take a look around the example app’s code, there are a few files of interest: lib/cdk-workshop-stack.ts contains the tiny amount of code used to create an SQS queue and an SNS topic package.json details the project dependencies and node shortcuts for building, watching, testing etc README.md details some useful commands and describes the overall project
After boot-strapping, if you run another
aws s3 ls
you should now see the bootstrap S3 bucket.
and when ready, you can deploy the simple example app with
cdk deploy
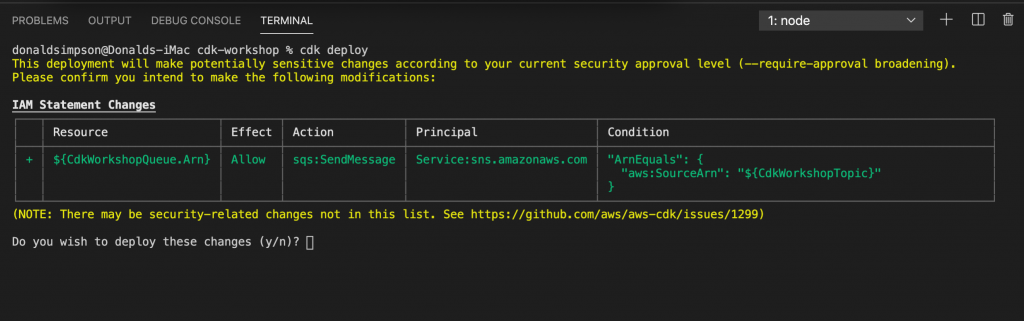
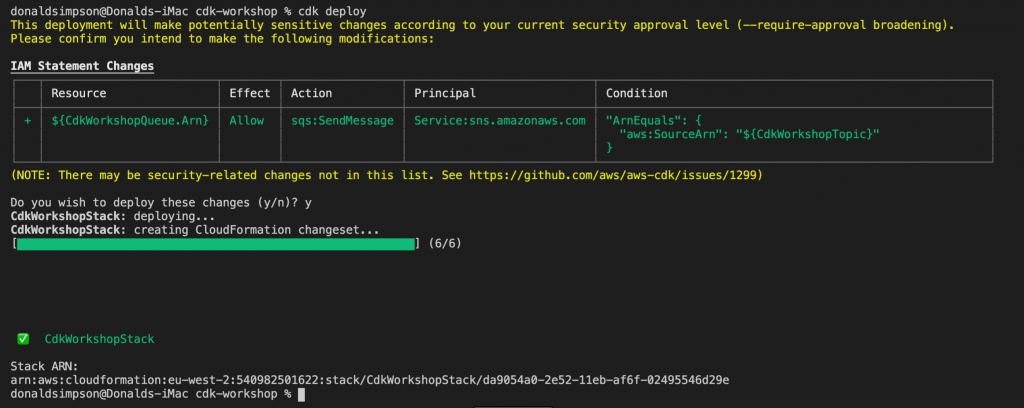
CDK will let you know in advance what is is planning on doing – which resources will be created, deleted or altered, giving you a chance to backout
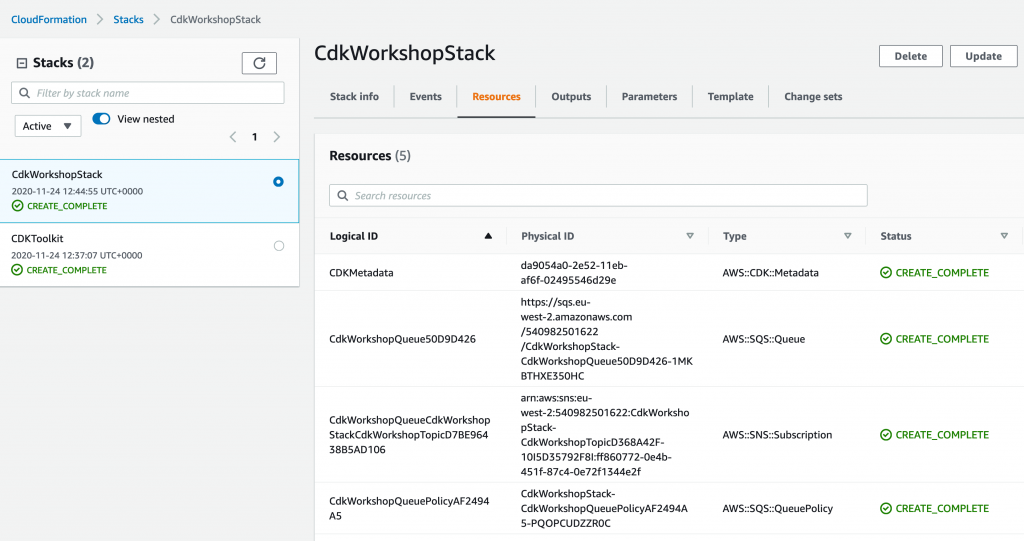
After confirming you want to go ahead with these changes, you should soon see the new stack within your CloudFormation console, along with the CDK toolkit stack we bootstrapped
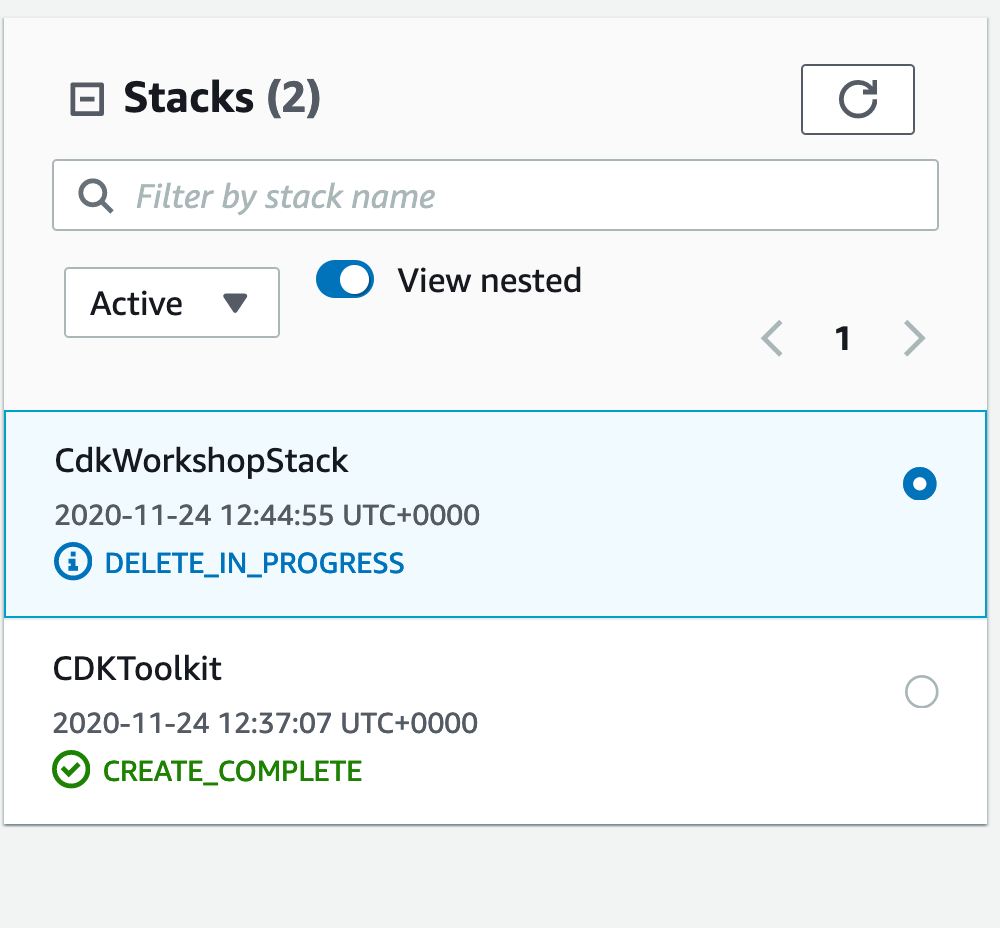
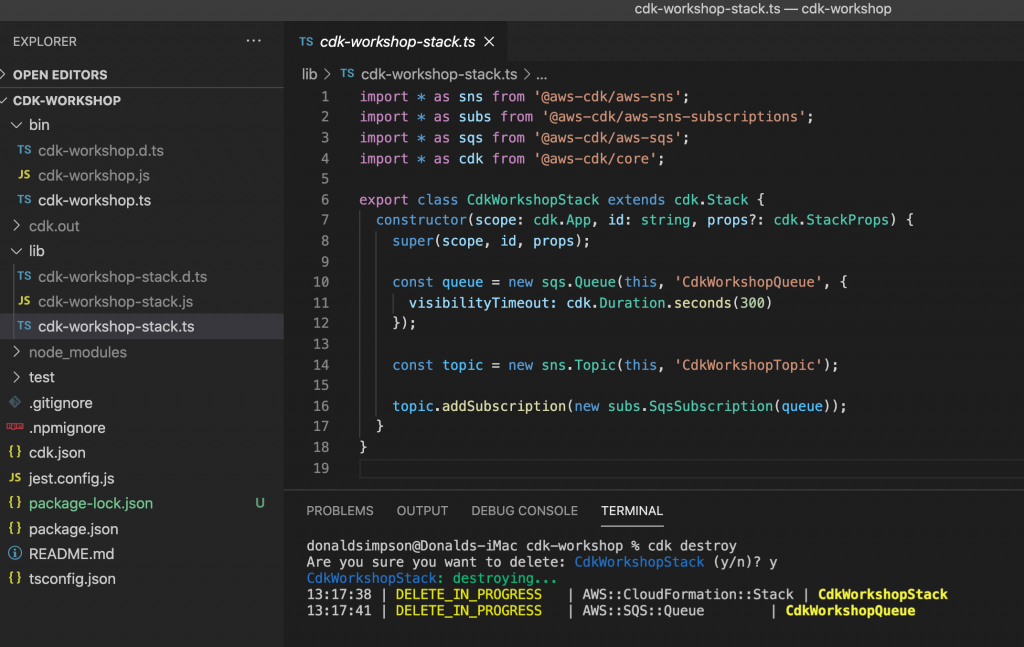
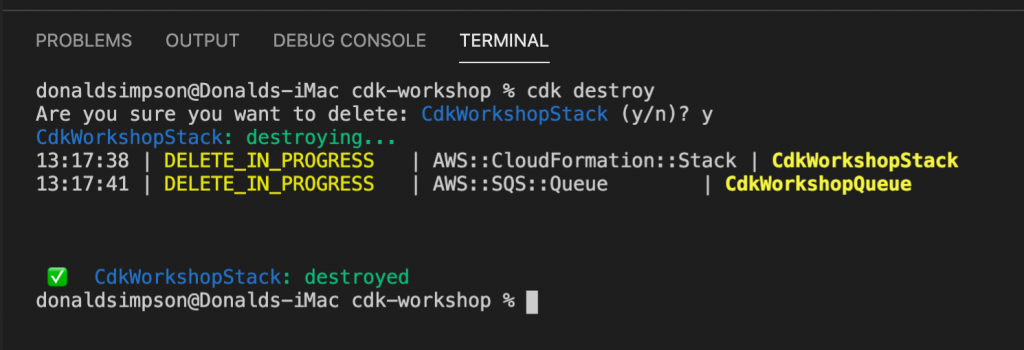
to delete the example stack and clean up, simply do
cdk destroy
That’s it – the local environment is set up and can connect to the AWS account, a very simple app has been built, tested, deployed and deleted, and the one-off CDK bootstrapping has been done.
This is the first of two posts on Kubernetes and HelmCharts, focusing on setting up a local development environment for Kubernetes using Minikube, then exploring Helm for package management and quickly and easily deploying several applications to the cluster – NGINX, Jenkins, WordPress with a MariaDB backend, MySQL and Redis.
The content is taken from the practical/demo session I wrote and published in Github here:
One of the key objectives and challenges here was getting a useful local Kubernetes environment up and running as quickly and easily as possible for as wide an audience as we could- there’s so much to the Kubernetes ecosystem that it’s very easy to get side-tracked, and we could have (happily) spent a long time discussing the myriad of alternative possible solutions.
We plan to go “deeper” on all of this in future sessions and have an in-depth Helm session in the works, but for this session we were focused on creating a practical starting point.
</ramble>
Don
What is covered here:
Minikube – what it is (& isn’t) & why you’d use it (or not)
Kubernetes and Minikube components and concepts
setup for Mac and Linux
creating a first Kubernetes cluster in Minikube
minikube addons – what they are and how they can help you
minikube docker env – using DOCKER_HOST with minikube VM
Kubernetes dashboard with Heapster and Metrics Server – made easy by Minikube
kubectl – some examples and alternatives
example app – “hello (Kubernetes) world” minikube style with NGINX, scaling your world
Helm and Tiller – what they are, when & why you’d maybe use them
Helm and Tiller – prep, install and Helm Charts
Deploying Jenkins via Helm Charts
and WordPress w/MariaDB too
wrap up
Minikube – what it is (& isn’t) & why you’d use it (or not)
What it is, why you’d use it etc.
Local development of k8s – runs a single node Kubernetes cluster in a Virtual Machine on your laptop/PC.
All about making things easy for local development, it is not a production solution, or even close to it.
There are many other ways to run k8s, they all have their pros and cons and use cases. The slides from the Meetup covered this in more detail and include links for further info – they are available here:
Cleanup/prep – if required, remove any previous cluster & settings
`minikube delete; rm -rf ~/.minikube`
Creating a first Kubernetes cluster in Minikube
Here we create a first Kubernetes cluster with Minikube, then take a look around in & outside of the VM.
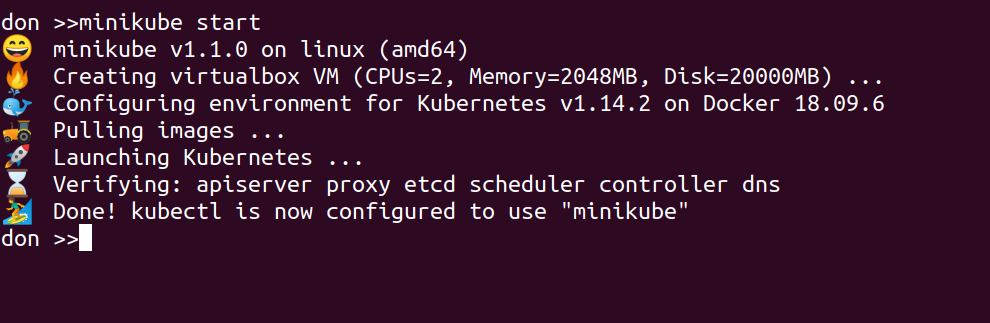
With the above initial setup done, it’s as simple as running this in a shell:
minikube start
Note you could optionally give this Cluster a name, if you are likely to have more than one for different branches of development for example. This is also where you could specify the VM provider if you want to use something other than VirtualBox – there are more details here:
This should produce output like the following, and it may well take a few minutes as the VM is downloaded and started, then a stack of Docker images are started up inside that….
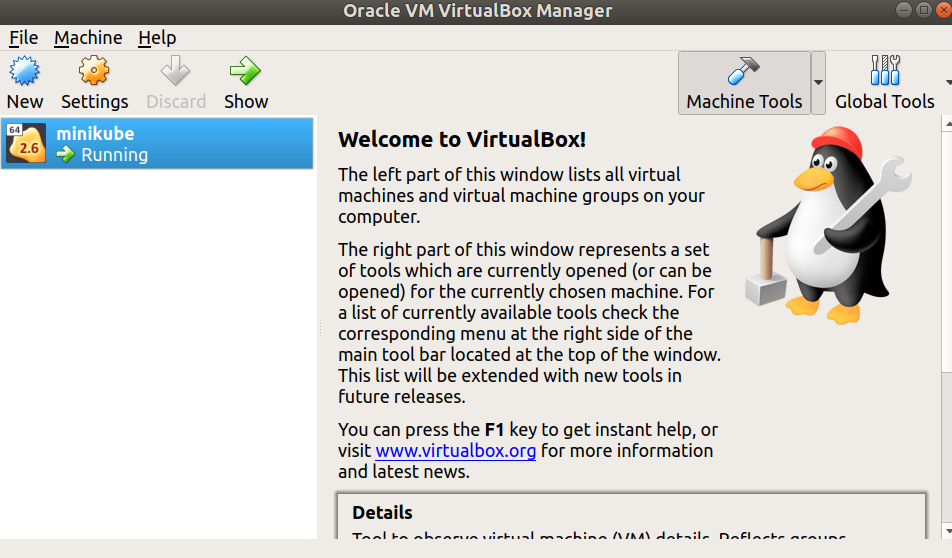
At this point you should be able to see the minikube VM running in the VirtualBox GUI:
Now it’s running, we can connect from our local shell directly to the one inside the running VM by simply issuing:
minikube ssh
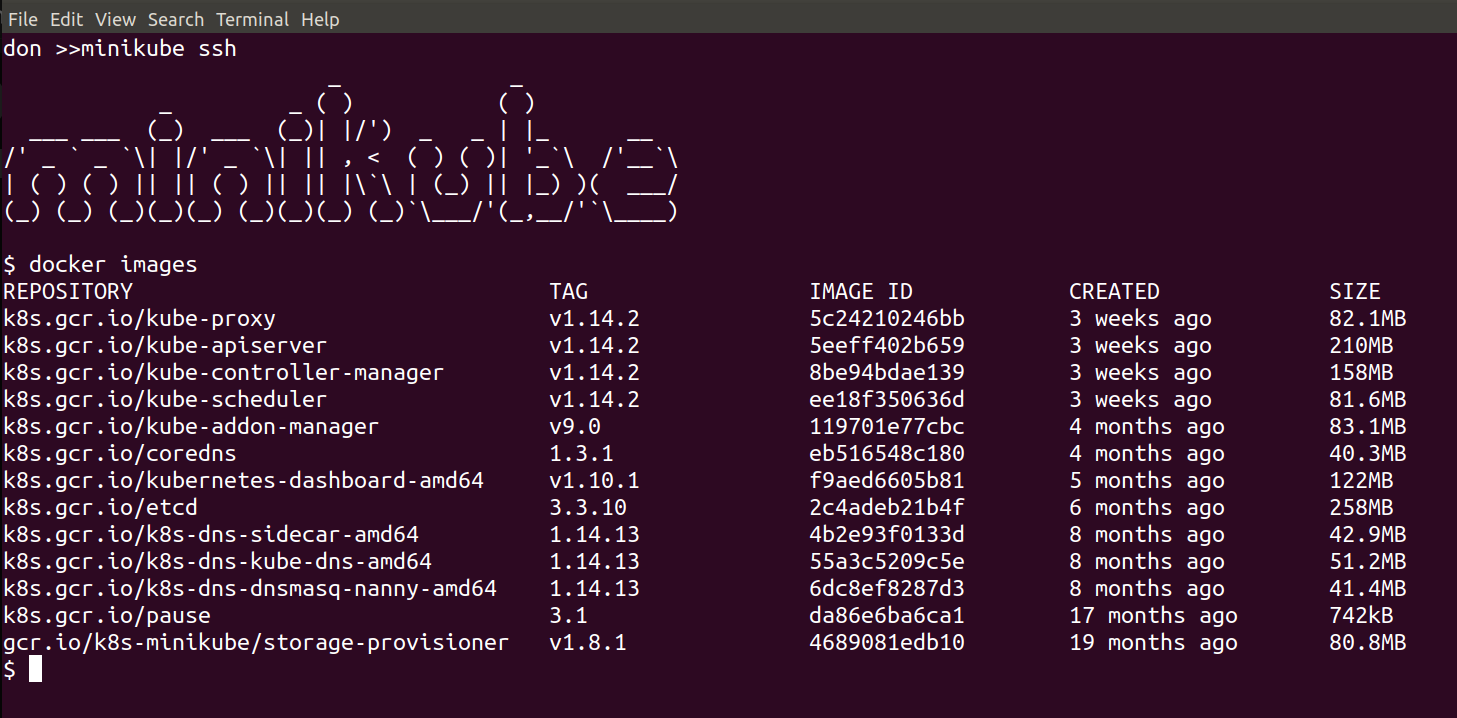
This will put you inside the VM where the Kubernetes Cluster is being run, and we can see and interact with the running components, for example:
docker images
should show all of the downloaded images:
and you could do this to see the running containers:
docker ps
Quitting out of the VM puts us back on the local host, where we can use kubectl to query the status of the Minikube cluster – the initial setup has told kubectl about the Minikube-managed Kubernetes Cluster, meaning there’s no other setup required here:
kubectl cluster-info
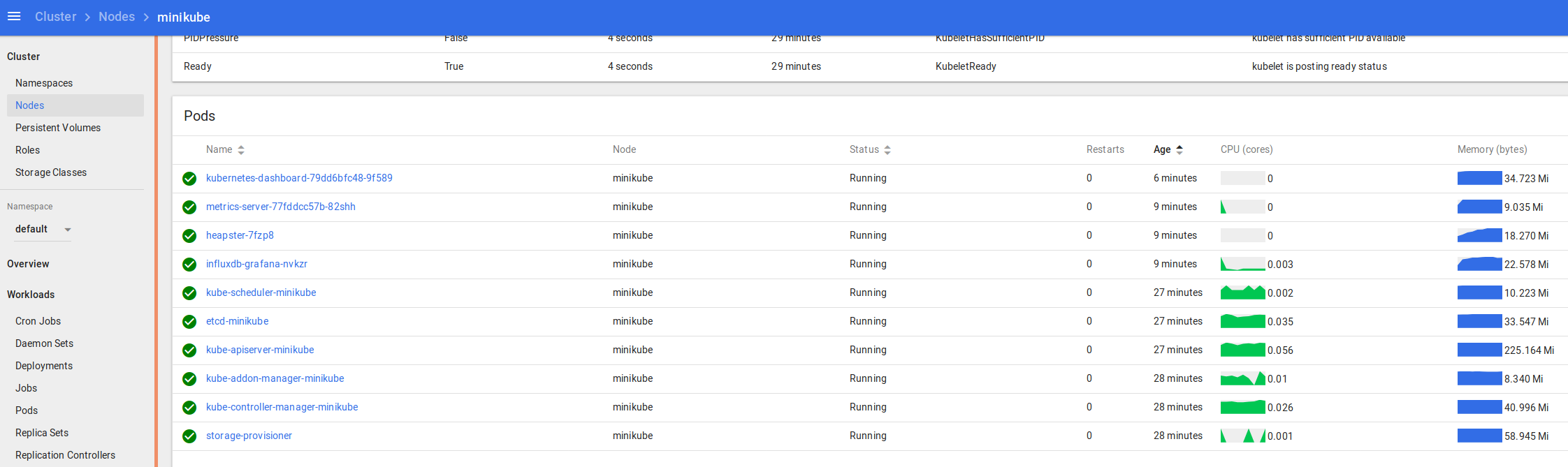
kubectl get nodes
kubectl describe nodes
minikube addons – what they are and how they can help you
Show some of the ways minkube makes things easier for local dev
First, take a moment to look around these two local folders:
ls -al ~/.minikube; ls -al ~/.kube
These are where Minikube keeps its settings and the VM Image, and where kubectl settings are persisted – and updated by Minikube.
With Minikube you’ve often got the option to either use kubectl directly, or to use some Minikube built-in features to make your life easier.
Addons are one of these features, allowing you to very easily add – or remove – functionality from the cluster like this:
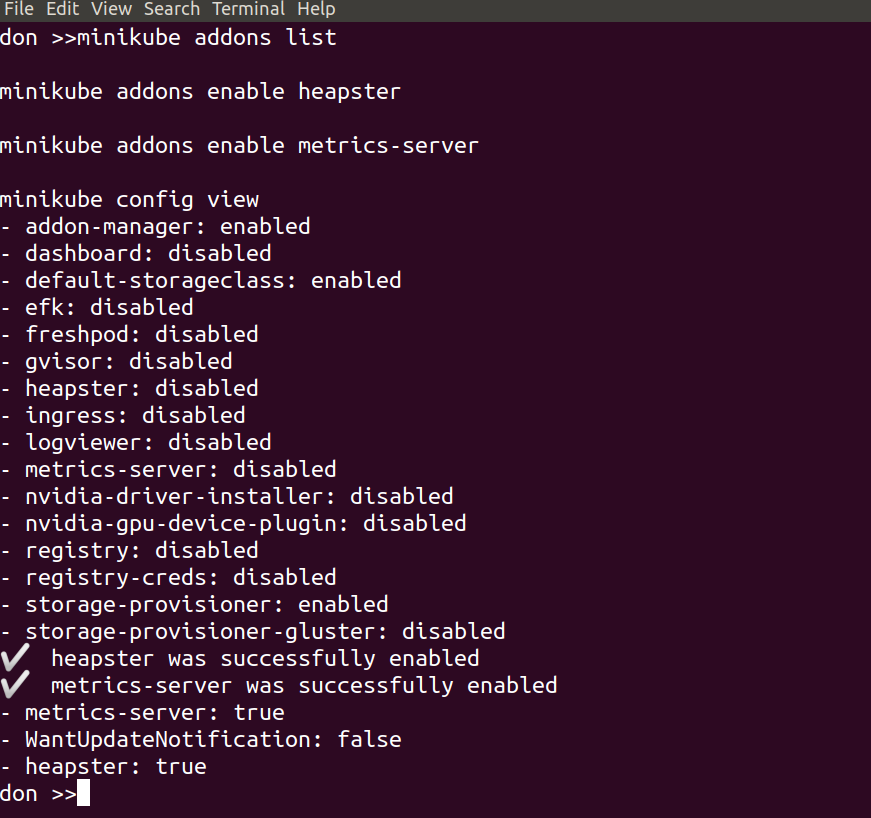
minikube addons list
minikube addons enable heapster
minikube addons enable metrics-server
With those three lines we’ve taken a look at the available addons and their current status, and selected to enable both heapster and the metrics server. This was done to give us cpu and mem stats in the Kubernetes Dashboard, which we will set up in a moment. The output should look something like this:
minikube config view
shows the current state of the config – i.e. what changes have been made, so we can keep a track of them easily.
kubectl --namespace kube-system get pods
now we can enable the dashboard:
minikube addons enable dashboard
and check again to see the current state
minikube addons list
we’ll connect to the Dashboard and take a look around in a moment, but first…
minikube docker env – using the DOCKER_HOST in you minikube VM – how & why
Minikube docker-env – setup local docker client to use minikube docker host
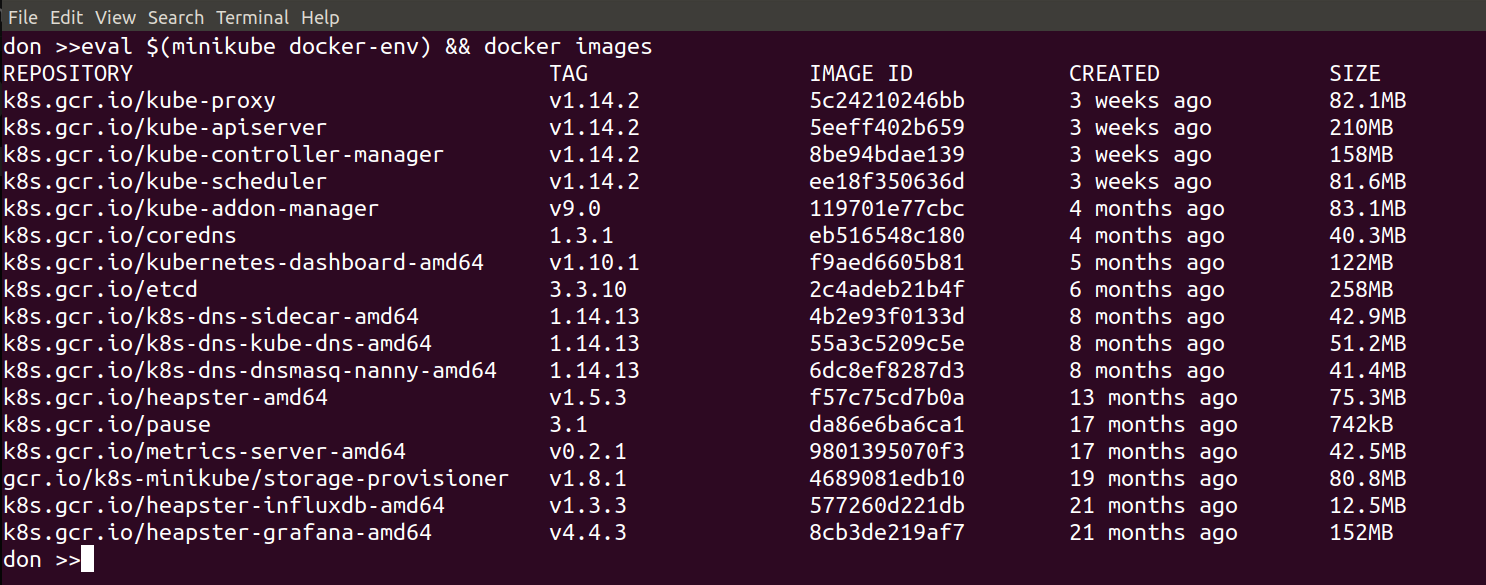
We’re going to look at connecting our local docker client to the docker host inside the Minikube VM. This is made easy by:
minikube docker-env
if you run that command on its own it wiull show you what settings it will export and you can set them by doing:
eval ${minikube docker-env}
From then on, in that shell, your local docker commands will use the docker host inside Minikube.
This is very useful for debugging and local development – when you change and deploy anything to your Kubernetes Cluster, you can easily tail the logs or check for errors or issues. You can also do all of this via the dashboard or kubectl too if you prefer, but it’s another handy and powerful feature from Minikube.
The following image shows the result of running this command:
so we can now use our local docker client to run docker commands like…
docker ps
docker ps | grep -i metrics
docker logs -f <some container id>
etc.
Kubernetes dashboard with Heapster and Metrics Server – made easy by Minikube
Minikube k8s dashboard – here we will start up the k8s dashboard and take look around.
We’ve delayed starting the dashboard up until after we enabled the metrics-server & heapster components we deployed earlier. By doing it in this order, the dashboard will automatically detect and use these components, giving us cpu & mem stats and a nicer looking dash, with no additional config required.
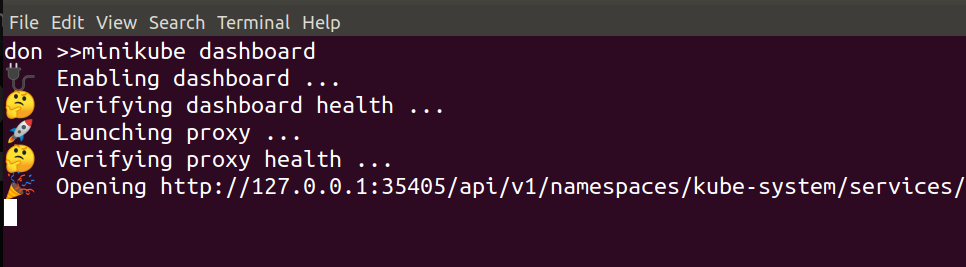
Starting the dashboard simply involved running
minikube dashboard
and waiting for a minute…
That should fire up your browser automatically, then you can take a look around at things like Default namespace > Nodes
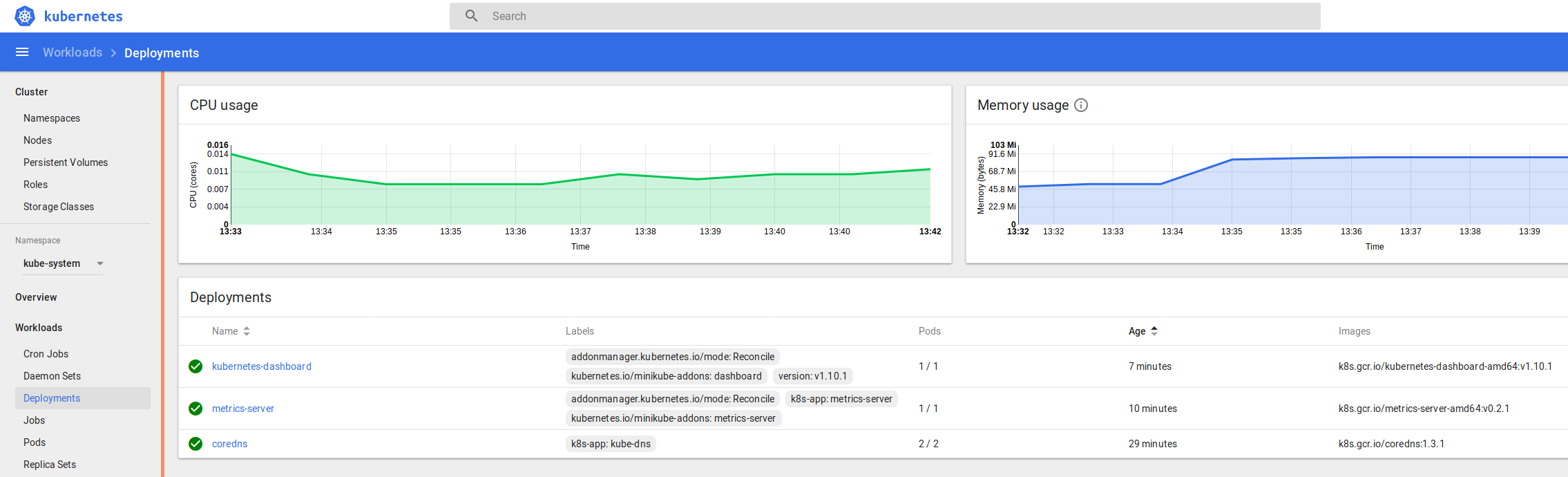
and in the namespace kube-system > Deployments
and kube-system > Pods
You can see the logs and statuses of everything running in your k8s cluster – from the core components we covered at the start, to the dashboard, metrics and heapster we enabled recently, and the application we’re going to deploy and scale up soon.
kubectl – some examples and alternatives
# kubectl command line – look at kubectl and keep an eye on things kubectl get deployment -n kube-system
kubectl get pods -o wide -n kube-system
kubectl get services
kubectl
example app – “hello (Kubernetes) world” minikube style with NGINX, scaling your world
Now we’ll deploy the most basic application we can – a “Hello World” style NGINX docker image.
It’s as simple as this, where nginx is the name of the docker image you want to deploy, hello-nginx is the label you want to give it, and port 80 is where you want it to listen:
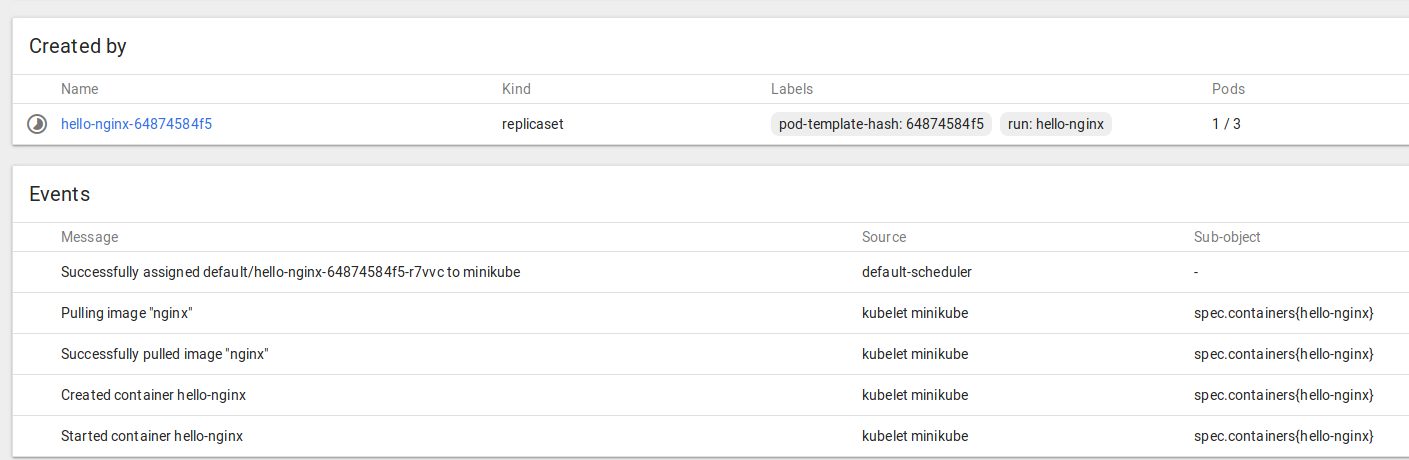
kubectl run hello-nginx --image=nginx --port=80
that shouldn’t take long, and you can watch the progress like this:
Deploying Openshift to AWS with HashiCorp Terraform and Ansible
Tuesday, Oct 16, 2018, 6:15 PM
HAYS 7 Castle St, Edinburgh EH2 3AH Edinburgh, GB
30 Members Went
In this session we look at Infrastructure as Code and Configuration as Code, as we demonstrate how to use these approaches to deploy RedHat OpenShift to AWS with HashiCorp Terraform and Ansible. We start off with configuring AWS credentials, then use HashiCorp Terraform to create the AWS infrastructure needed to deploy and run our own RedHat OpenSh…
Hays office on the 2nd floor
7 Castle St, Edinburgh EH2 3AH · Edinburgh
What:
Deploying Openshift to AWS with HashiCorp Terraform and Ansible
Agenda:
In this session we look at Infrastructure as Code and Configuration as Code, as we demonstrate how to use these approaches to deploy RedHat OpenShift to AWS with HashiCorp Terraform and Ansible.
We start off with configuring AWS credentials, then use HashiCorp Terraform to create the AWS infrastructure needed to deploy and run our own RedHat OpenShift cluster.
We then go through using Ansible to deploy OpenShift to AWS, followed by a review of the Cluster, then take a quick look at troubleshooting any issues you may encounter.
There will be a break in the middle for beer & pizza courtesy of Hays, and we will wrap things up with a quick Q&A and feedback session.
If you would like to bring your own laptop and follow along, please do!
Who:
Intermediate Linux and some AWS knowledge is useful but not essential.
to set up terraform (on a Mac) and provision a basic test instance in AWS.
Install process
This is very easy, simply download terraform for your platform (a single binary), extract it somewhere sensible and add that location to your PATH variable.
As per the guide, the next steps are to get a note of your AWS access_key and secret_key from this AWS page, then create and edit a local “example.tf” file for your project, like this:
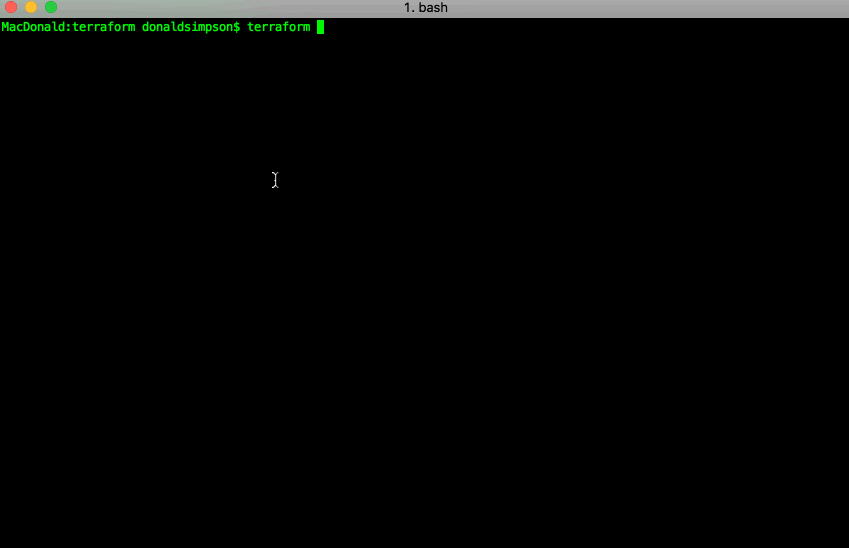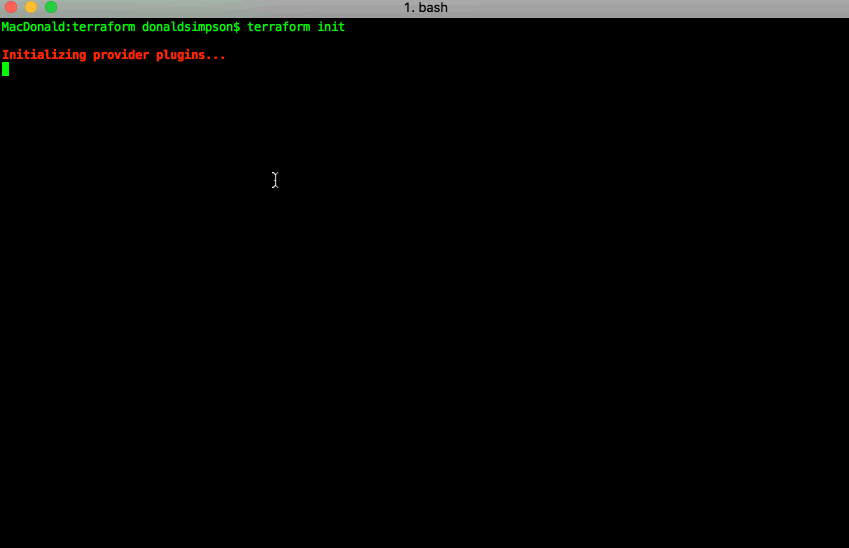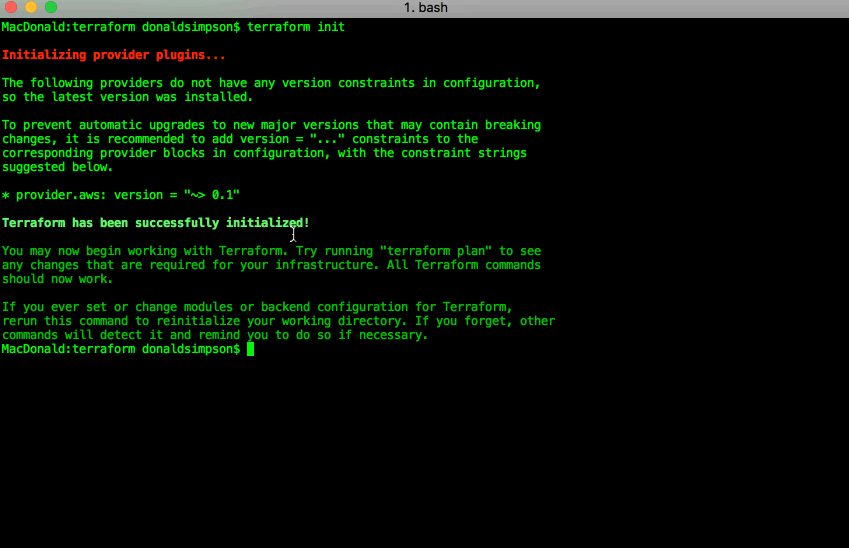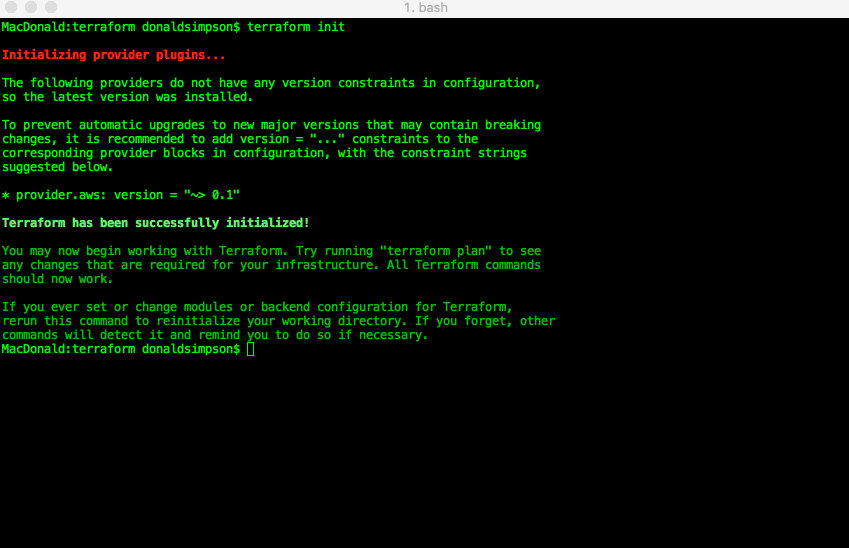
You should now be able to run terraform init and see something positive…
Check the plan
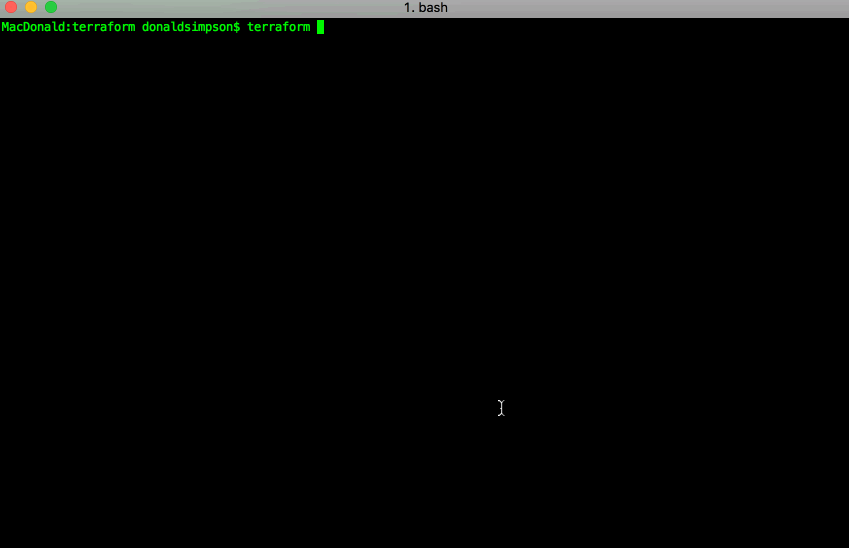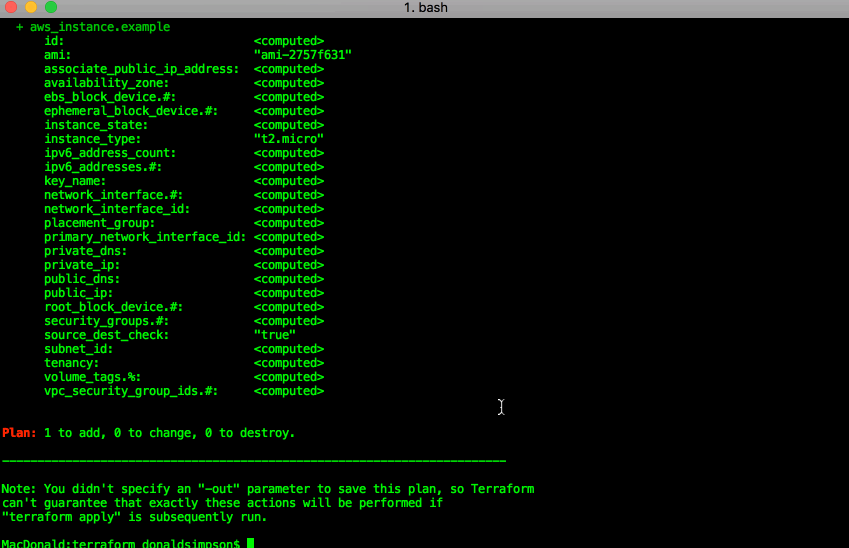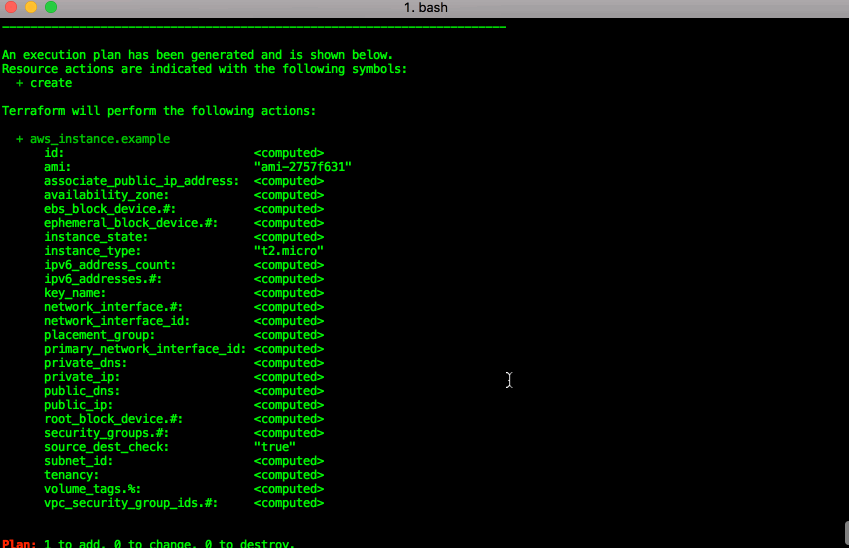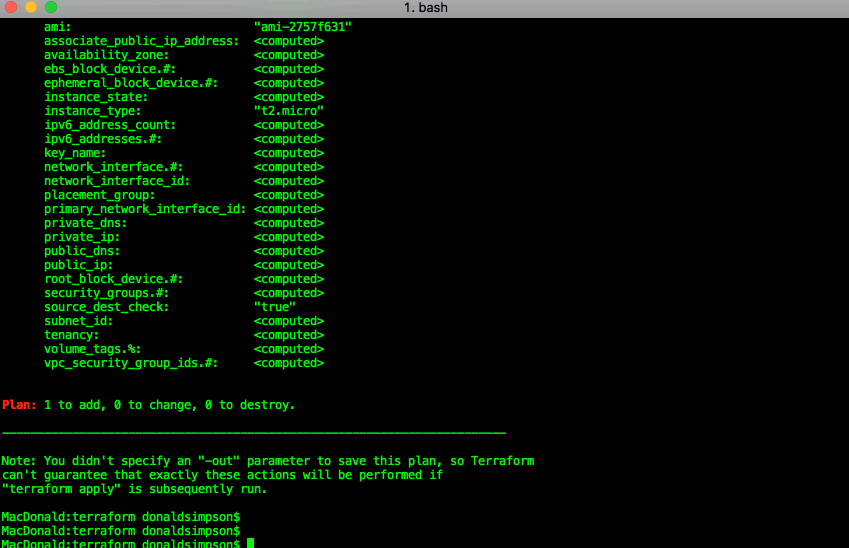
Running “terraform plan” provides a dry run/sanity check of what would be done
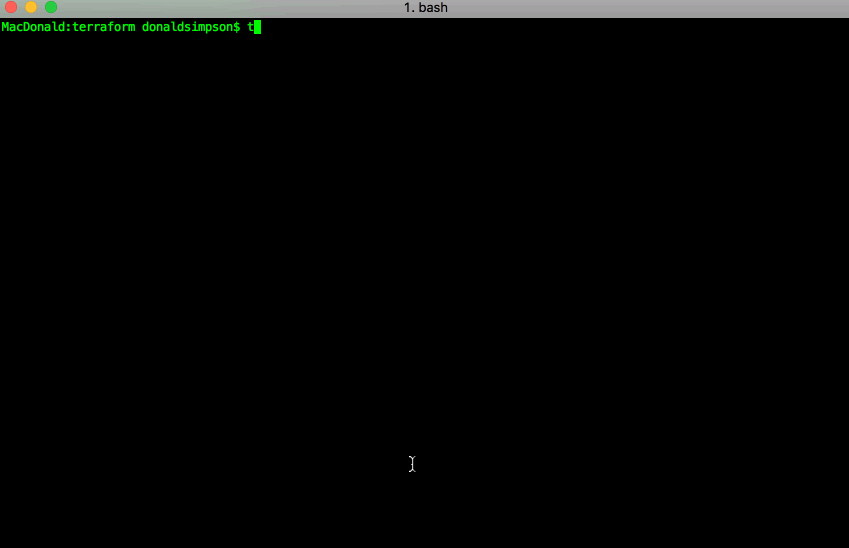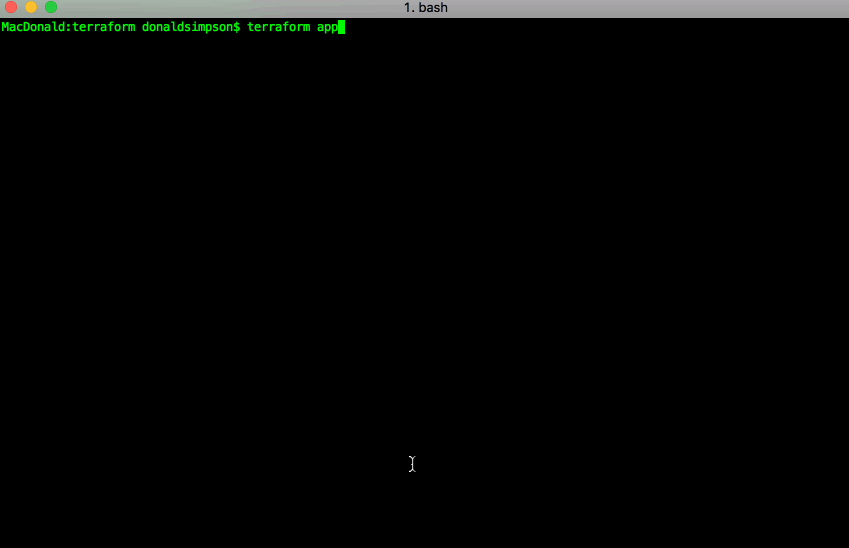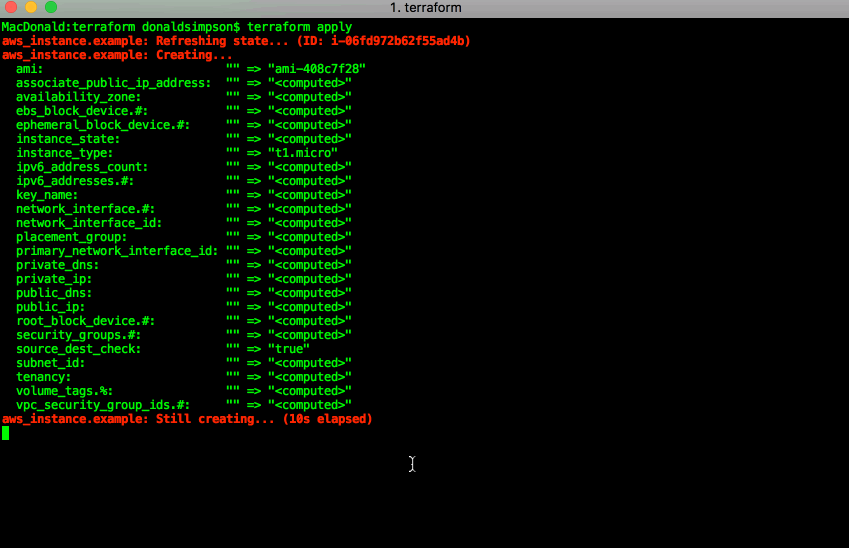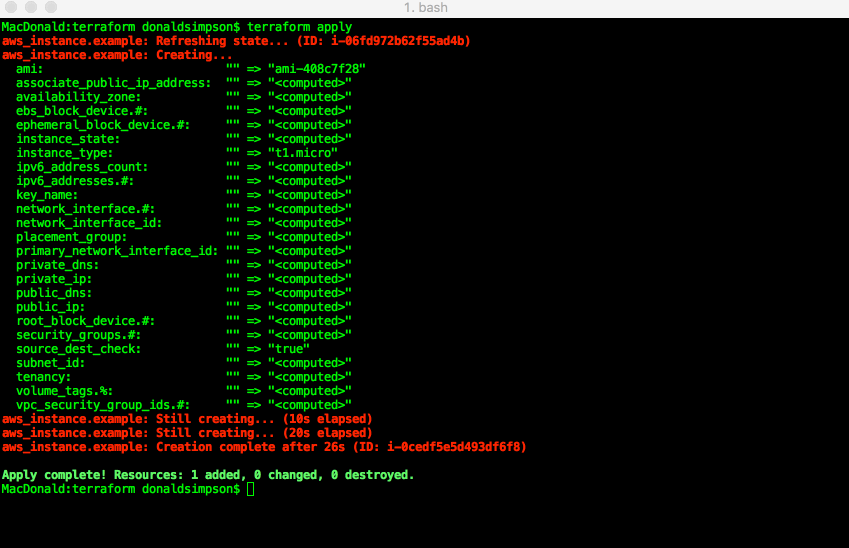
Make it so
terraform apply: run the plan, and actually create the resources listed above:
Show it is so
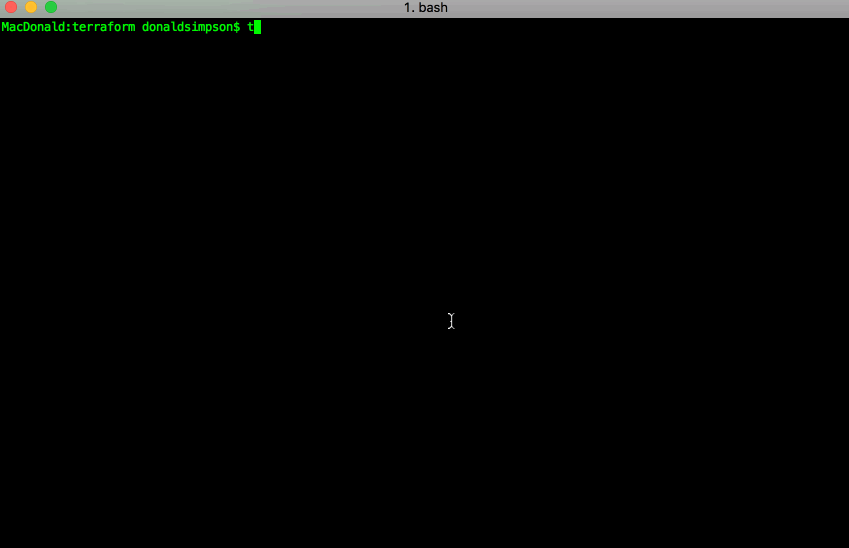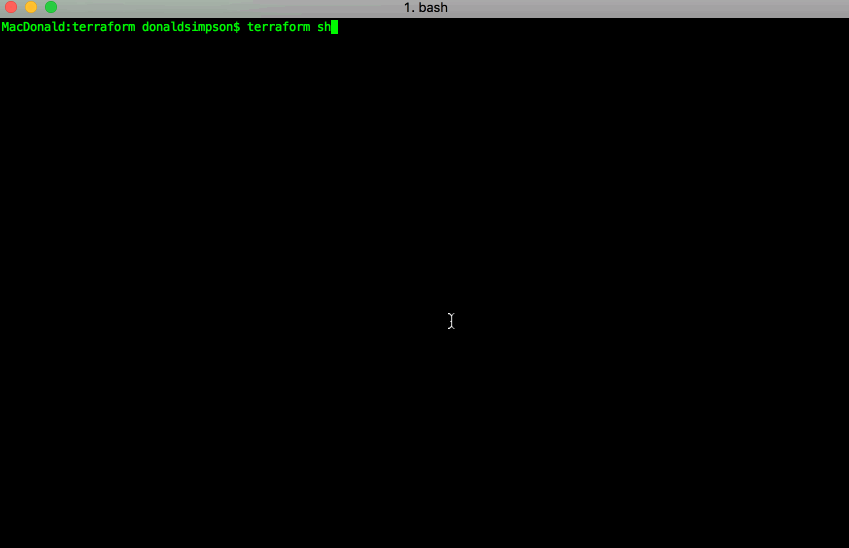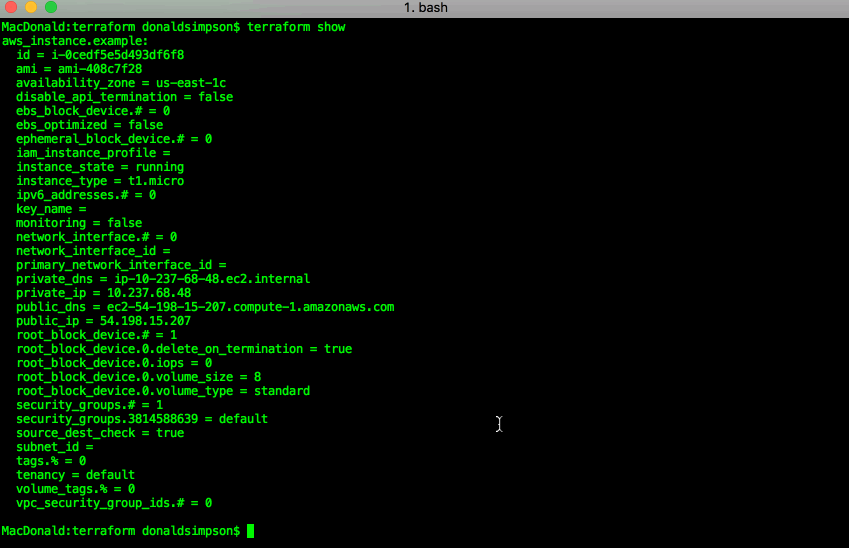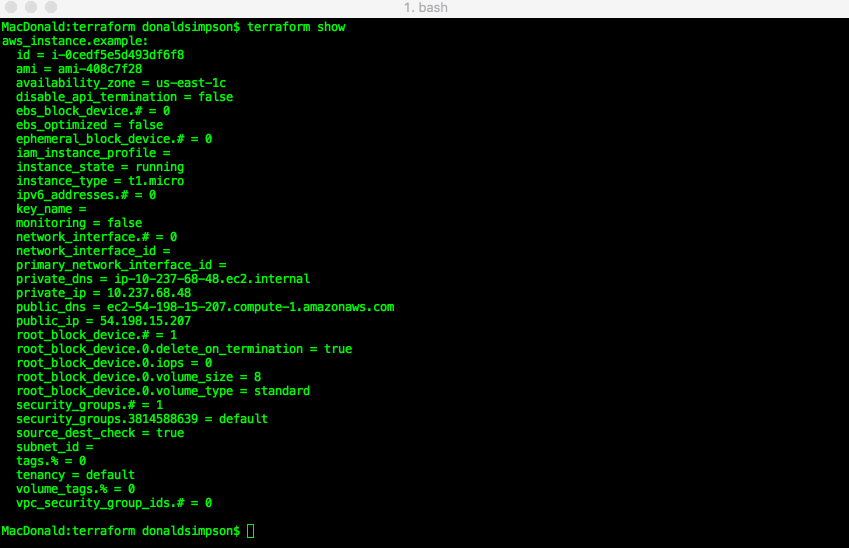
Once that has completed, you can check your AWS console and see the newly created instance:
“terraform show” can confirm the same details in a less pointy-clickety way:
Next steps
This was all pretty simple, quick and straightforward.
The next steps are to manage the hosts in an Infrastructure as Code manner, adding in changes and deletions/reprovisioning, and to do something useful with them.
I’d also like to try using Terraform with Digital Ocean and VMWare providers.
This post is the first in a series of 3 introducing the combined power of Jenkins, Docker, and the Jenkins DSL.
They should hopefully provide enough information to get to grips with both Docker and Jenkins – what they both do and how to use them – by showing some practical examples of them working together.
The first step, if you haven’t already, is to download and install Docker on your platform – the Docker website covers this in good detail for most platforms…
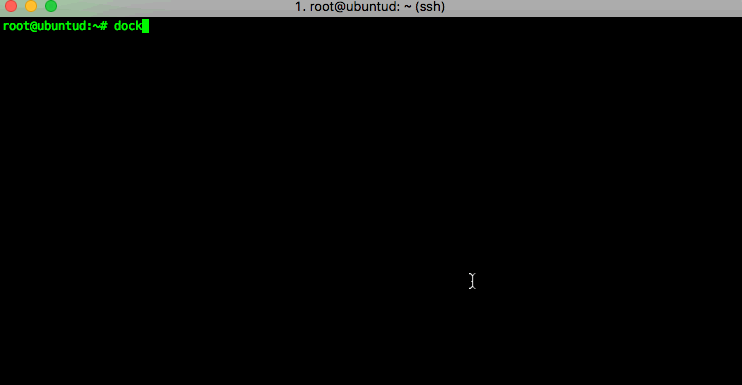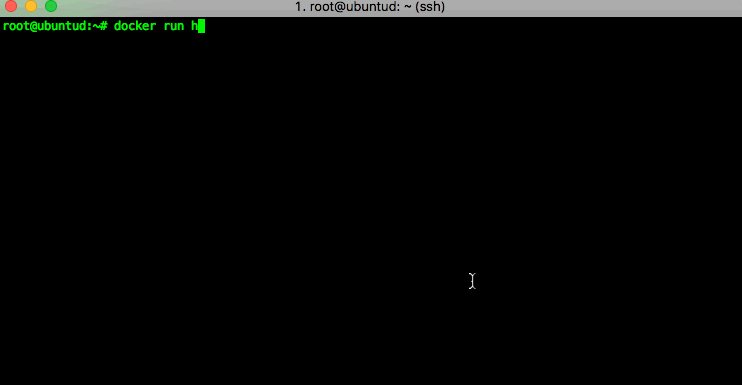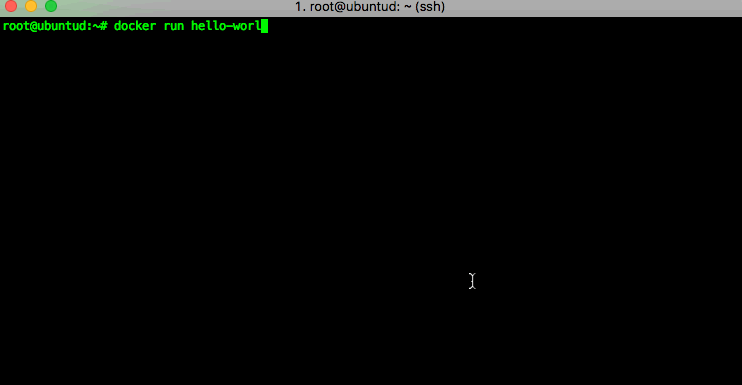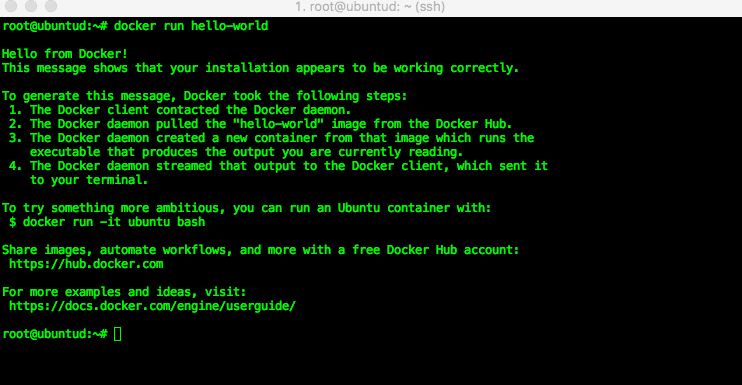
Once that’s done, you can try it out with the customary “Hello World” example…
I’m running Docker on an Ubuntu VM, but the commands and the results are the same regardless of platform – that’s one of the main Docker concepts.
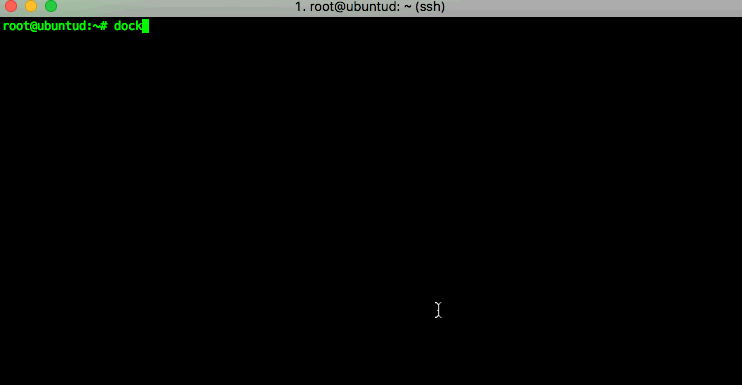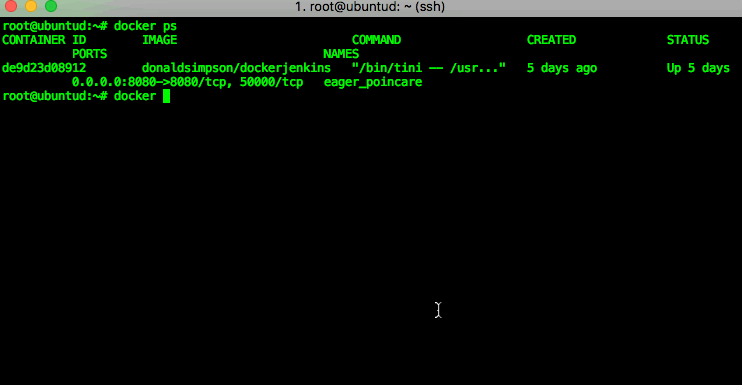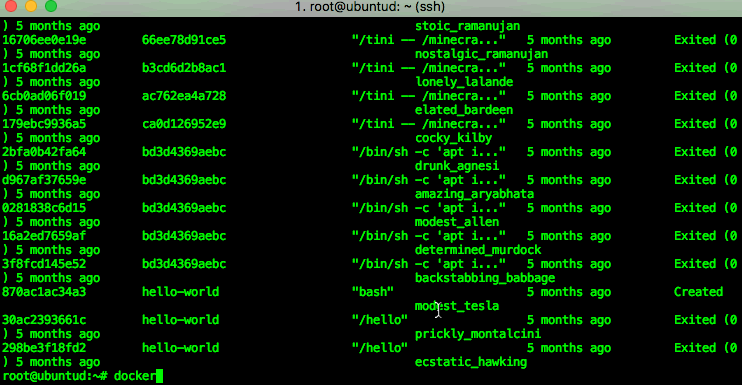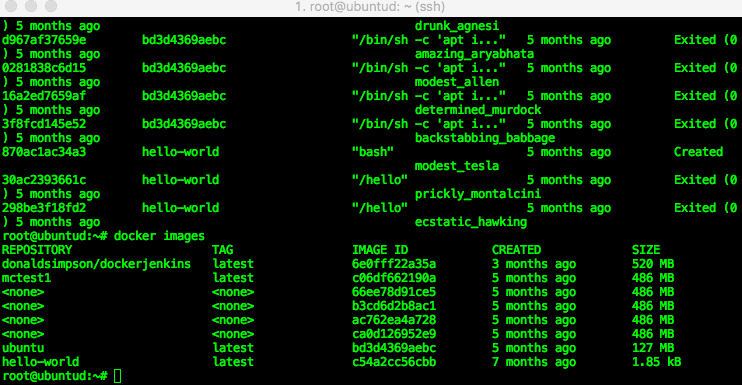
You can then check which processes (docker containers) are running using the “docker ps” command – in my example you can see that there’s one Jenkins image running. If you run “docker ps -a” you will see all containers (including stopped ones, of which I have a few on this host):
and you can check your Docker version with:
root@ubuntud:~# docker --version
Docker version 1.13.0, build 49bf474
Now that the basic setup is done, we can move on to something a little more interesting – downloading and running a “Dockerised” Jenkins container.
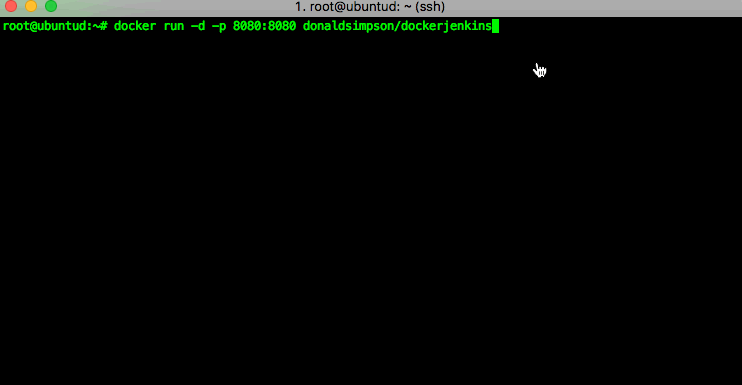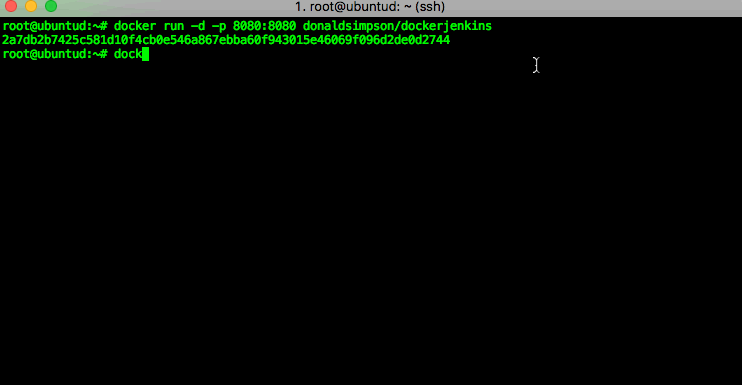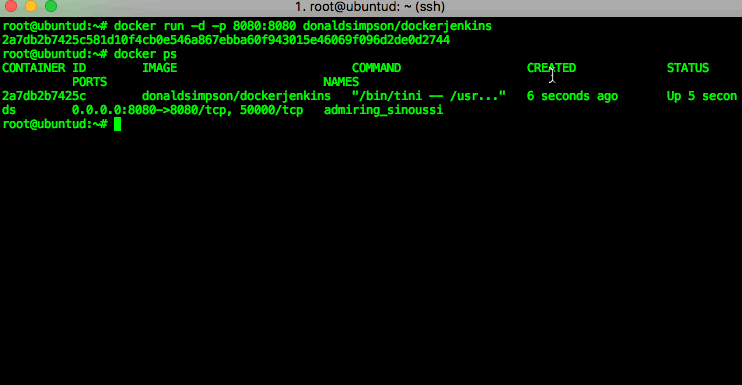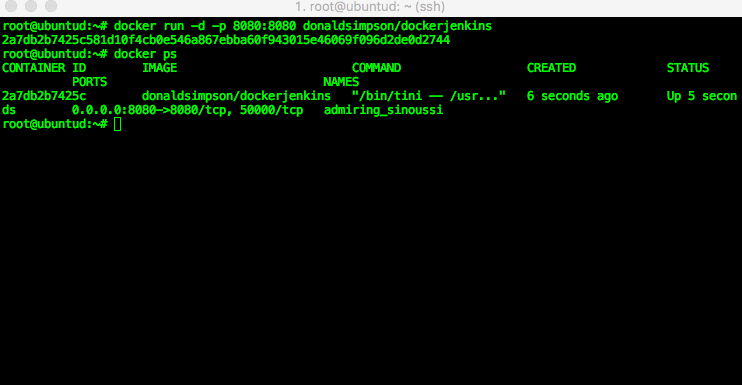
I’m going to use my own Dockerised Jenkins Image, and there will be more detail on that in the next post – you’re welcome to try it out too, just run this command in your terminal:
docker run -d -p 8080:8080 donaldsimpson/dockerjenkins
if you don’t happen to have my docker image cached locally (like I do) then docker will automatically download it for you from Docker Hub then run it:
That command did a quite few important things, here’s a quick explanation of them all:
docker run -d
tells docker that we want to run the container in the background so that we can carry on and do other things while it runs. The alternative is -it, for an interactive/foreground session.
docker run -d -p 8080:8080
The -p 8080:8080 tells docker to map port 8080 on the local host to port 8080 in the running container. This means that when we visit localhost:8080 the request will be passed through to the container.
docker run -d -p 8080:8080 donaldsimpson/dockerjenkins
and finally, we have the namespace and name of the Docker image we want to run – my “donaldsimpson/dockerjenkins” one – more on this later!
You can now visit port 8080 on your Docker host and see that Jenkins is up and running….
That’s Jenkins up and running and being happily served from the Docker container that was just pulled from Docker Hub – how easy was that?!
And the best thing is, it’s entirely and reliably repeatable, it’s guaranteed to work the same on all platforms that can run Docker, and you can quickly and easily update, delete, replace, change or share it with others! Ok, that’s more than one thing, but the point is that there’s a lot to like here 🙂
That’s it for this post – in the next one we will look in to the various elements that came together to make this work – the code and configuration files in my Git repo, the automated build process on Docker Hub that builds and updates the Docker Image, and how the two are related.
I wrote a while back about my troubles with Carrier Grade Nat (CGNAT), and described a solution that involved tunneling out of CGNAT using a combination of SSH and an AWS server – the full article is here.
That worked ok, but it was pretty fragile and not ideal – connections could be dropped, sessions expired, hosts rebooted etc etc. Passing data through my EC2 host is also not ideal.
My “new and improved” solution to this is to use a local tool like ngrok to create the tunnel for me. This is proving to be far simpler to manage, more reliable, and ngrok also provides a load of handy additional features too.
Here’s a very quick run through of getting it up and running on my Ubuntu VM, which sits behind CGNAT and hosts a webserver I’d like to be able to access from the outside occasionally. This is the front end to my ZoneMinder CCTV interface, but it could be anything you want to host and on any port.
First off, don’t use the default Ubuntu install, that will give you version 1.x which is out of date and didn’t work for me at all – it’s better, quicker and easier to get the latest binary for your platform directly from the ngrok website, extract that on your host and run it directly or add it to you PATH.
once that’s downloaded and extracted, you can (optionally) add your auth token, which you get when you register on the ngrok site. This is optional, but you get some worthwhile features from doing so.
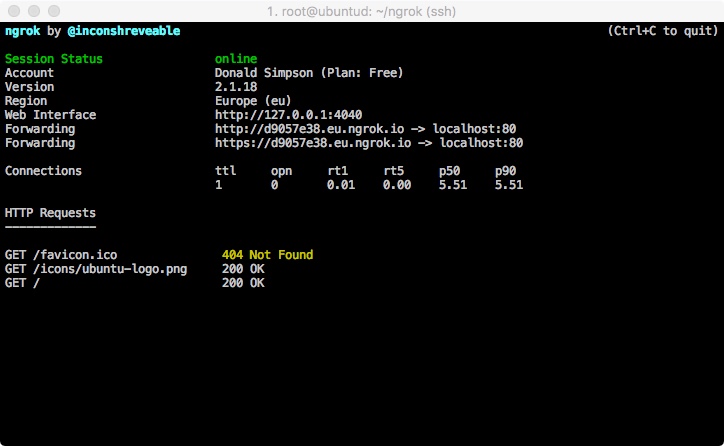
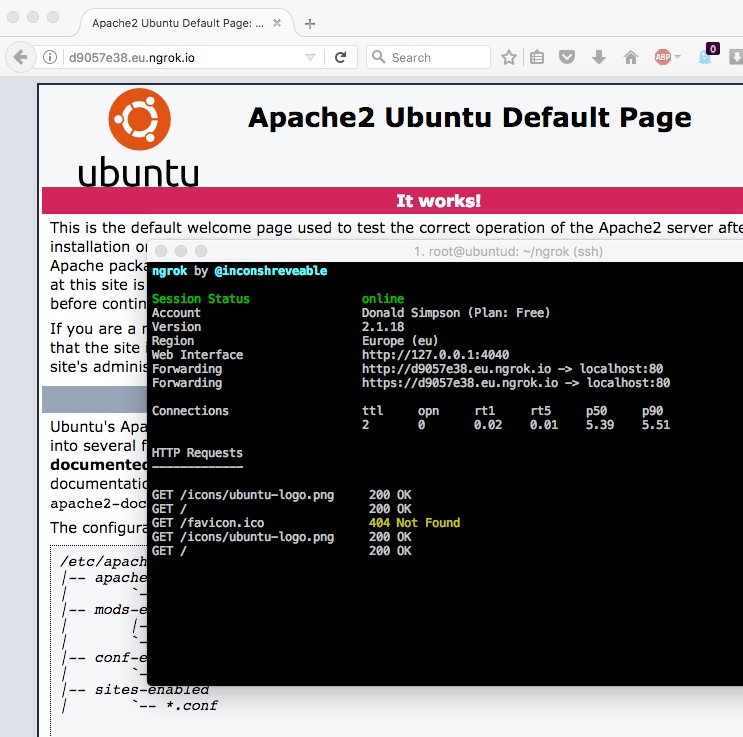
which should give you a console something like this:
from here you can get the Forwarding URL (http://<uniqueid>.eu.ngrok.io in this example) and your local port 80 should be available on that from anywhere on the internet.
Note I’m using this command:
screen ./ngrok http -region eu 80
to start up ngrok using screen, so I can CTRL+A+D out of that and resume it when I want using screen -r,
Here’s a pic of the console running, showing requests, and Apache being served by the ngrok URL:
That’s it – quick and easy, more stable, and far less faffing too.
There are tons of other options worth exploring, like specifying basic HTTP auth, saving your config to a local file, running other ports etc, all of them are explained in the documentation.
PS: Update to add the script I use to update the ngrok URL when it changes.
I have this in a local Jenkins job that runs every 30 mins or so, and it has been happily doing the job for a couple of years now – it’s far from perfect and it’s a lot to set up if you’re not used to these tools, but I’m adding it here just in case it helps anyone else….
#!/bin/bash
# Backup of the Jenkins job/script I put together to automatically update my home ngrok tunnel.
# When the tunnel dies, this script will (via Jenkins) create a new one and update a PHP redirect file on my
# AWS Host that allows me to connect to my CGNET'd home server via my AWS website using a dynamic ngrok end point
# Uses:
# - Jenkins
# - bash
# - ngrok
# - jq
# - grep and awk
# - PHP
# - Apache
# - AWS
# check if ngrok is running/not
pidof ngrok >/dev/null
if [[ $? -ne 0 ]] ; then
# A (re)start and update is required
echo "Starting ngrok on $(date)"
# Start up a new instance of ngrok
BUILD_ID=dontKillMe nohup /root/ngrok/ngrok http -region eu 80 &
# Give it a moment before testing it...
echo "Sleeping for 15 seconds..."
sleep 15
# Get the updated publish_url value from the ngrok api
export NGROKURL=`curl -s http://127.0.0.1:4040/api/tunnels | jq '.' | grep public_url | grep https | awk -F\" '{print $4}'`
echo "NGROKURL is $NGROKURL"
# add that to a one-line PHP redirect page
echo "<?php header('Location: $NGROKURL/zm'); exit;?>" > ZoneMinder.php
# upload that to my AWS host
echo "scp'ing zm.php to AWS host..."
scp -i /MY_AWS_KEY_FILE.pem ZoneMinder.php MY_AWS_USER@MY_AWS_HOST.amazonaws.com:/MY_HTDOCS_DIR/ZoneMinder.php
echo "Transfer complete."
# Send an update message via email
echo "New ngrok url is $NGROKURL/zm" | mailx -s "ngrok zm url updated" MY_EMAIL@gmail.com
else
# Nothing needed, carry on
echo "ngrok is currently running, nothing to do"
fi
After switching to a 4G broadband provider, who shall (pretty much) remain nameless, I discovered they were using Carrier-Grade NAT (aka CGNAT) on me.
There are more details on that here and here but in short, the ISP is ‘saving’ IPv4 addresses by sharing them out amongst several users and NAT’ing their connections – in much the same way as you do at home, when you port forward multiple devices using one external IP address: my home network is just one ‘device’ in a pool of their users, who are all sharing the same external IP address.
The impact of this for me is that I can no longer NAT my internal network services, as I have been given a shared pubic-facing IPv4 address. This approach may be practical for a bunch of mobile phone users wanting to check Twitter and Facebook, but it sucks big time for gamers or anyone else wanting to connect things from their home network to the internet. So, rather than having “Everything Everywhere” through my very expensive new 4G connection – with 12 months contract – it turns out I get “not much to anywhere“.
The Aim
Point being; I would like to be able to check my internal servers and websites when I’m away – especially my ZoneMinder CCTV setup – but my home broadband no longer has its own internet address. So an alternative solution had to be found…
I basically use 2 servers, the one at home (unhelpfully now stuck behind my ISPs CGNAT) and one in the Amazon Cloud (my public facing AWS web server with DNS), and create a reverse SSH Tunnel between them. Plus a couple of essential tweaks you wont find out about if you don’t read any further 🙂
The Steps
Step 1 – create the reverse SSH tunnel:
This is initiated on the internal/home server, and connects outwards to the AWS host on the internet, like so.
Here is an explanation of each part of this command:
-N (from the SSH man page) “Do not execute a remote command. This is useful for just forwarding ports.”
-R (from the SSH man page) “Specifies that connections to the given TCP port or Unix socket on the remote (server) host are to be forwarded to the given host and port, or Unix socket, on the local side.”
8888:localhost:80 – means, create the reverse tunnel from localhost port 80 (my ZoneMinder web app) to port 8888 on the destination host. This doesn’t look right to me, but it’s what’s needed for a reverse tunnel
the -i and everything after it is just me connecting to my AWS host as my user with an identity file. YMMV, whatever you nornally do should be fine.
When you run this command you should not see any issues or warnings. You need to leave it running using whatever method you like – personally I like screen for this kind of thing, and will also be setting up Jenkins jobs later (below).
Step 2 – check on the AWS host
With that SSH command still running on your local server you should now be able to connect to the web app from your remote AWS Web Server, by reading from port 8888 with curl or wget.
This is a worthwhile check to perform at this point, before moving on to the next 2 steps – for example:
This shows that port 8888 on my AWS server is currently connected to the ZoneMinder application that’s running on port 80 of my home web server. A good sign.
Step 3 – configure AWS Security & Ports
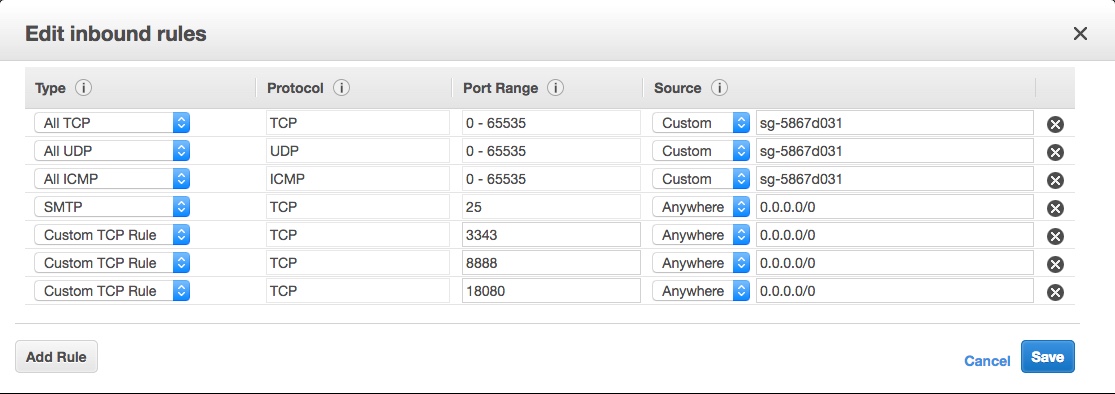
Progress is being made, but in order to be able to hit that port with a browser and have things work as I’d like, I still need to configure AWS to allow incomming connections to the newly chosen port 8888.
This is done through the Amazon EC2 Management Console using the left hand menu item “Network & Security” then “Security Groups”:
This should load your current Security Groups, which you can click on to Edit. You may have a few to check.
Now select Add and configure a new Inbound rule something like so:
It’s the “Custom TCP Rule” second from the bottom, with port 8888 and “Anywhere” and “0.0.0.0/0” as the source in my picture. Don’t go for the HTTP option – unless you’re sure that’s what you want 🙂
Step 4 – configure SSH on AWS host
At this point I thought I was done… but it didn’t work and I couldn’t immediately see why, as the wget check was all good.
Some head scratching and checking of firewalls later, I realised it was most likely to be permissions on the port I was tunneling – it’s not very likely to be exposed and world readable by default, is it? Doh.
to that file, checking that there’s no existing reference to GatewayPorts – edit this file carefully and at your own risk.
As I understand it – which may best be described as ‘loosely’ – the reason this worked when I tested with wget earlier is because I was connecting to the loopback interface; this change to sshd binds the port to all interfaces. See the detailed answer on this post for further detail, including ways to limit this to specific users.
Once that’s done, restart sshd with
service ssh restart
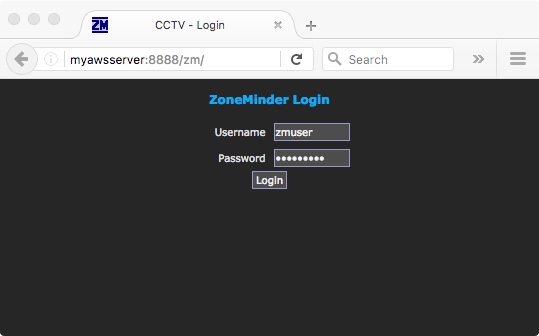
and you should now be able to connect by pointing a web browser at port 8888 (or whatever you set) of your AWS web server and see your app responding from the other end:
Step 5 – automate it with Jenkins
The final step for me is to wrap this (the ssh tunnel creation part) up in a Jenkins job running on my home server.
This is useful for a number of reasons, such as avoiding and resetting defunct/stale connections and enabling scheduling – i.e. I can have the port forwarded when I want it, and have it shutdown during the hours I don’t.