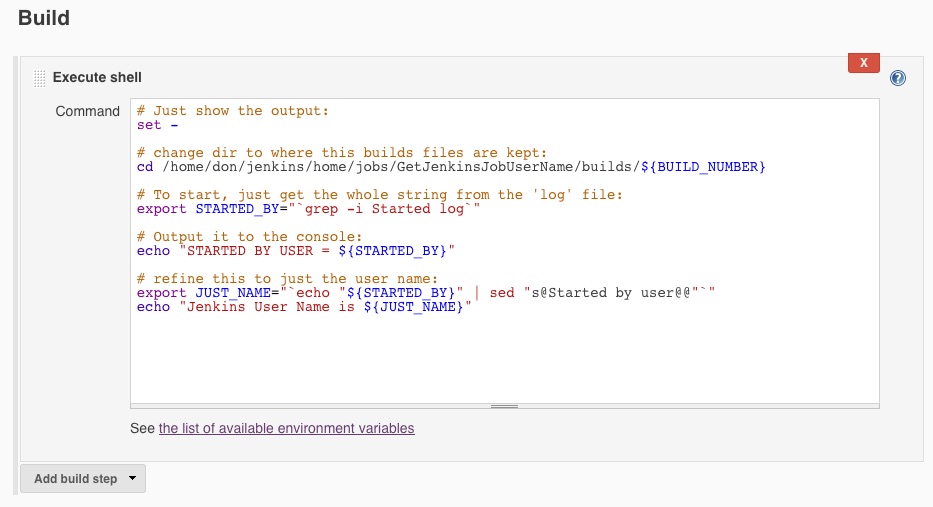
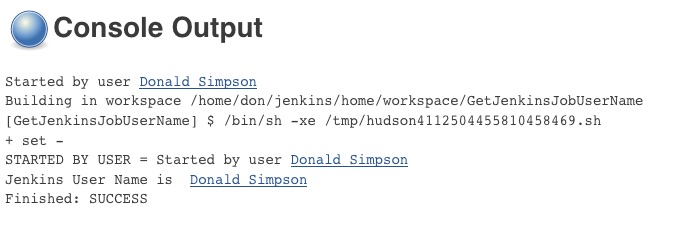
Time for a new PHP and MySQL app – “Who said that?” – a search tool for famous quotations.
I created these two web applications a while back:
UK post code search
crossword solver
and then wrote this page:
Some PHP examples
detailing roughly how they were put together, but this time I wanted to create a searchable database of famous quotations, and focus on the MySQL side of things a bit more too (so that next time I will have a note of how I did it!).
I found a very nice CSV data file on http://thewebminer.com/download for free – I don’t really do Facebook much and don’t have a Twitter account so I thought/hoped they’d settle for a blog post in exchange…
After installing and setting up MySQL, connect to your database…
mysql –user=myuser –password=myusualpassword dev
— or connect without specifying a database/schema and do “show databases;”
mysql> show tables; +---------------+ | Tables_in_dev | +---------------+ | areacodes | | dictionary | +---------------+ 2 rows in set (0.02 sec)
For this little app, I want to create a new table with fields for each row in the CSV file
plus I’d like an auto_increment field to make fetching random numbers easier
CREATE TABLE quotes ( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, quote varchar(800), author varchar(100), genre varchar(100) );
mysql> show tables; +---------------+ | Tables_in_dev | +---------------+ | areacodes | | dictionary | | quotes | +---------------+ 3 rows in set (0.00 sec)
mysql> describe quotes; +--------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------+--------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | quote | varchar(800) | YES | | NULL | | | author | varchar(100) | YES | | NULL | | | genre | varchar(100) | YES | | NULL | | +--------+--------------+------+-----+---------+----------------+ 4 rows in set (0.06 sec)
ok, the table looks good, so I can load the CSV data file – note that I’ve got the “quotes35000.csv” file I downloaded from
http://thewebminer.com/download sitting in the current directory:
mysql> load data local infile 'quotes35000.csv' into table quotes -> fields terminated by ';' -> lines terminated by 'n' -> (quote, author, genre); Query OK, 35002 rows affected (1.54 sec) Records: 35002 Deleted: 0 Skipped: 0 Warnings: 0
that looks like it went well (“35002 rows affected”), time to check it:
mysql> select count(*) from quotes; +----------+ | count(*) | +----------+ | 35002 | +----------+ 1 row in set (0.04 sec)
mysql> select * from quotes where author like '%Einstein' and genre like 'attitude%'; +------+-----------------------------------------------------+-----------------+-----------+ | id | quote | author | genre | +------+-----------------------------------------------------+-----------------+-----------+ |4647 | Weakness of attitude becomes weakness of character. | Albert Einstein | attitude +------+-----------------------------------------------------+-----------------+-----------+ 1 row in set (0.02 sec)
All looking good, the row count and the returned query match what I’d expect having looked at the contents of the CSV file.
I also want to do a “random quote of the day thing”, so looked in to ways to do this in MySQL – my initial thought was to use something basic like “ORDER BY RAND() LIMIT 0,1;” to bring back one random row, but I guessed there may be better ways.
Google led me to this site which has some good examples and some performance/comparison details too:
http://akinas.com/pages/en/blog/mysql_random_row/
so I tried this…
mysql> SELECT * FROM quotes WHERE id >= (SELECT FLOOR( MAX(id) * RAND()) FROM quotes ) ORDER BY id LIMIT 1; +-----+--------------------------------------------------------------------------+-----------------+-------+ | id | quote | author | genre | +-----+--------------------------------------------------------------------------+-----------------+-------+ |84 | Men are like wine - some turn to vinegar, but the best improve with age. | Pope John XXIII | age +-----+--------------------------------------------------------------------------+-----------------+-------+ 1 row in set (1.54 sec)
then this…
mysql> SELECT * FROM quotes ORDER BY RAND() LIMIT 0,1; +-------+-------------------------------------------------------------------------------------+----------------+-------+ | id | quote | author | genre | +-------+-------------------------------------------------------------------------------------+----------------+-------+ |29470 | The good die young, because they see it's no use living if you have got to be good. | John Barrymore | good +-------+-------------------------------------------------------------------------------------+----------------+-------+ 1 row in set (0.73 sec)
and found to my surprise that in this case, looking at the timings, the simple approach looks to be faster – probably because of the relatively small table and its simple structure?
Anyway, that’s the database side of things sorted, the next part is to put together some PHP code to allow searching for quotes based on author, partial quote or genre, and to write a simple “random quote” generator kind of thing.
Cheers,
Don