This is a follow on to the previous writeup on Kubernetes with Minikube and shows how to quickly and easily get a Kubernetes cluster up and running using VirtualBox and Minikube.
The setup is very similar for all platforms, but this post is specifically focused on Mac, as I’m planning on using this as the basis for a more complex post on Jenkins & Kubernetes Pipelines (and that post is now posted, here!).
Installing required components
There are three main components required:
VirtualBox is a free and open source hypervisor. It is a light weight app that allows you to run Virtual Machines on most platforms (Mac, Windows, Linux). We will use it here to run the Minikube Virtual Machine.
Kubectl is a command line tool for controlling Kubernetes clusters, we install this on the host (Mac) and use it to control and interact with the Kubernetes cluster we will be running inside the Minikube VM.
Minikube is a tool that runs a single-node Kubernetes cluster in a virtual machine on your personal computer. We’re using this to provision our k8s cluster and will also take advantage of some of the developer friendly addons it offers.
Downloads and Instructions
Here are links to the required files and detailed instructions on setting each of these components up – I went for the ‘brew install‘ options but there are many alternatives in these links. The whole process is very simple and took about 10 minutes.
most popular hypervisors are well supported by Minikube.
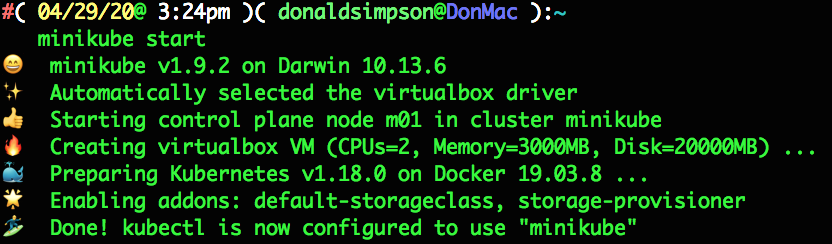
Here’s what that looks like on my Mac – this may take a few minutes as it’s downloading a VM (if not already available locally), starting it up and configuring a Kubernetes Cluster inside it:
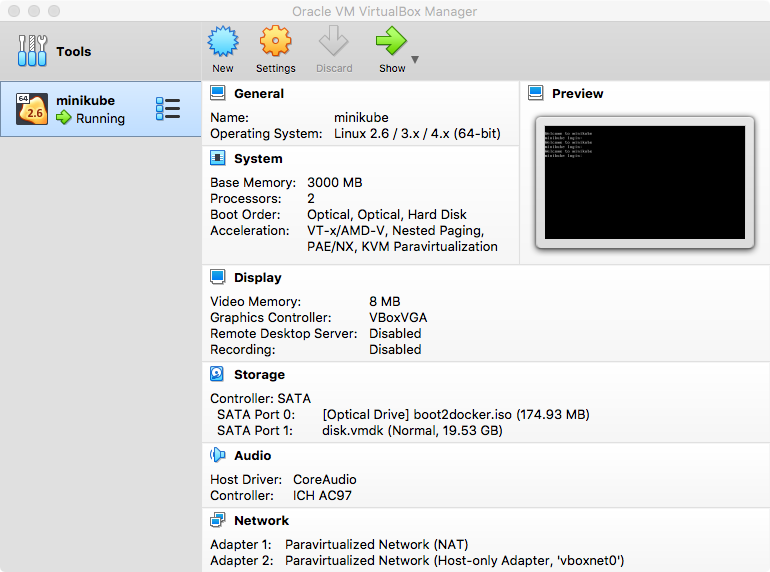
there’s quite a lot going on and not very much to see; you don’t even need to look at VirtualBox as it’s running ‘headless’, but if you open it up you can see the new running VM and its settings:
these values are all set to sensible defaults, but you may want to tweak things like memory or cpu allocations – running
minikube config -h
should help you see what to do, for example
minikube start --memory 1024
to change the allocated memory.
If you then take a look at the config file in ~/.minikube/config/config.js you will see how your preferences – resource limits, addons etc – are persisted and managed there.
Looking back at VirtualBox, if you click on “Show” or the running VM you can open that up to see the console for the Minikube VM:
to stop the vm simply do a minikube stop, or just type minikube to see a list of args and options to manage the lifecycle, e.g. minikube delete, status, pause, ssh and so on.
Minikube Addons
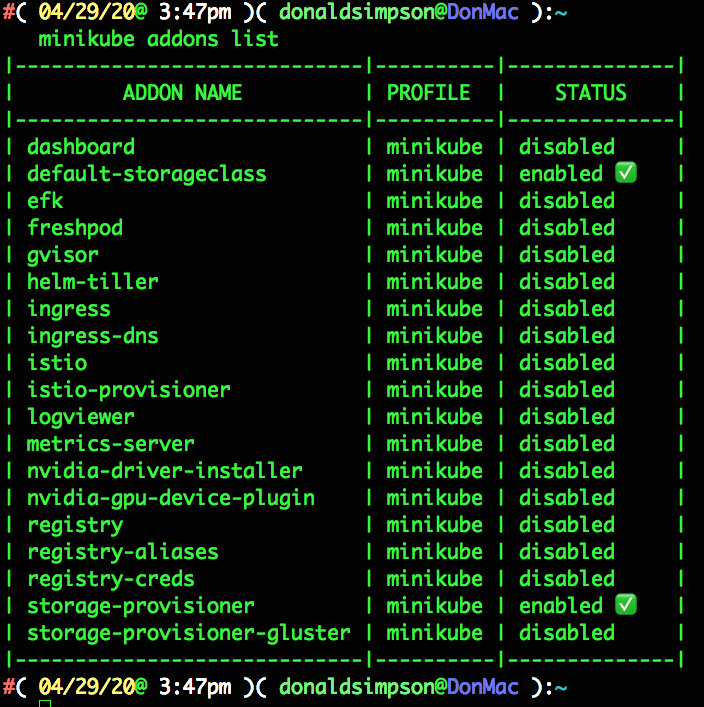
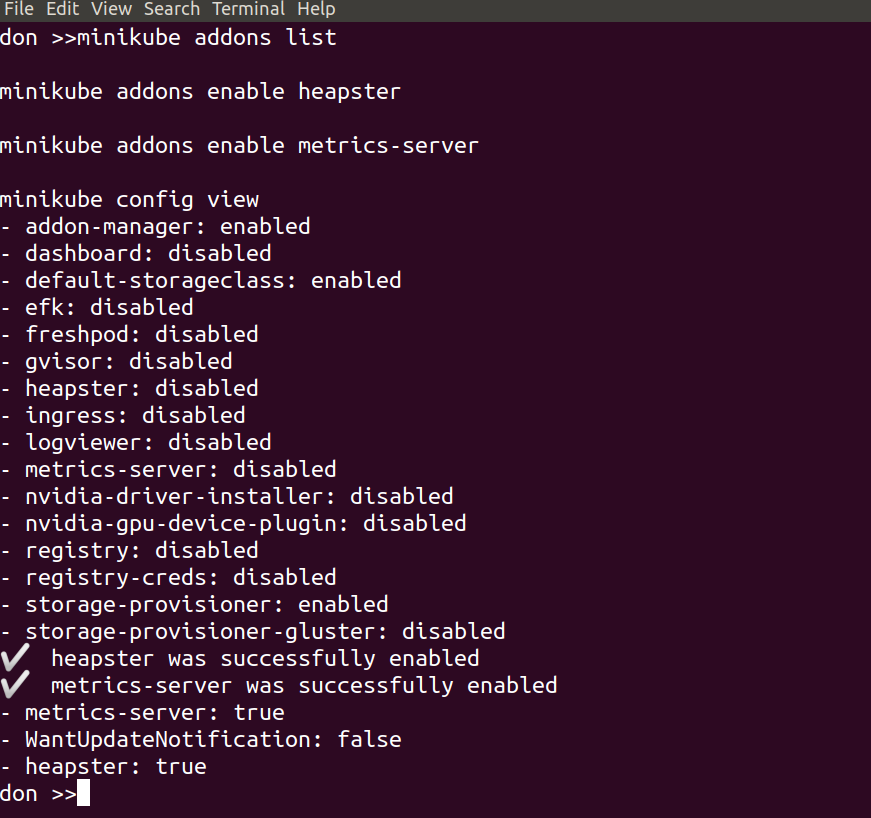
One of the handy features Minikube provides are its selection of easy to use addons. As explained in the official docs here you can see the list and current status of each addon by typing minikube addons list
the storage-provisioner and default-storeageclass addons were automatically enabled on startup, but I usually like to add the metrics server and dashboard too, like so:
I often use helm & tiller, efk, istio and the registry too – this feature save me a lot of time and messing about!
Accessing the Kubernetes Dashboard – all done!
Once that’s completed you can run minikube dashboard to open up the Kubernetes dashboard on your host.
Minikube makes this all very easy; we didn’t have to forward ports, configure firewalls, consider ingress and egress, create RBAC roles, manage accounts/passwords/keys or set up DNS, or any of the many things you would normally want or have to consider to get to this point.
These features make Minikube a great choice for development work, where you don’t want to care about things like this as you would in a “for real” environment.
Your browser should open up the Kubernetes Dashboard, and you can click around and see the status of the many components that comprise your new Kubernetes cluster:
And then…
Next up I’ll be building on this setup by deploying a Jenkins instance inside the Kubernetes Cluster, then configuring that to use Kubernetes to build, manage and deploy applications on the same Kubernetes Cluster.
This post looks at creating and maintaining HTTPS/SSL/TLS Certificates for multiple WordPress sites running on the same host.
Some background…
This website is one of several different domains/sites/blogs hosted on my single Google Cloud server, with one public IP address shared for all websites. I’m using WordPress Multisite to do this, based on a very well put together Appliance provided by Bitnami.
WordPress Multisite allows me to cheaply, easily and efficiently serve multiple sites from the one host and IP address, sharing the same host resources (CPU, Mem, Disk) which is great but makes seting up HTTPS/SSL Certificates a little different to the norm – the same cert has to validate multiple sites in multiple domains.
I’d banged my head against this for a while and looked at many different tools and tech (some of which are mentioned below) to try and sort this out previously, but finally settled on the following process which works very well for my situation.
“WordPress is the world’s most popular blogging and content management platform. With WordPress Multisite, conserve resources by managing multiple blogs and websites from the same server and interface.”
CERT PROVIDER
Let’s Encrypt is a free, automated, and open Certificate Authority created by the Linux Foundation in collaboration with the Internet Security Research Group. There are many other certificate providers available, but I’m using this one.
Once lego is set up, you can request multiple certs like this – just make sure to change the --domains="whatever" entries and add as many as you need. Remember all of your sub domains (www. etc) too.
sudo lego --tls --email="my@email.com"--domains="donaldsimpson.co.uk" --domains="www.donaldsimpson.co.uk" --domains="www.someothersite.com" --domains="someothersite.com" --path="/etc/lego" run
Noe you’ve got the certs, move them in to place and chmod them etc:
By this point I was happy that the nice new HTTPS certs were finally working reliably for all of my sites, but was aware that Google and external links would still try to get in through HTTP URLs.
After trying a few WordPress plugins that sounded like they should correct this neatly for me, I settled on JSM’s Force SSL/HTTPS plugin. As the name suggested, it quickly and easily redirects all incoming HTTP requests to HTTPS. It was simple to install and setup and works very well with WordPress Multisite too – thanks very much JSM!
CRONJOB
Now that the process works, the certificates need updated every 90 days which would be a bit of a pain to remember and do, so adding a simple script to a cron job saves some hassle.
Helm and Tiller – what they are, when & why you’d maybe use them
Helm and Tiller – prep, install and Helm Charts
Deploying Jenkins via Helm Charts
and WordPress w/MariaDB too
Wrap up
The below are mostly my technical notes from this session, with some added blurb/explanation.
Helm and Tiller – what they are, when & why you’d maybe use them
From the Helm site:
“Helm helps you manage Kubernetes applications — Helm Charts help you define, install, and upgrade even the most complex Kubernetes application. Charts are easy to create, version, share, and publish — so start using Helm and stop the copy-and-paste.”
Helm is basically a package manager for Kubernetes applications. You can choose from a large list of Stable (or not so!) ready made packages and use the Helm Charts to quickly and easily deploy them to your own Kubernetes Cluster.
This makes light work of some very complex deployment tasks, and it’s also possible to extend these ready-made charts to suit your needs, and to write your own Charts from scratch, or pass your own values to override default ones, or… many other interesting options!
For this session we are looking at installing Helm, reviewing some example Helm Charts and deploying a few “vanilla” ones to the cluster we created in the first half of the session. We also touch upon the life-cycle of Helm Charts – it’s similar to dockers – and point out some of the ways this could be extended and customised to suit your needs – more on this at a later date hopefully.
Helm and Tiller – prep, install and Helm Charts
First, installing Helm – it’s as easy as this, run on your laptop/host that’s running the Minikube k8s we setup earlier:
Tiller is the client part of Helm and is deployed inside your k8s cluster. It’s set to be removed with the release of Helm 3, but the basic functionality wont really change. More details here https://helm.sh/blog/helm-3-preview-pt1/
Next we do the Tiller prep & install – add RBAC for tiller, deploy via helm and take a look at the running pods:
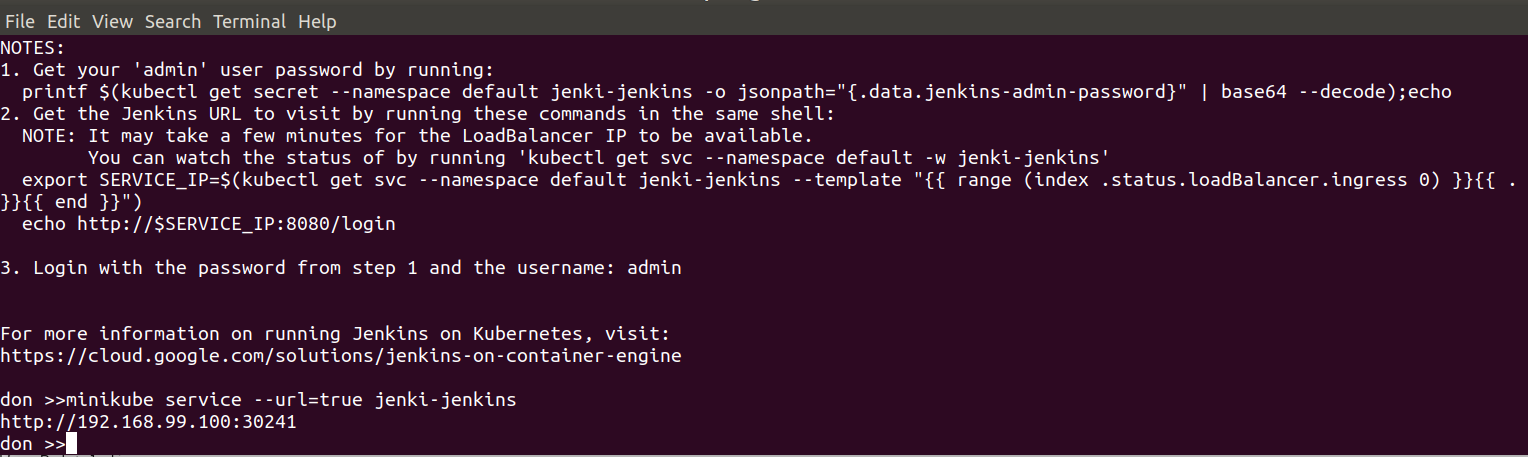
now get the URL for the Jenkins service from Minikube:
minikube service --url=true jenki-jenkins
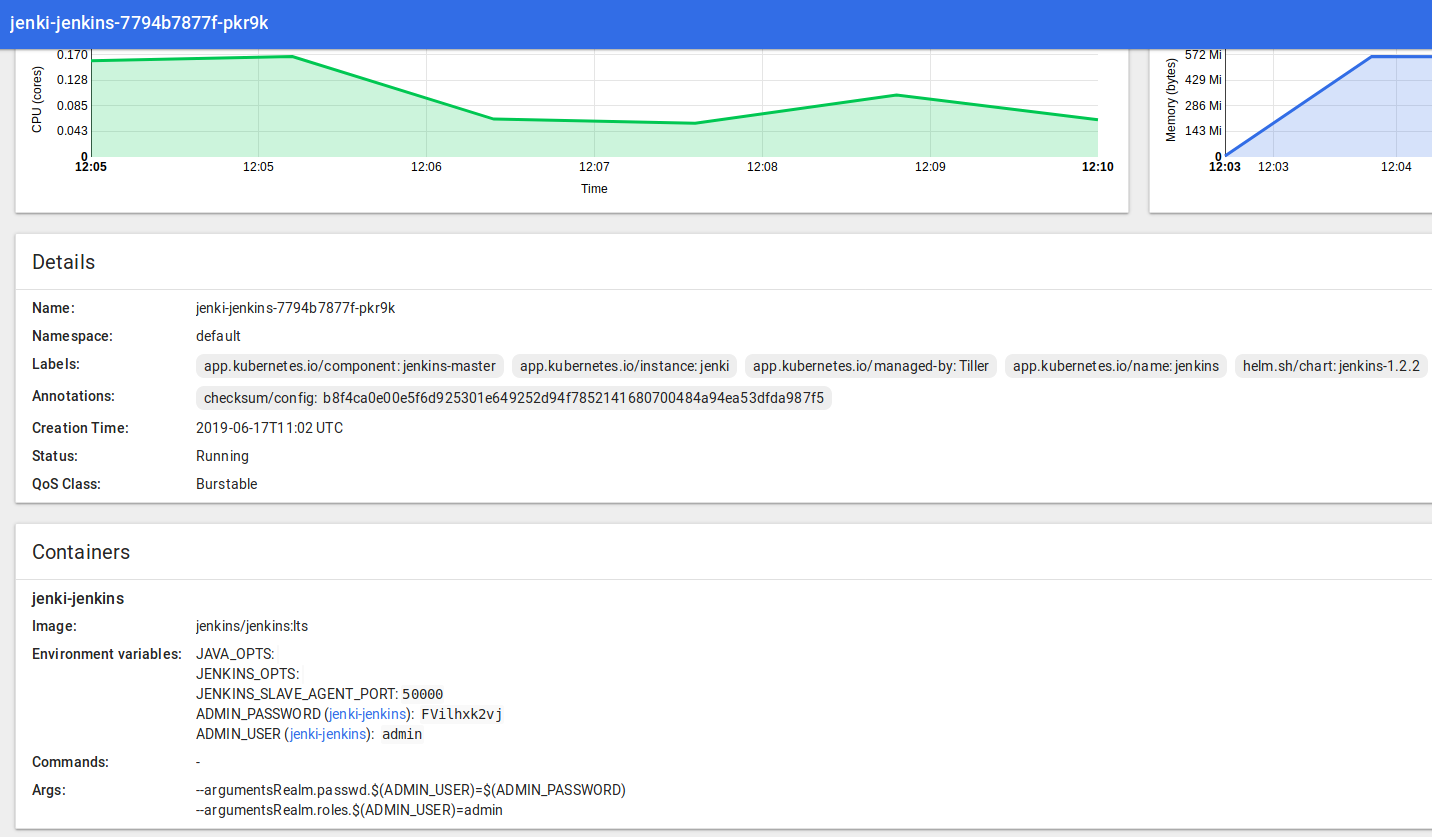
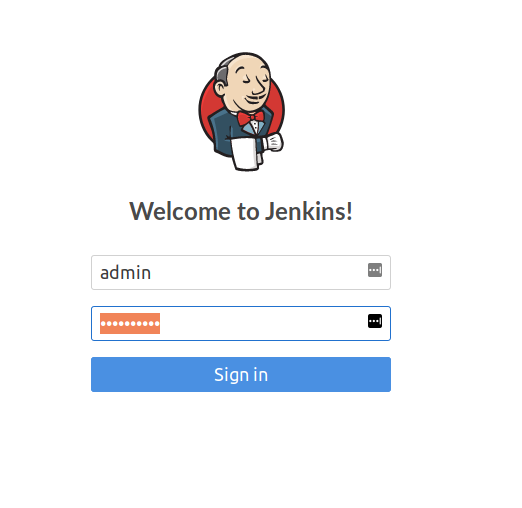
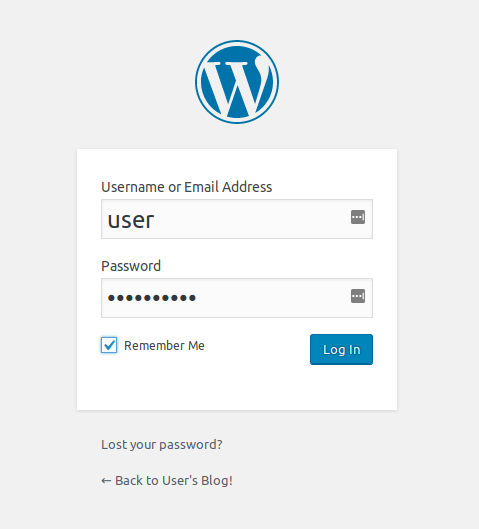
Hit that URL in your browser, and grab the password in UI from Pods > Jenki and log in to Jenkins with the user “admin”:
That’s a Jenkins instance deployed via Helm and Tiller and a Helm Chart to our Kubernetes Cluster running inside Minikube via a VirtualBox VM… all done in a few minutes. And it’s all customisable, repeatable, highly scaleable and awesome.
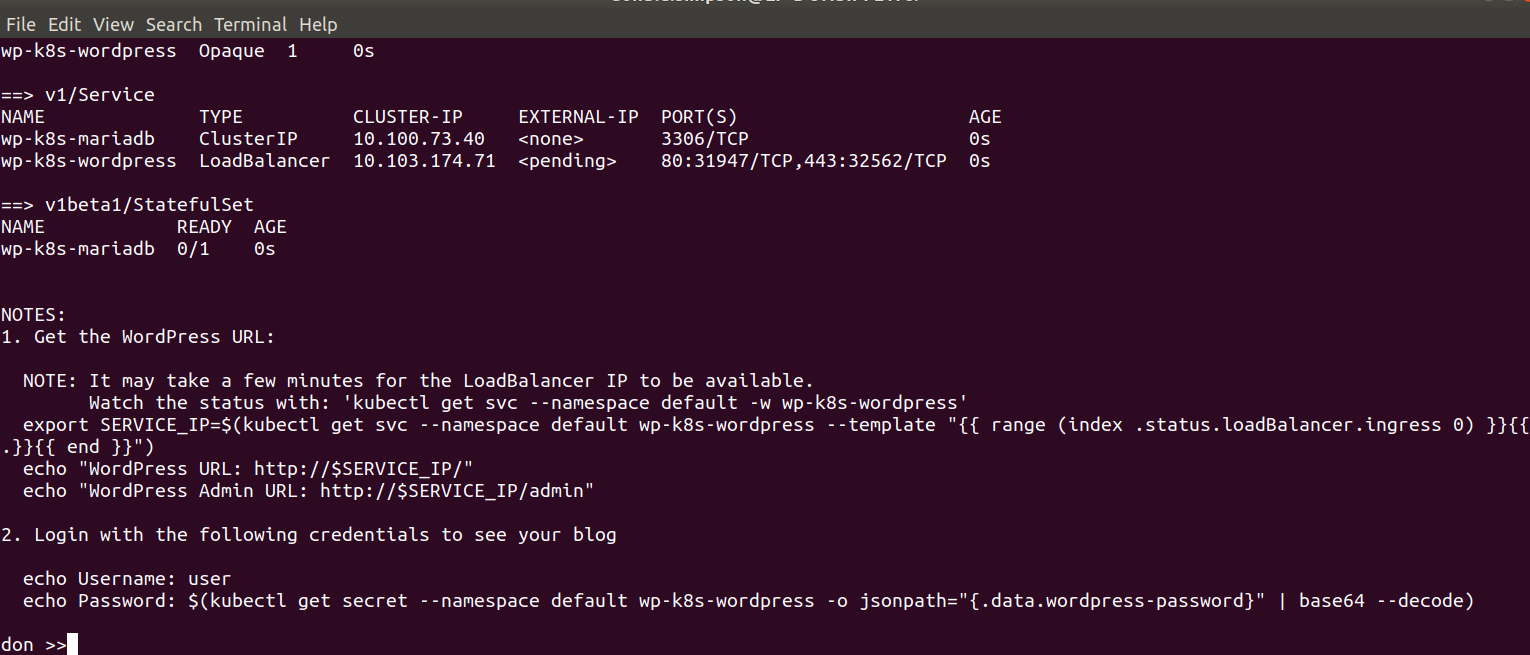
and WordPress w/MariaDB too
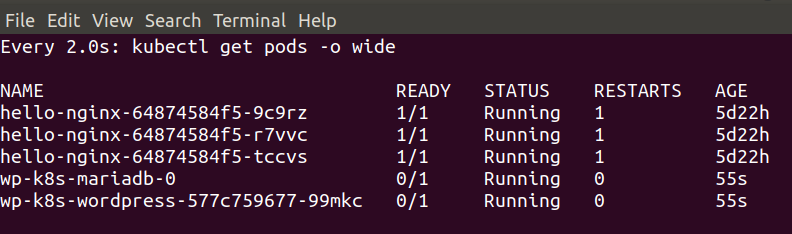
This was the “bonus demo” if my laptop wasn’t on fire – and thanks to some rapid cleaning up it managed fine – showing how quickly we could deploy a functional WordPress with MariaDB backend to our k8s cluster using the Helm Chart.
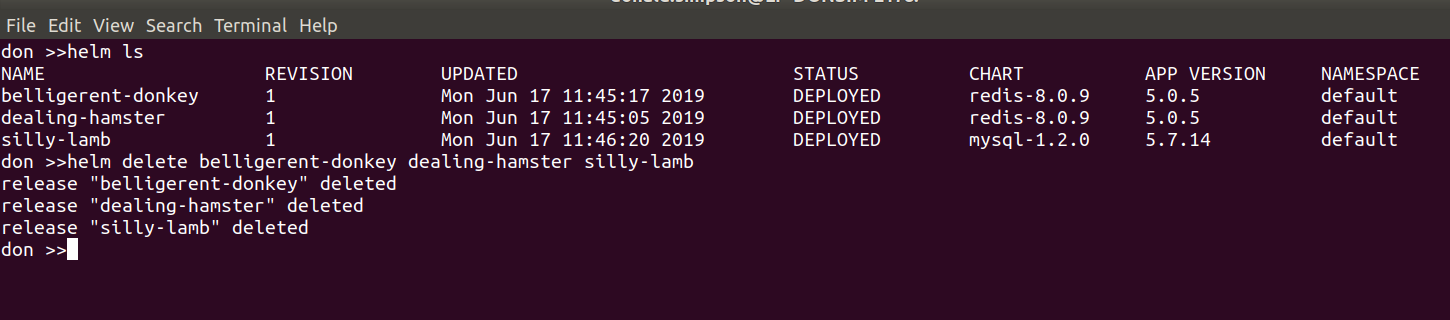
To prepare for this I did a helm ls to see all the things I had running. then helm delete --purge jenki, gave it a while to recover then had to do
kubectl delete pods <jenkinpod>
before starting the WordPress Chart deployment with
That’s it – we covered a lot in this session, and plan to use this as a platform to explore Helm in more detail later, writing our own Helm Charts and providing our own customisations to them.
Update: this follow-on post runs through setting up Jenkins with Helm then creating Jenkins Pipelines that dynamically provision dockerised Jenkins Agents:
This is the first of two posts on Kubernetes and HelmCharts, focusing on setting up a local development environment for Kubernetes using Minikube, then exploring Helm for package management and quickly and easily deploying several applications to the cluster – NGINX, Jenkins, WordPress with a MariaDB backend, MySQL and Redis.
The content is taken from the practical/demo session I wrote and published in Github here:
One of the key objectives and challenges here was getting a useful local Kubernetes environment up and running as quickly and easily as possible for as wide an audience as we could- there’s so much to the Kubernetes ecosystem that it’s very easy to get side-tracked, and we could have (happily) spent a long time discussing the myriad of alternative possible solutions.
We plan to go “deeper” on all of this in future sessions and have an in-depth Helm session in the works, but for this session we were focused on creating a practical starting point.
</ramble>
Don
What is covered here:
Minikube – what it is (& isn’t) & why you’d use it (or not)
Kubernetes and Minikube components and concepts
setup for Mac and Linux
creating a first Kubernetes cluster in Minikube
minikube addons – what they are and how they can help you
minikube docker env – using DOCKER_HOST with minikube VM
Kubernetes dashboard with Heapster and Metrics Server – made easy by Minikube
kubectl – some examples and alternatives
example app – “hello (Kubernetes) world” minikube style with NGINX, scaling your world
Helm and Tiller – what they are, when & why you’d maybe use them
Helm and Tiller – prep, install and Helm Charts
Deploying Jenkins via Helm Charts
and WordPress w/MariaDB too
wrap up
Minikube – what it is (& isn’t) & why you’d use it (or not)
What it is, why you’d use it etc.
Local development of k8s – runs a single node Kubernetes cluster in a Virtual Machine on your laptop/PC.
All about making things easy for local development, it is not a production solution, or even close to it.
There are many other ways to run k8s, they all have their pros and cons and use cases. The slides from the Meetup covered this in more detail and include links for further info – they are available here:
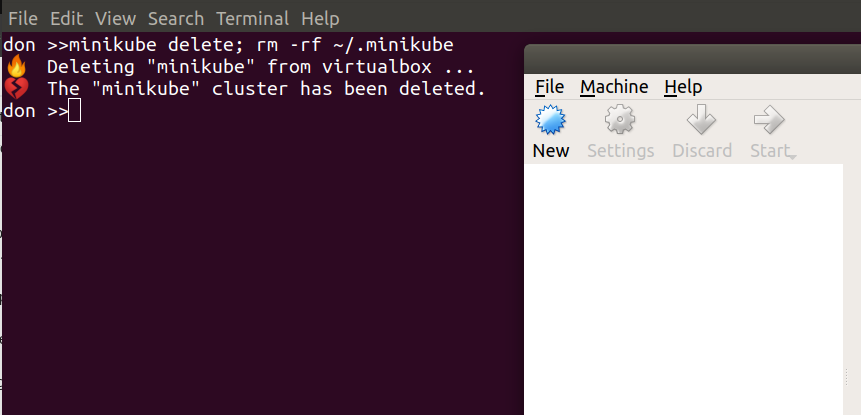
Cleanup/prep – if required, remove any previous cluster & settings
`minikube delete; rm -rf ~/.minikube`
Creating a first Kubernetes cluster in Minikube
Here we create a first Kubernetes cluster with Minikube, then take a look around in & outside of the VM.
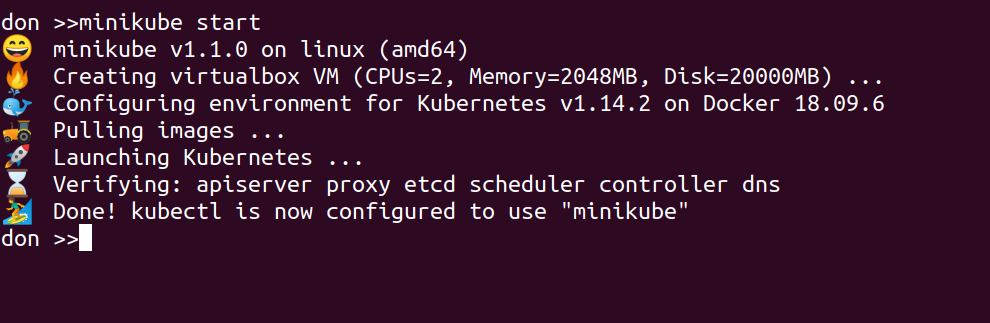
With the above initial setup done, it’s as simple as running this in a shell:
minikube start
Note you could optionally give this Cluster a name, if you are likely to have more than one for different branches of development for example. This is also where you could specify the VM provider if you want to use something other than VirtualBox – there are more details here:
This should produce output like the following, and it may well take a few minutes as the VM is downloaded and started, then a stack of Docker images are started up inside that….
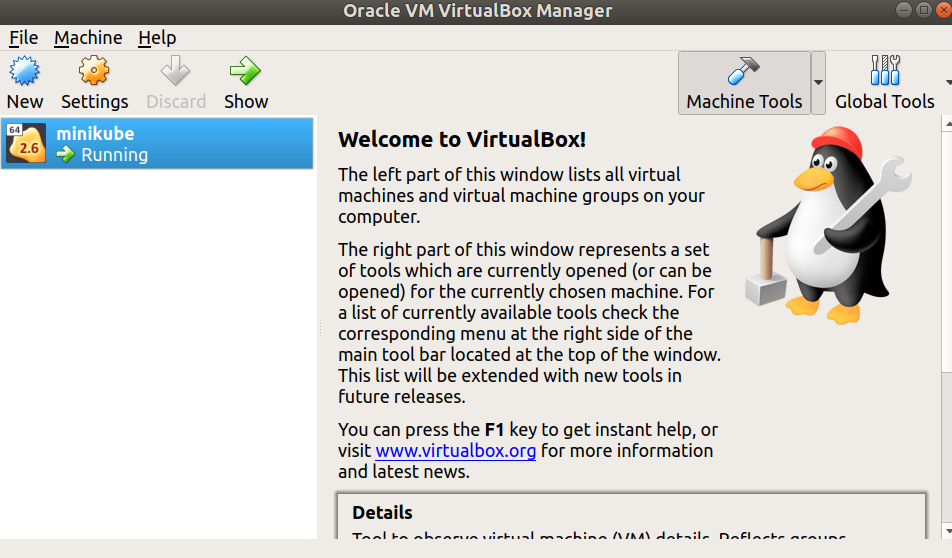
At this point you should be able to see the minikube VM running in the VirtualBox GUI:
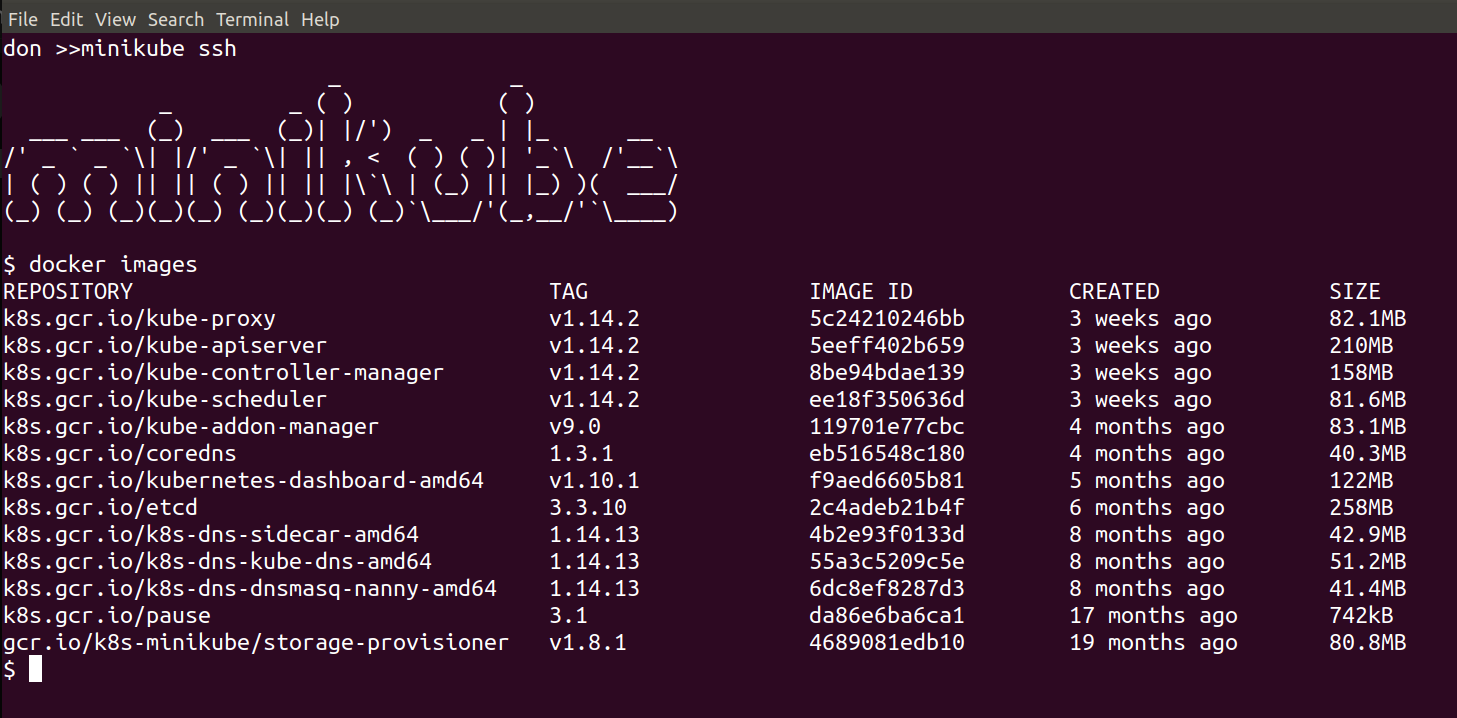
Now it’s running, we can connect from our local shell directly to the one inside the running VM by simply issuing:
minikube ssh
This will put you inside the VM where the Kubernetes Cluster is being run, and we can see and interact with the running components, for example:
docker images
should show all of the downloaded images:
and you could do this to see the running containers:
docker ps
Quitting out of the VM puts us back on the local host, where we can use kubectl to query the status of the Minikube cluster – the initial setup has told kubectl about the Minikube-managed Kubernetes Cluster, meaning there’s no other setup required here:
kubectl cluster-info
kubectl get nodes
kubectl describe nodes
minikube addons – what they are and how they can help you
Show some of the ways minkube makes things easier for local dev
First, take a moment to look around these two local folders:
ls -al ~/.minikube; ls -al ~/.kube
These are where Minikube keeps its settings and the VM Image, and where kubectl settings are persisted – and updated by Minikube.
With Minikube you’ve often got the option to either use kubectl directly, or to use some Minikube built-in features to make your life easier.
Addons are one of these features, allowing you to very easily add – or remove – functionality from the cluster like this:
minikube addons list
minikube addons enable heapster
minikube addons enable metrics-server
With those three lines we’ve taken a look at the available addons and their current status, and selected to enable both heapster and the metrics server. This was done to give us cpu and mem stats in the Kubernetes Dashboard, which we will set up in a moment. The output should look something like this:
minikube config view
shows the current state of the config – i.e. what changes have been made, so we can keep a track of them easily.
kubectl --namespace kube-system get pods
now we can enable the dashboard:
minikube addons enable dashboard
and check again to see the current state
minikube addons list
we’ll connect to the Dashboard and take a look around in a moment, but first…
minikube docker env – using the DOCKER_HOST in you minikube VM – how & why
Minikube docker-env – setup local docker client to use minikube docker host
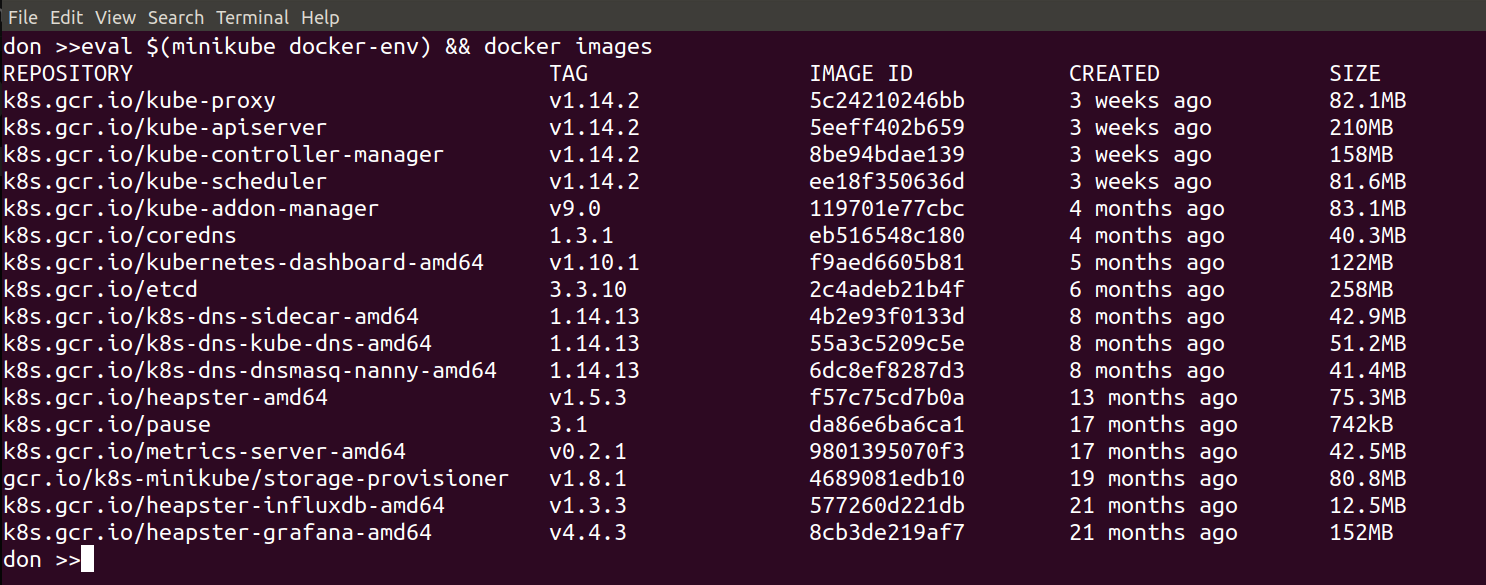
We’re going to look at connecting our local docker client to the docker host inside the Minikube VM. This is made easy by:
minikube docker-env
if you run that command on its own it wiull show you what settings it will export and you can set them by doing:
eval ${minikube docker-env}
From then on, in that shell, your local docker commands will use the docker host inside Minikube.
This is very useful for debugging and local development – when you change and deploy anything to your Kubernetes Cluster, you can easily tail the logs or check for errors or issues. You can also do all of this via the dashboard or kubectl too if you prefer, but it’s another handy and powerful feature from Minikube.
The following image shows the result of running this command:
so we can now use our local docker client to run docker commands like…
docker ps
docker ps | grep -i metrics
docker logs -f <some container id>
etc.
Kubernetes dashboard with Heapster and Metrics Server – made easy by Minikube
Minikube k8s dashboard – here we will start up the k8s dashboard and take look around.
We’ve delayed starting the dashboard up until after we enabled the metrics-server & heapster components we deployed earlier. By doing it in this order, the dashboard will automatically detect and use these components, giving us cpu & mem stats and a nicer looking dash, with no additional config required.
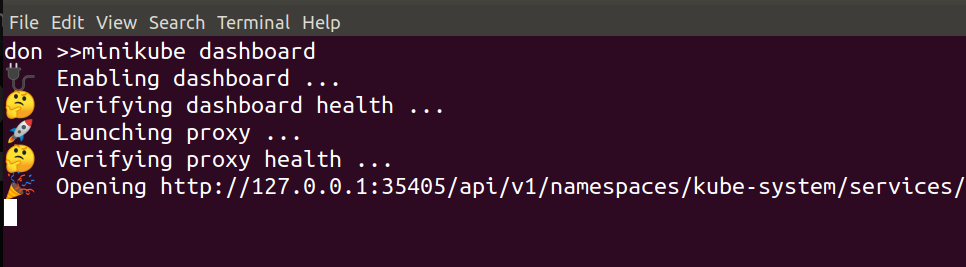
Starting the dashboard simply involved running
minikube dashboard
and waiting for a minute…
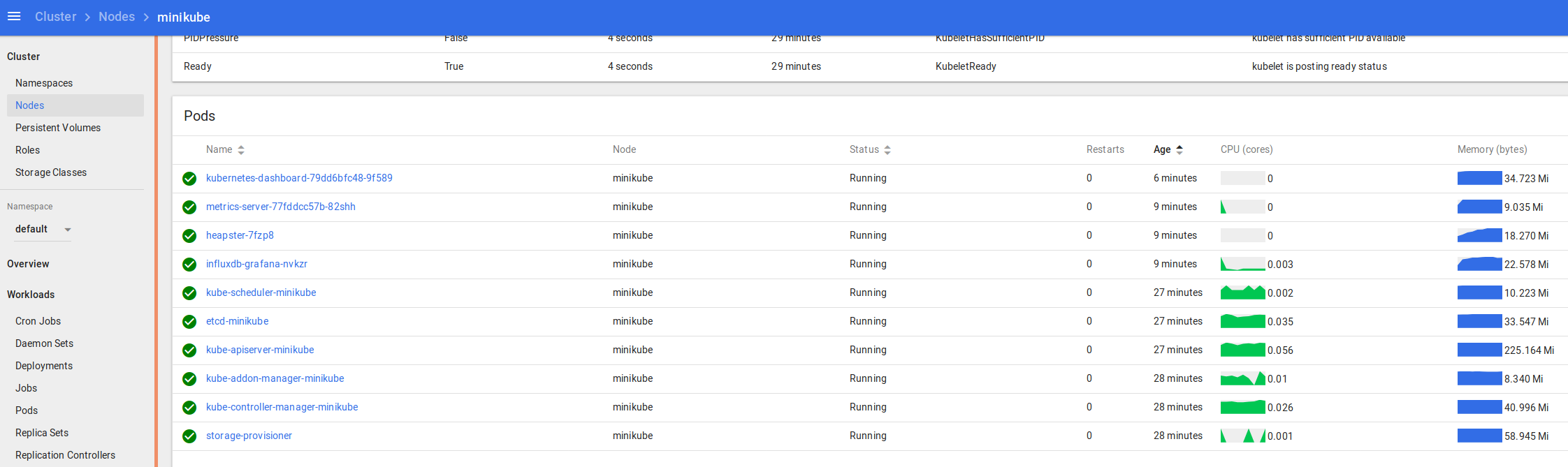
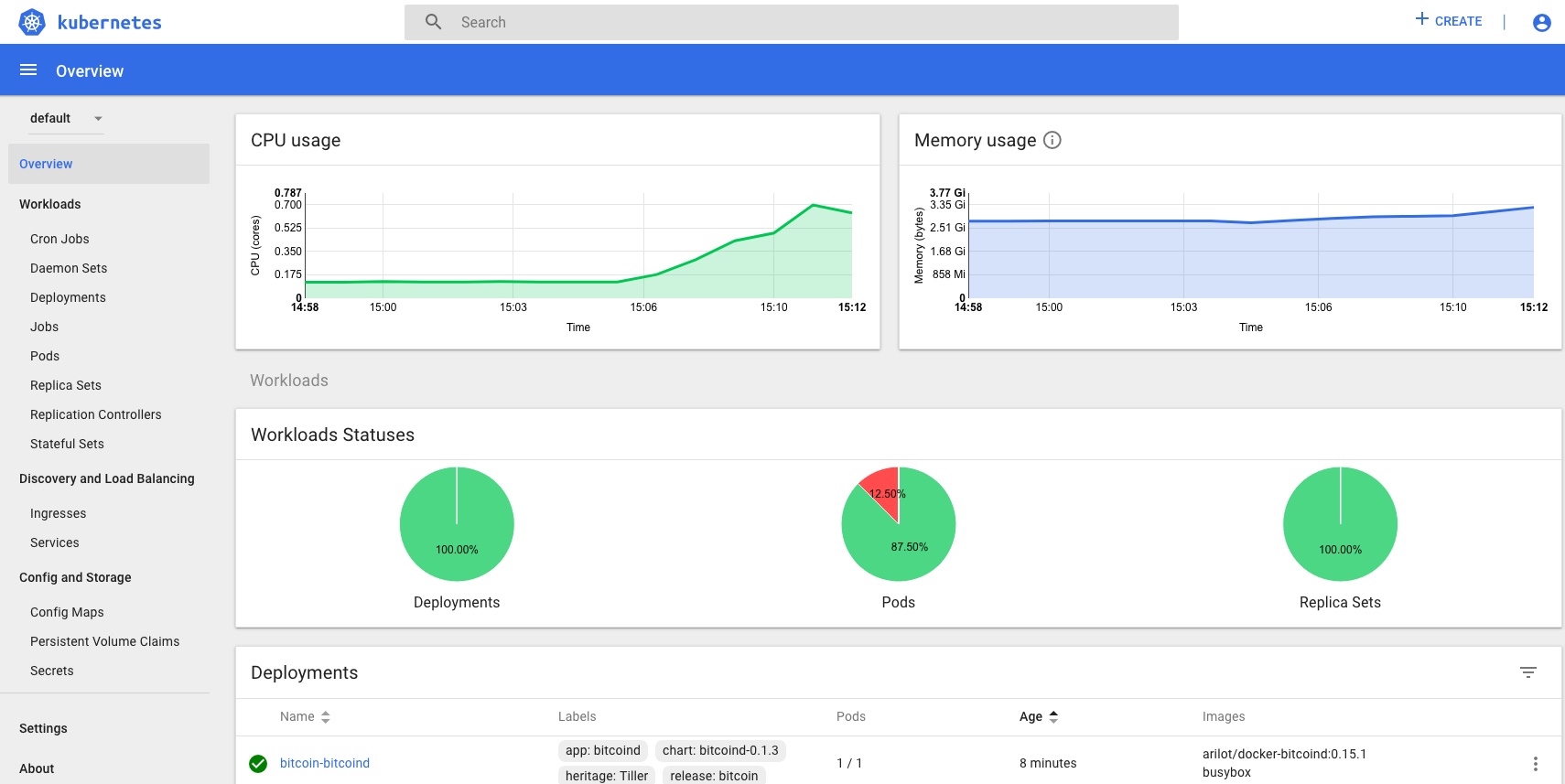
That should fire up your browser automatically, then you can take a look around at things like Default namespace > Nodes
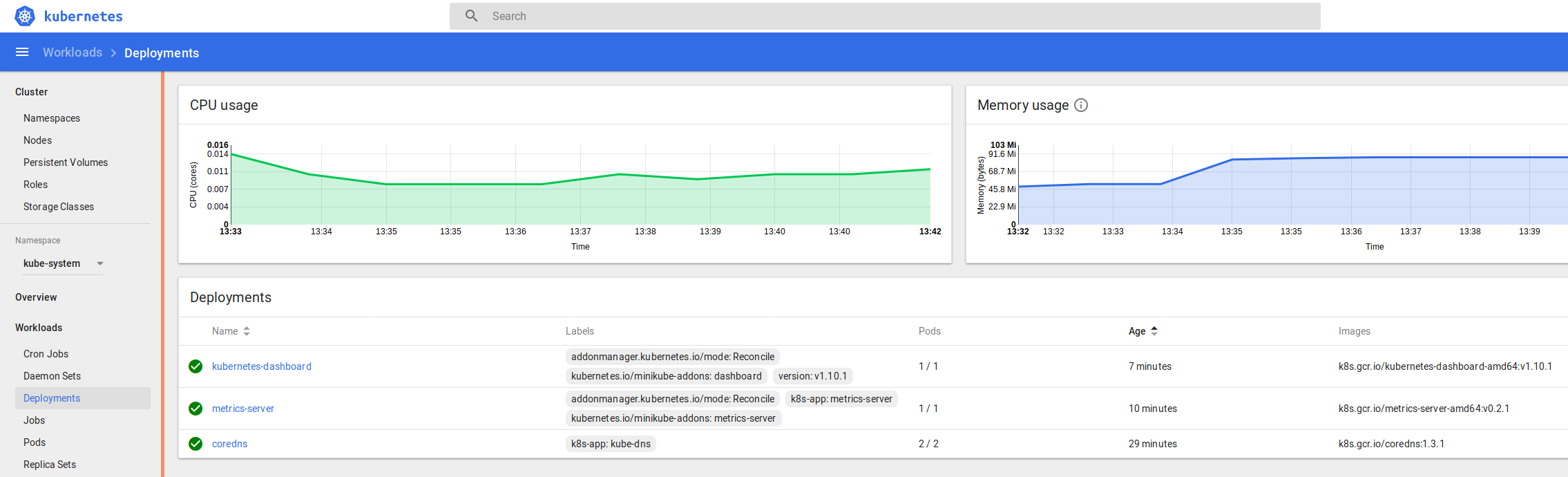
and in the namespace kube-system > Deployments
and kube-system > Pods
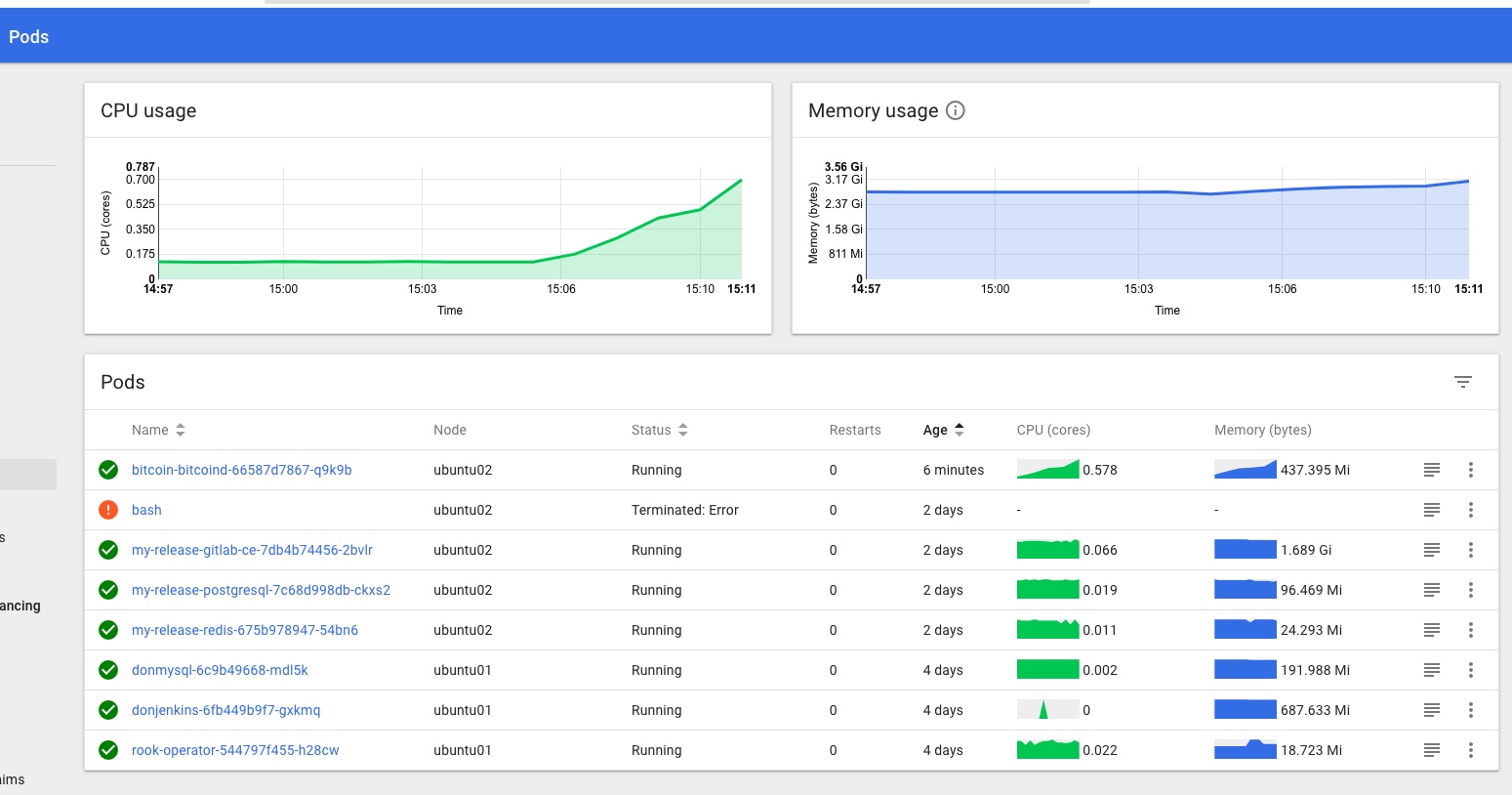
You can see the logs and statuses of everything running in your k8s cluster – from the core components we covered at the start, to the dashboard, metrics and heapster we enabled recently, and the application we’re going to deploy and scale up soon.
kubectl – some examples and alternatives
# kubectl command line – look at kubectl and keep an eye on things kubectl get deployment -n kube-system
kubectl get pods -o wide -n kube-system
kubectl get services
kubectl
example app – “hello (Kubernetes) world” minikube style with NGINX, scaling your world
Now we’ll deploy the most basic application we can – a “Hello World” style NGINX docker image.
It’s as simple as this, where nginx is the name of the docker image you want to deploy, hello-nginx is the label you want to give it, and port 80 is where you want it to listen:
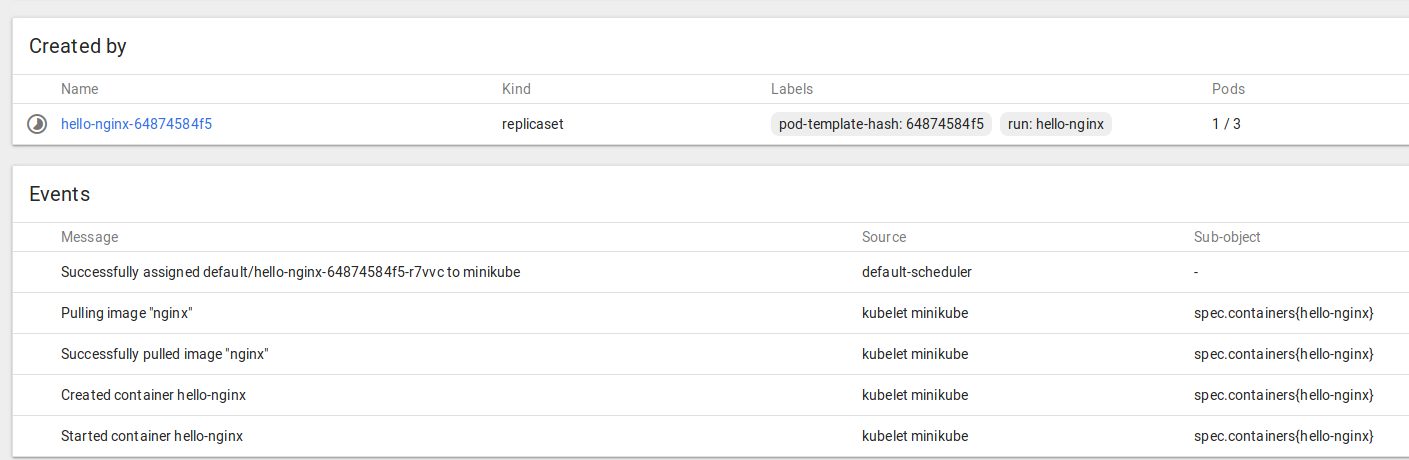
kubectl run hello-nginx --image=nginx --port=80
that shouldn’t take long, and you can watch the progress like this:
We are presenting a Kubernetes-related Meetup on Wednesday 5th June in Edinburgh.
This time we explore setting up a local development environment for Kubernetes using Minikube and Helm Charts. We will deploy NGINX to the Cluster and scaled it up and down, then use Helm Charts to deploy Jenkins, WordPress and MariaDB.
if you’d like to join in please book a space via our Meetup (below) – it’s free, and the Peoples Postcode Lottery are kindly hosting the event and providing the beer and pizza too! Wednesday 5th June 2019 from 6:30 PM in the Peoples Postcode Lottery offices at 28 Charlotte Square in Edinburgh.
Kubernetes – getting started with Minikube, Helm and Tiller
Wednesday, Jun 5, 2019, 6:30 PM
Wemyss House 28 Charlotte Square Edinburgh, GB
38 Members Went
In collaboration with Hays and the People’s Postcode Lottery, Automated IT Solutions are running a Meetup on Kubernetes with Minikube, Helm and Tiller. The session starts off with an overview of the main Kubernetes concepts and components, then runs through building your own local Kubernetes Cluster with Minikube. After deploying and scaling our fi…
I have been planning this session for ages, and hope that it will become the basis for several future talks and ideas, including deploying Blockchain to a Kubernetes cluster, then adding a Ruby and Sinatra based application that will use it.
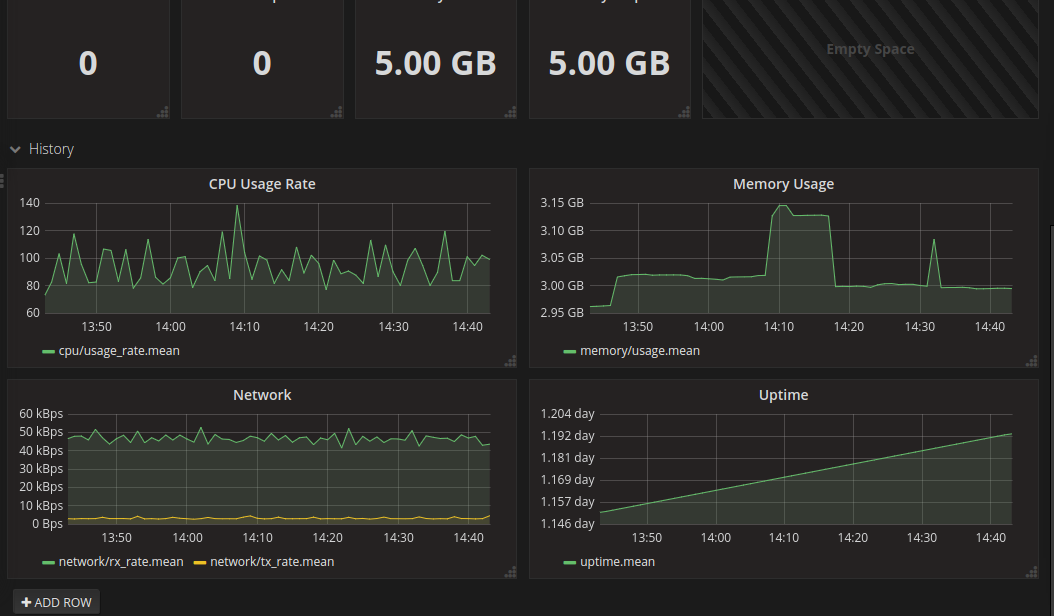
What was a little trickier, was getting live stats for my cluster – cpu and mem load etc – to show up inside the dashboard, so that you can see the status of the various deployments and pods on your cluster at a glance from one central location.
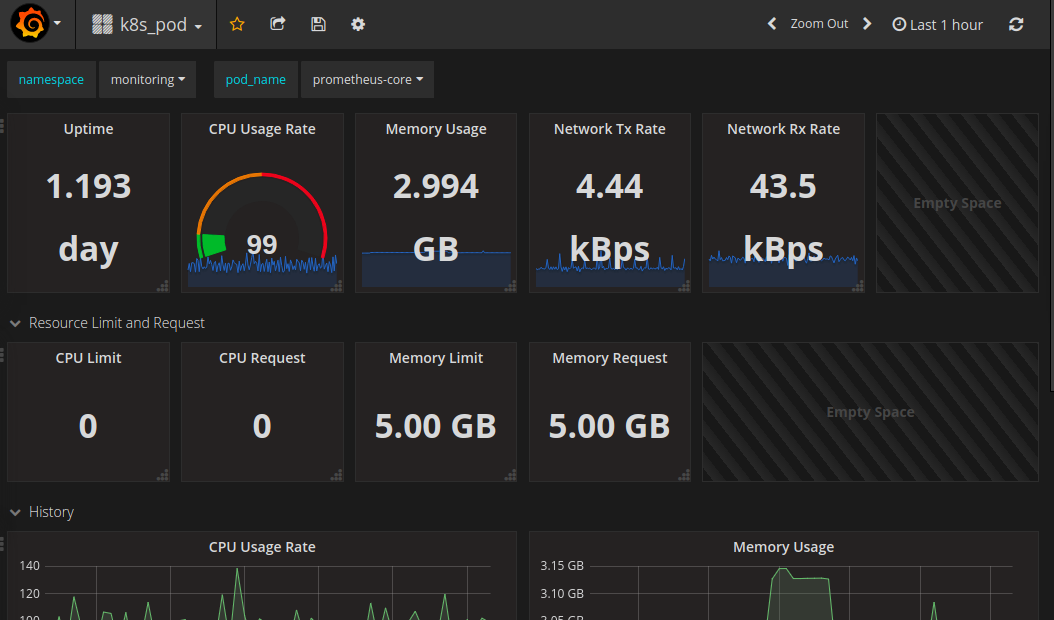
This combination of tools also makes it easy to add on Grafana dashboards that display whatever cluster stats you want from InfluxDB or Prometheus via Heapster, producing something along these lines:
This post documents the steps I took to get things working the way I want them.
Adding Heapster to a Kubernetes Cluster
I’ve used Heapster before and found it did everything I wanted without any problem, especially with an InfluxDB backend, but it’s now being deprecated and replaced with the new metrics-server (and others), which at the time I was doing this doesn’t integrate with the kubernetes dashboard so wouldn’t give me the stats I was looking for., which are this kind of thing…
and this
Note that it’s slightly easier to get Heapster stats working first, then when you add on the dashboard it’ll pick them up.
Heapster can be installed using the default project here, but it will not work with the current/latest version of Kubernetes Dashboard like that, and some changes are needed to make the two play nicely together.
and created my own fork of the official Heapster repo with the recommended changes then made to it, so now I can then simply (re)apply those settings whenever I rebuild my Cluster, and things should keep working.
Note that it may take a while for things to start happening…
The simplest test to see when/if Heapster is working is to check with kubectl top against a node or pod like so:
ansible@umaster:~$ kubectl top node umaster NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% umaster 144m 3% 3134Mi 19%
ansible@umaster:~$ kubectl top node ubuntu01 NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ubuntu01 121m 6% 2268Mi 59% ansible@umaster:~
If you get stats something like the above back things are looking good, but if you get a “no stats available” message, you’ve got some fundamental issues. Time to go check the logs and look for errors. I had quite a series of them until I made the above changes, including many access verboten errors like:
reflector.go:190] k8s.io/heapster/metrics/util/util.go:30: Failed to list *v1.Node: nodes is forbidden: User “system:serviceaccount:kube-system:heapster
Kubernetes Dashboard with user & permissions sorted
I then restarted the dashboard pod to pick up the changes:
kubectl delete pod kubernetes-dashboard-57df4db6b-4tcmk --namespace kube-system
Now it should be time to test logging in to the Dashboard. If you don’t have a service endpoint created already/automatically, you can find and do a quick test via the current NodePort by running
kubectl -n kube-system get service kubernetes-dashboard
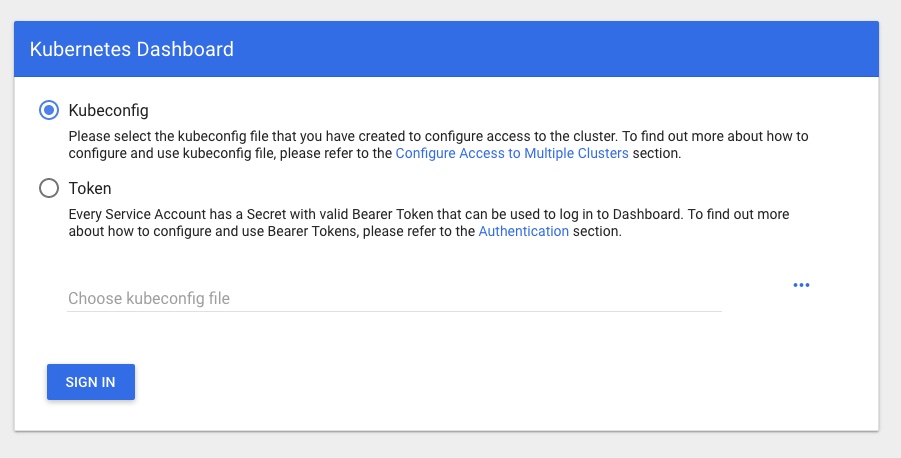
Then hit your cluster IP with that PORT in your browser and you should see a login page like:
Presenting the next hurdle… how to log in to your nice new Dashboard and see all the shiny new info and metrics!
Run sudo kubectl -n kube-system get secret and look/grep for something starting with “kubernetes-dashboard-token-” that we created above. Then do this to get the token to log in with full perms:
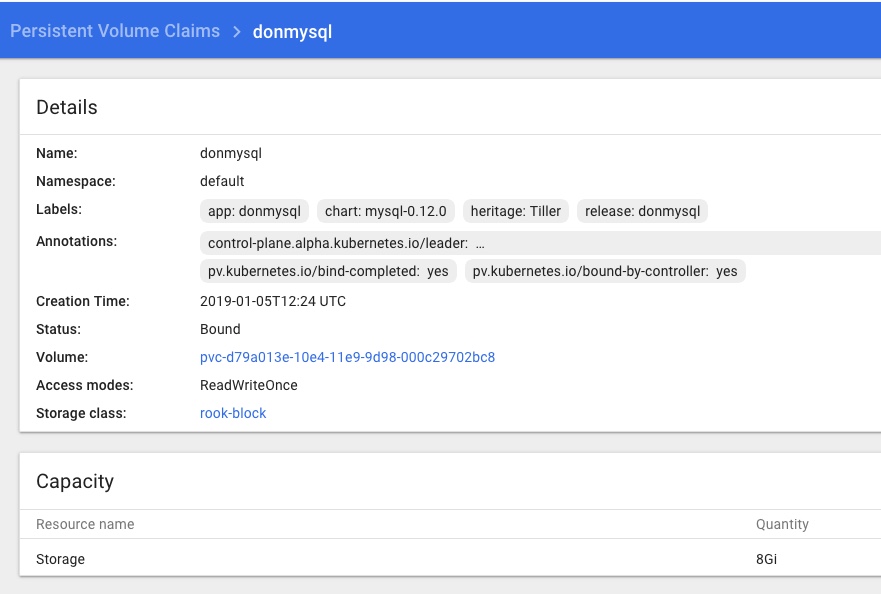
There was an obvious flaw in the example MySQL Chart I deployed via Helm and Tiller, in that the required Persistent Volume Claims could not be satisfied so the pod was stuck in a “Pending” state for ever.
Adding Persistent Storage
In this post I will sort that out, by adding Persistent Storage to the Cluster and redeploying and testing the same Chart deployed via “helm deploy stable/mysql“. This time, it should be able to claim all of the resources it needs with no tweaking or hints supplied…
First a few notes on some of the commands and tools I used for troubleshooting what was wrong with the mysql deploy.
watch -d 'sudo kubectl get pods --all-namespaces -o wide'
watch -d kubectl describe pod wise-mule-mysql
kubectl attach wise-mule-mysql-d69788f48-zq5gz -i
The above commands showed a pod that generally wasn’t happy or connectable, but little detail.
Running “kubectl get events -w” is much more informative:
LAST SEEN TYPE REASON KIND MESSAGE 17m Warning FailedScheduling Pod pod has unbound immediate PersistentVolumeClaims 17m Normal SuccessfulCreate ReplicaSet Created pod: quaffing-turkey-mysql-65969c88fd-znwl9 2m38s Normal FailedBinding PersistentVolumeClaim no persistent volumes available for this claim and no storage class is set 17m Normal ScalingReplicaSet Deployment Scaled up replica set quaffing-turkey-mysql-65969c88fd to 1
and doing “kubectl describe pod <pod name>” is also very useful:
<snip a whole load of events and details> Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 5m26s (x2 over 5m26s) default-scheduler pod has unbound immediate PersistentVolumeClaims
Making it pretty clear what’s going on and exactly what is noticeably absent from the Cluster.
My initial plan had been to use GlusterFS and Heketi, but having dabbled with this before and knowing it wasn’t really something I wanted to do for this use case, it was a bit of Yak Shaving I’d really like to avoid if possible.
So, I had a look around and found “Rook“. This sounded much simpler and more suited to my needs. It’s also open source, Apache licensed, and works on multi-node clusters. I’d previously considered using hostPath storage but it’s a bit too basic even for here, and would restrict me to a single node cluster due to the (lack of) replication, missing a lot of the point of a Cluster, so I thought I’d give Rook a shot.
I tried to follow this but had some issues, which I will try and clarify when I run through this again – I’d made a bit of a mess trying a bit of Gluster and some hostPath and messing about with the default storage class etc, so it was quite possibly “just me”, and not Rook to blame here 🙂 This is some of my shell history:
I definitely ran through this more than once, and I think it also took a while for things to start up and work – the subsequent runs went much better than the initial ones anyway. I also applied a few patches to the rook user and storage class (below) – these and many other alternatives were recommended by others facing similar sounding issues, but I think for me the fundamental is solved further below, re the rbd binary missing from $PATH, and installing ceph:
kubectl get secret rook-rook-user -oyaml | sed "/resourceVer/d;/uid/d;/self/d;/creat/d;/namespace/d" | kubectl -n kube-system apply -f -
kubectl get secret rook-rook-user -oyaml | sed "/resourceVer/d;/uid/d;/self/d;/creat/d;/namespace/d" | kubectl -n default -f -
kubectl get secret rook-rook-user -oyaml | sed "/resourceVer/d;/uid/d;/self/d;/creat/d;/namespace/d" | kubectl -n default apply -f -
That all done, I still had issues with my pods, specifically this error:
MountVolume.WaitForAttach failed for volume “pvc-4895a379-104b-11e9-9d98-000c29702bc8” : fail to check rbd image status with: (executable file not found in $PATH), rbd output: ()
which took me a little while to figure out. I think reading this page on RBD gave me the hint that there was something (well yeah, the rbd binary specifically) missing on the hosts, but there’s a lot of talk of folk solving this by creating custom images with the rbd binary added to the $PATH in them, replacing core k8s containers with them, which didn’t sound too appealing to me. I had assumed that the images would include the binaries, but hadn’t checked this is any way.
This issue may well be part or possibly all of the reason why I ran the above commands repeatedly and applied all of those patches.
The simple yet not too obvious solution to this – in my case anyway – was to ensure that the ceph common package was available both on the master:
apt-get update && apt-get install ceph-common -y
and critically that it was also available on each of the worker nodes too.
Once that was done, I think I deleted and reapplied everything rook-related again, then things started working as they should, finally.
A quick check:
ansible@umaster:~$ kubectl get sc NAME PROVISIONER AGE rook-block (default) rook.io/block 22h
And things are looking much better now.
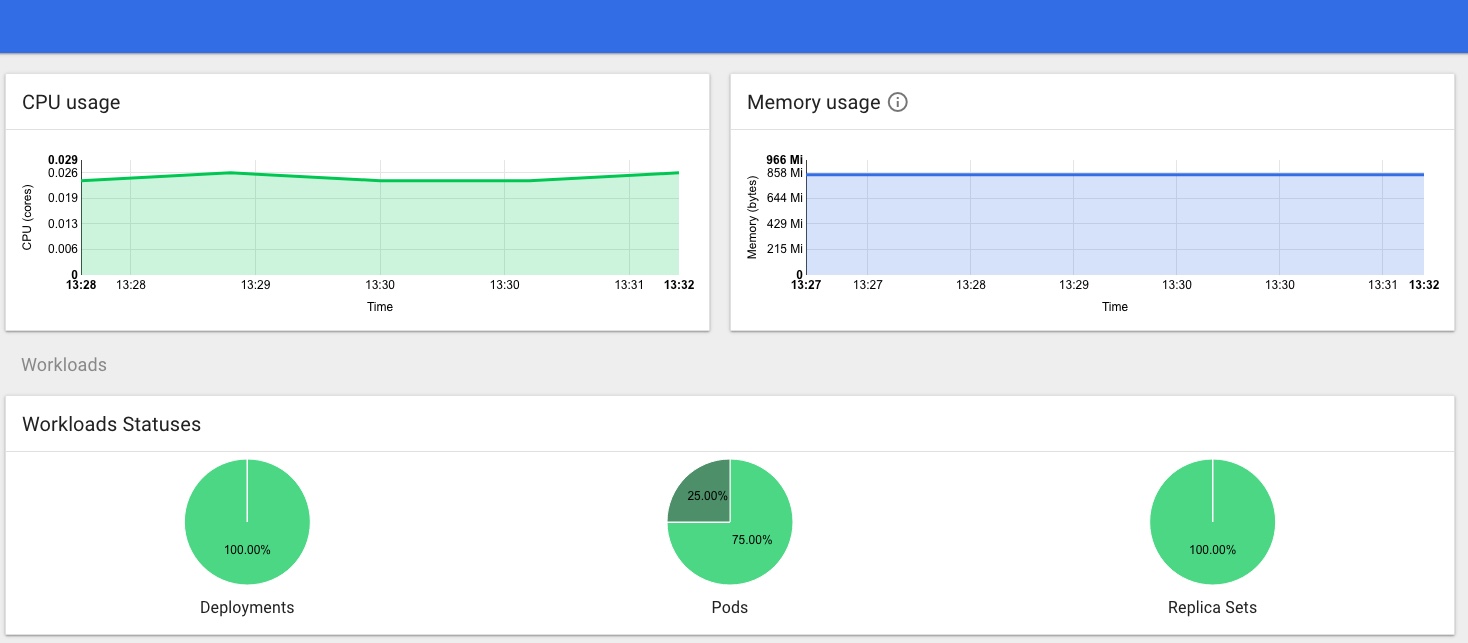
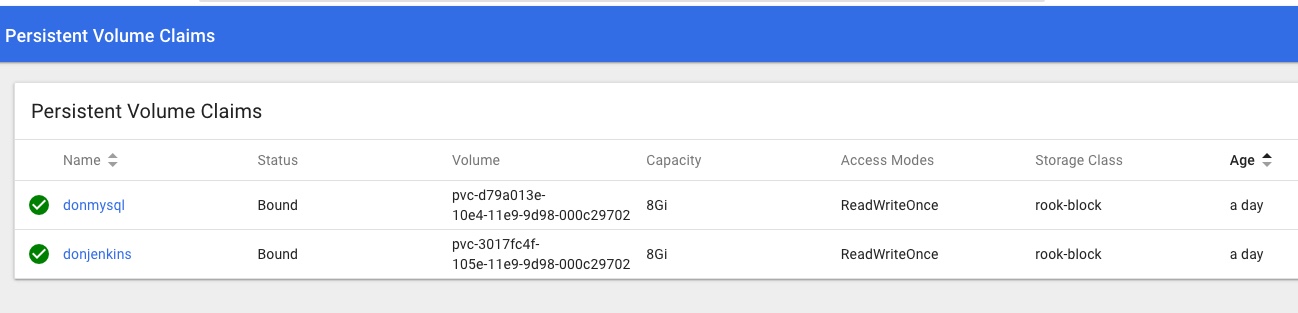
Checking the Dashboard I can see a Rook namespace with a number of Rook pods all looking green, and Persistent Volume Claims in the default namespace too:
Test with an example – “helm install stable/mysql”, take 2…
To verify this I re ran the same Helm Chart for mysql, with no changes or overrides, to ensure that rook provisioning was working, that it was properly detected and used as the default storage class in the Cluster with no args/hints needed.
The output from running “helm install stable/mysql” includes this info:
MySQL can be accessed via port 3306 on the following DNS name from within your cluster: donmysql.default.svc.cluster.local
3. Connect using the mysql cli, then provide your password: $ mysql -h donmysql -p
So I tried the above, opting to create an ubuntu client pod, installing mysql utils to that then connecting to the above MySQL instance with the root password like so:
ansible@umaster:~$ MYSQL_ROOT_PASSWORD=$(kubectl get secret --namespace default donmysql -o jsonpath="{.data.mysql-root-password}" | base64 --decode; echo) ansible@umaster:~$ echo $MYSQL_ROOT_PASSWORD <THE ROOT PASSWORD WAS HERE> ansible@umaster:~$ kubectl run -i --tty ubuntu --image=ubuntu:16.04 --restart=Never -- bash -il If you don't see a command prompt, try pressing enter. root@ubuntu:/# root@ubuntu:/# apt-get update && apt-get install mysql-client -y Get:1 http://archive.ubuntu.com/ubuntu xenial InRelease [247 kB] Get:2 http://security.ubuntu.com/ubuntu xenial-security InRelease [107 kB] <snip a load of boring apt stuff> Setting up mysql-common (5.7.24-0ubuntu0.16.04.1) ... update-alternatives: using /etc/mysql/my.cnf.fallback to provide /etc/mysql/my.cnf (my.cnf) in auto mode Setting up mysql-client-5.7 (5.7.24-0ubuntu0.16.04.1) ... Setting up mysql-client (5.7.24-0ubuntu0.16.04.1) ... Processing triggers for libc-bin (2.23-0ubuntu10) ... root@ubuntu:/# mysql -h donmysql -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 67 Server version: 5.7.14 MySQL Community Server (GPL) <snip some more boring stuff>
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec)
mysql> exit Bye root@ubuntu:/
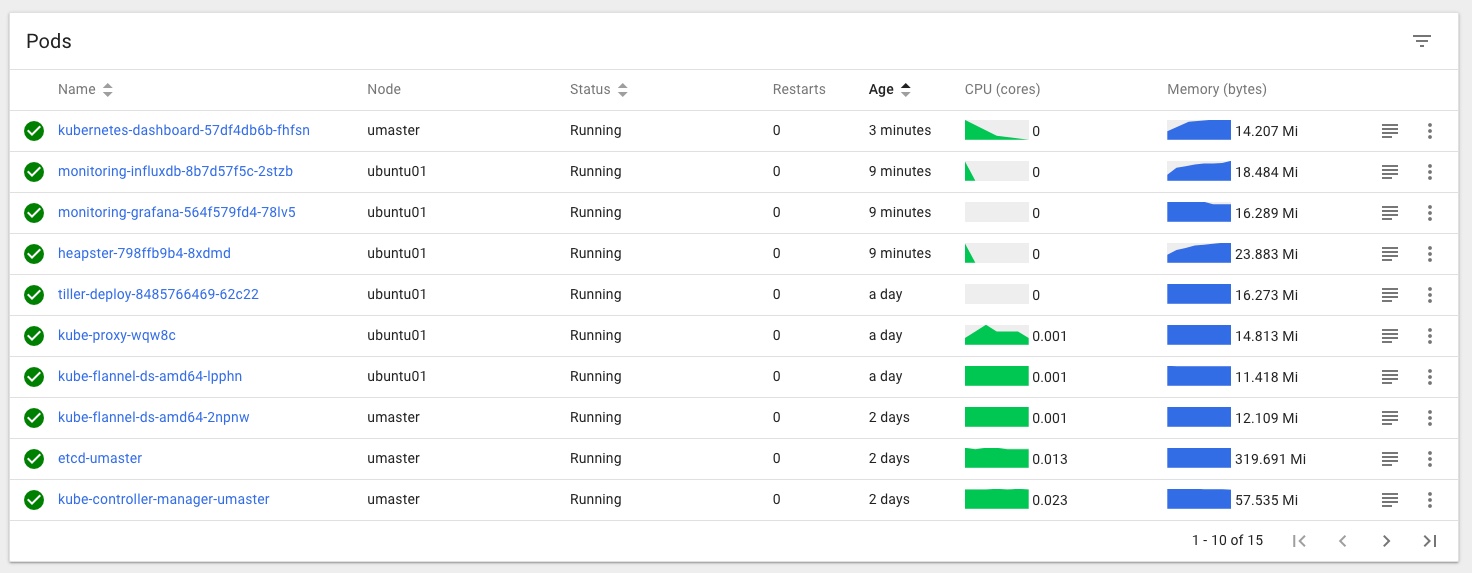
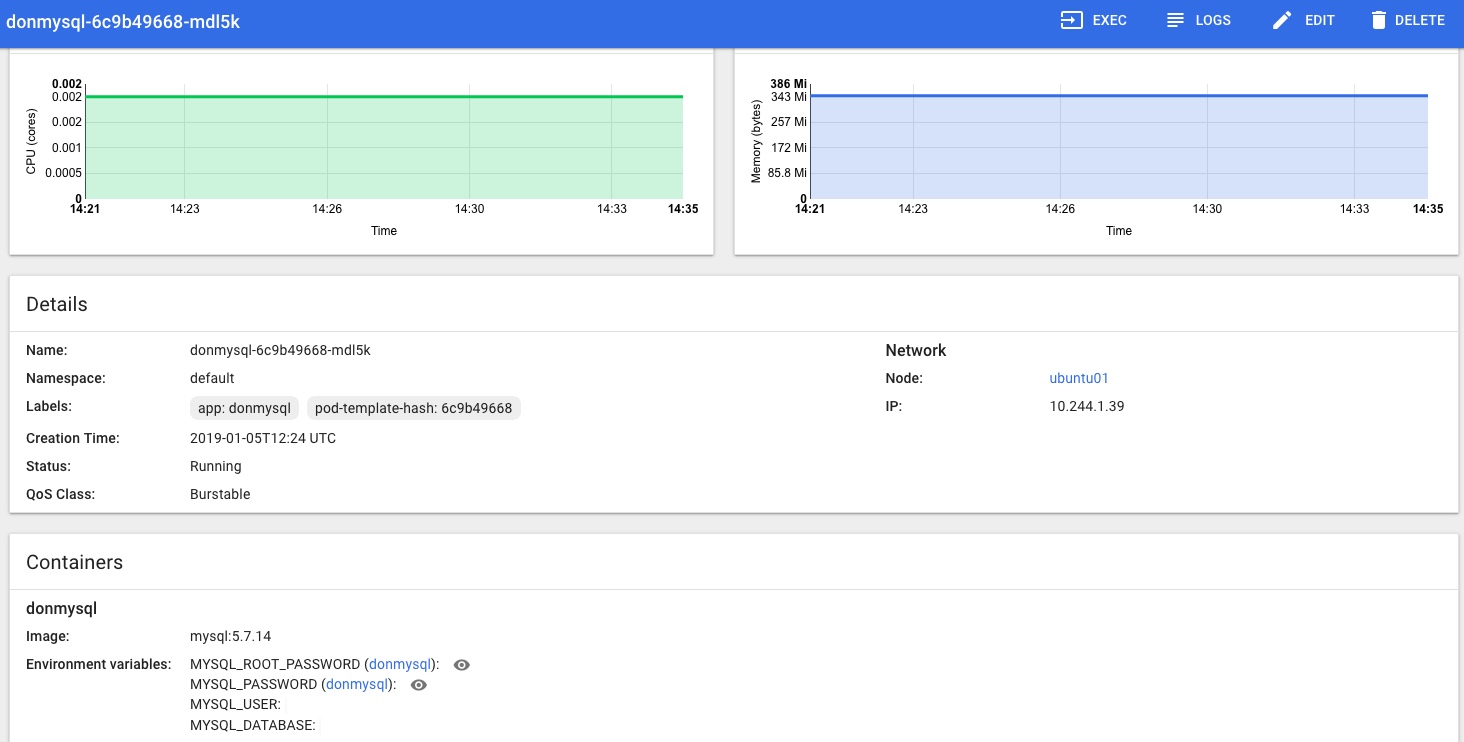
In the Kubernetes Dashboard (loads more on that little adventure coming soon!) I can also see that the MySQL Pod is Running and looks happy, no more Pending or Init issues for me now:
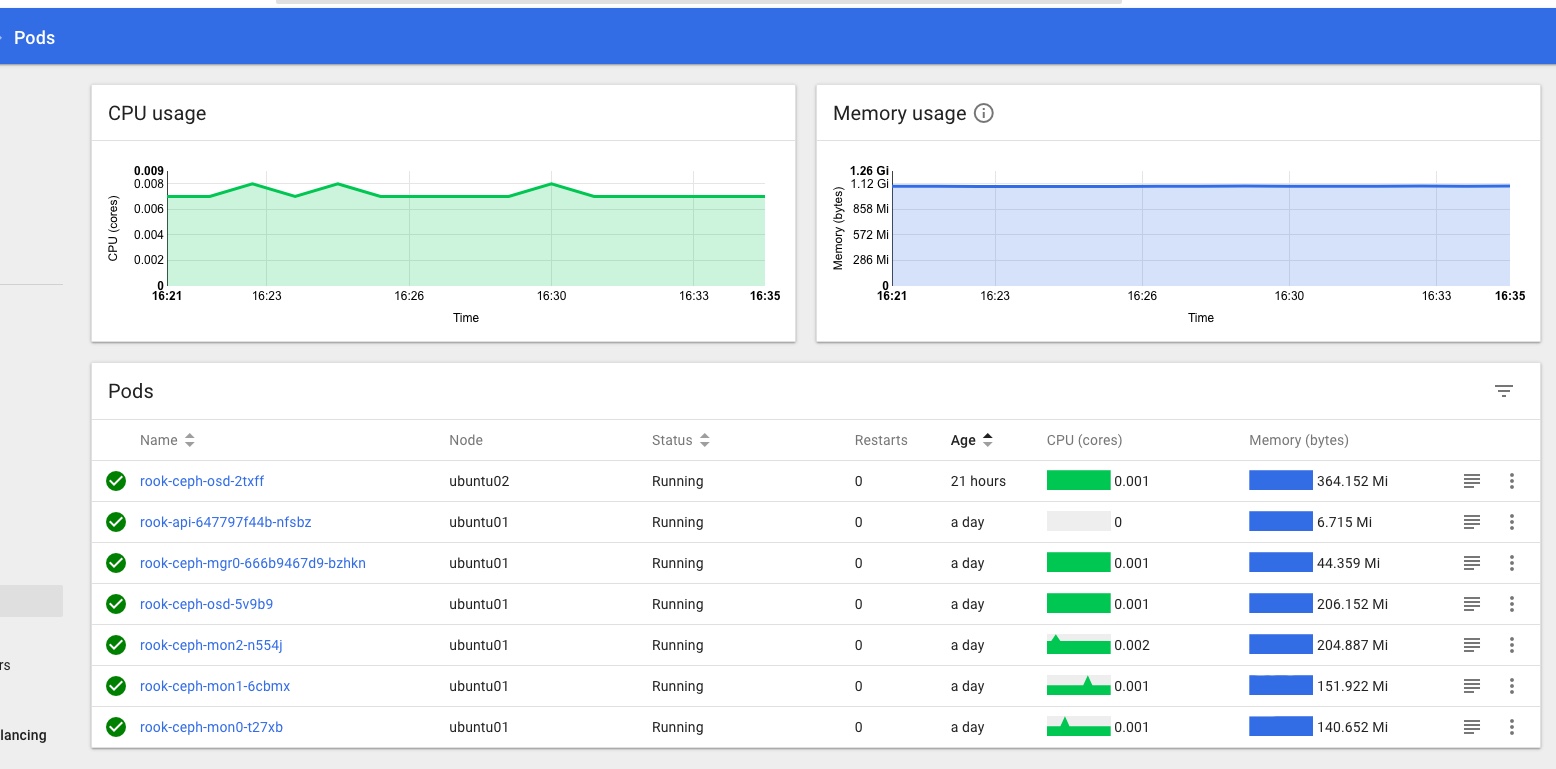
and that the Rook Persistent Volume Claims are present and looking healthy too:
Conclusion & next steps
That’s storage sorted, kind of – I’m not totally happy everything I did was needed, correct and repeatable yet, or that I know enough about this.
Rook.io looks very good and I’m happy it’s the best solution for my current needs, but I can see that I should have spent more time reading the documentation and thinking about prerequisites, yadda yadda. To be honest when it comes to storage I’m a bit of a Luddite – i just want it to be there and work as I’d expect it to, and I was keen to move on to the next steps….
I plan to scrub the k8s cluster shortly and run through this again from scratch to make sure I’ve got it clear enough to add to my provisioning pipeline process.
Next, a probably not-too-brief post on how I got Heapster stats working with an InfluxDB backend monitoring stats for both the Master and Nodes, installing a usable Kubernetes Dashboard, and getting that working with suitable access/permissions, aaaaand getting the k8s Dashbaord showing the CPU and Memory stats from Heapster as seen in the Dashboard pic of the pod statuses above…. phew!
My aim here is to create a Kubernetes environment on my home lab that allows me to play with k8s and related technologies, then quickly and easily rebuild the cluster and start over.
The focus here in on trying out new technologies and solutions and in automating processes, so in this particular context I am not at all bothered with security, High Availability, redundancy or any of the usual considerations.
Helm and Tiller
The quick start guide is very good: https://docs.helm.sh/using_helm/ and I used this as I went through the process of installing Helm, initializing Tiller and deploying it to my Kubernetes cluster, then deploying a first example Chart to the Cluster. The following are my notes from doing this, as I plan to repeat then automate the entire process and am bound to forget something later 🙂
Helm is the best way to find, share, and use software built for Kubernetes.
I have been following this project for a while and it looks to live up to the hype – there’s a rapidly growing and pretty mature collection of Helm Charts available here: https://github.com/helm/charts/tree/master/stable which as you can see covers an impressive amount of things you may want to use in your own Kubernetes cluster.
Get the Helm and Tiller binaries
This is as easy as described – for my architecture it meant simply
and extract and copy the 2 binaries (helm & tiller) to somewhere in your path
I usually do a quick sanity test or 2 – e.g. running “which helm” as a non-root user and maybe check “helm –help” and “helm version” all say something sensible too.
Install Tiller
Helm is the Client side app that directs Tiller, which is the Server side part. Just like steering a ship… and stretching the Kubernetes nautical metaphors to the max.
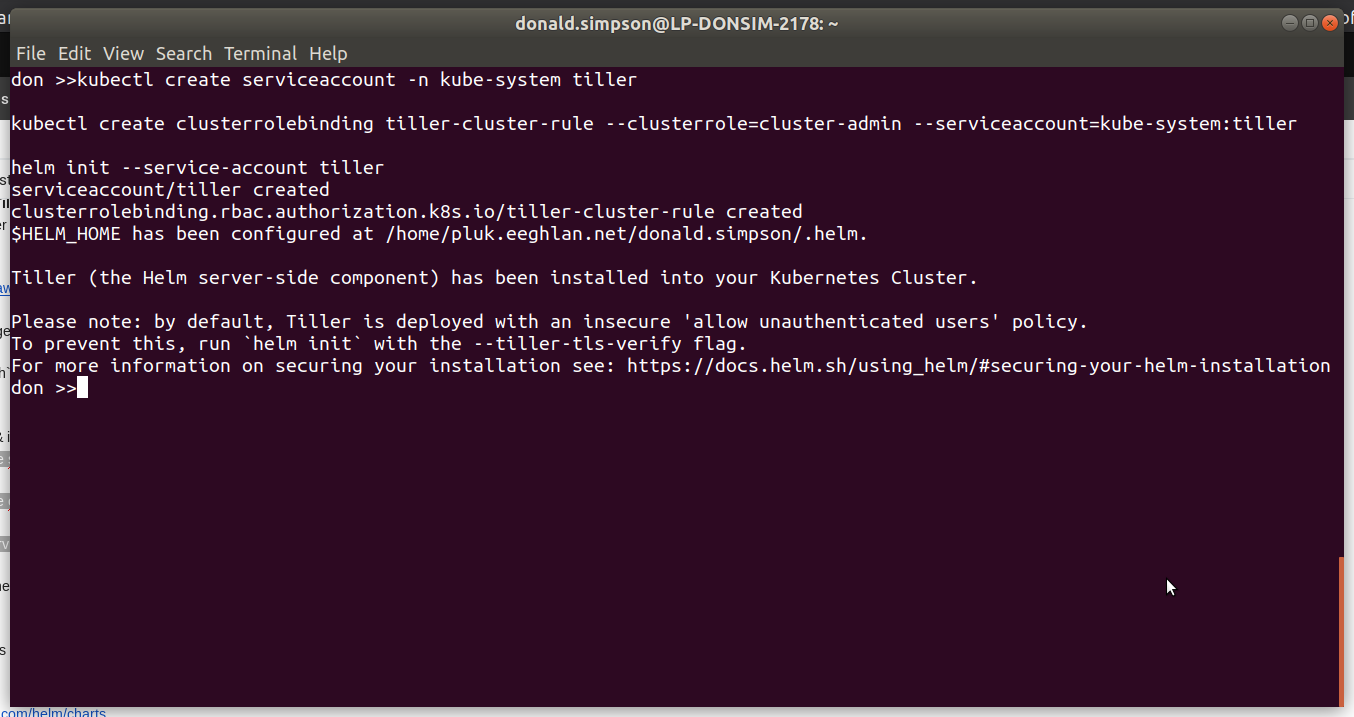
Tiller can be installed to your k8s Cluster simply by running “helm init“, which should produce output like the following:
ansible@umaster:~/helm$ helm init Creating /home/ansible/.helm Creating /home/ansible/.helm/repository Creating /home/ansible/.helm/repository/cache Creating /home/ansible/.helm/repository/local Creating /home/ansible/.helm/plugins Creating /home/ansible/.helm/starters Creating /home/ansible/.helm/cache/archive Creating /home/ansible/.helm/repository/repositories.yaml Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com Adding local repo with URL: http://127.0.0.1:8879/charts $HELM_HOME has been configured at /home/ansible/.helm.
Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster
Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy. To prevent this, run `helm init` with the --tiller-tls-verify flag. For more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installation Happy Helming
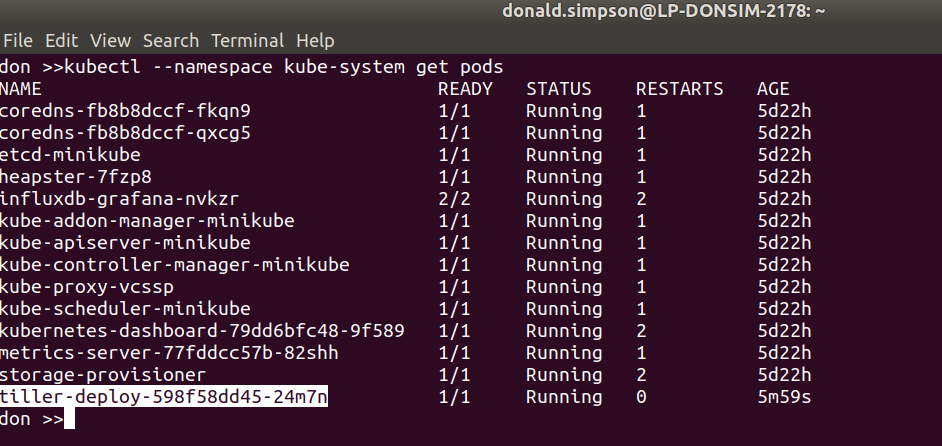
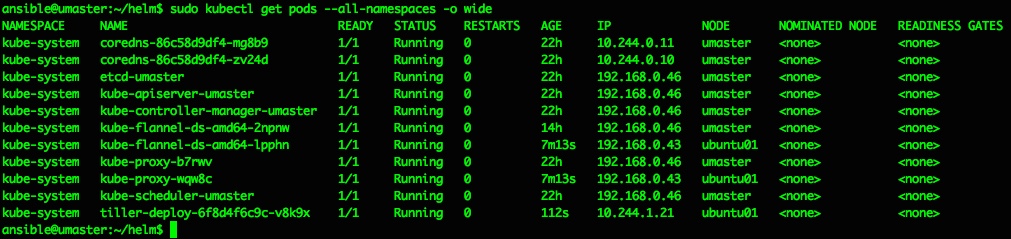
That should do it, and a quick check of running pods confirms we now have a tiller pod running inside the kubernetes cluster in the kube-system namespace:
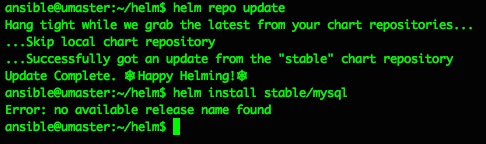
So far so nice and easy, and as per the docs the next steps are to do a repo update and a test chart install…
ansible@umaster:~/helm$ helm repo update Hang tight while we grab the latest from your chart repositories… …Skip local chart repository …Successfully got an update from the "stable" chart repository Update Complete. ⎈ Happy Helming!⎈ ansible@umaster:~/helm$ helm install stable/mysql Error: no available release name found ansible@umaster:~/helm$
Doh. A quick google makes that “Error: no available release name found” look like a k8s/helm version conflict, but the fix is pretty easy and detailed here: https://github.com/helm/helm/issues/3055
So I did as suggested, creating a service account cluster role binding and patch to deploy them to the kube-system namespace:
helm lsansible@umaster:~/helm$ helm ls NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACEdunking-squirrel 1 Thu Jan 3 15:38:37 2019 DEPLOYED mysql-0.12.0 5.7.14 defaultansible@umaster:~/helm$
and all is groovy
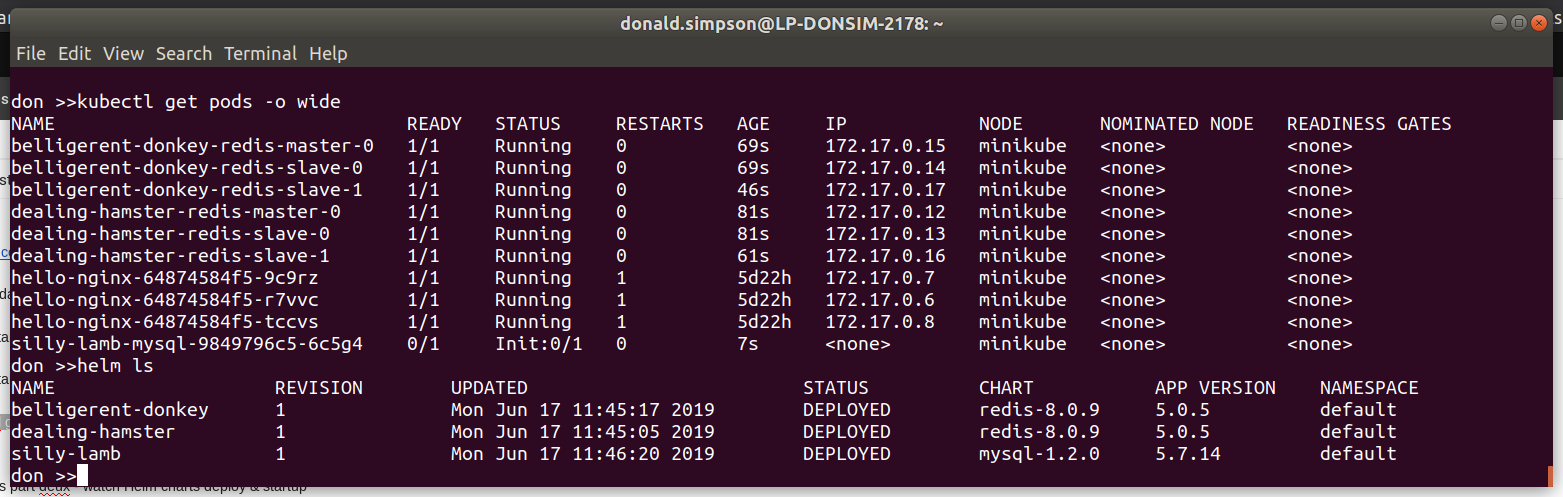
list pods with ansible@umaster:~/helm$ sudo kubectl get pods --all-namespaces -o wide
The MySQL pod is failing to start as it has persistent volume claims defined, and I’ve not set up default storage for that yet – that’s covered in the next step/post 🙂
If you want to use or delete that MySQL deployment all the details are in the rest of the getting started guide – for the above it would mean doing a ‘helm ls‘ then a ‘ helm delete <release-name> ‘ where <release-name> is ‘dunking-squirrel’ or whatever you have.
A little more on Helm
Just running out of the box Helm Charts is great, but obviously there’s a lot more you can do with Helm, from customising the existing Stable Charts to suit your needs, to writing and deploying your own Charts from scratch. I plan to expand on this in more detail later on, but will add and update some notes and examples here as I do:
For me and for now, I’m just happy that Helm, Tiller and Charts are working, and I can move on to automating these setup steps and some testing to my overall pipelines. And sorting out the persistent volumes too. After that’s all done I plan to start playing around with some of the stable (and perhaps not so stable) Helm charts.
As they said, this could well be “the best way to find, share, and use software built for Kubernetes” – it’s very slick!
This is Step 1 in my recent Kubernetes setup where I very quickly describe the process followed to build and configure the basic requirements for a simple Kubernetes cluster.
A quick summary should cover 99% of this, but I wanted to make sure I’d recorded my process/journey to get there – to cut a long story short, I ended up using this Ansible project:
on the 5 Ubuntu linux hosts I created by hand (the horror) on my VMWare ESX home lab server. I started off writing my own ansible playbook which did the job, then went looking for improvements and found the above fitted my needs perfectly.
Host prerequisites are in my rough notes below – simple things like ssh keys, passwwordless sudo from the ansible user, installing required tools like python, setting suitable ip addresses and adding the users you want to use. Also allocating suitable amounts of mem, cpu and disk – all of which are down to your preference, availability and expectations.
TASK [Add a new user named provision] ****************************************************************************************************************************************************************************************************************************************** fatal:
[ubuntu02]
: FAILED! => {"msg": "to use the 'ssh' connection type
with passwords, you must install the sshpass program"} for each node/slave/hostsudo apt-get install -y sshpass
results in:root@umaster:~# kubeadm init [init] using Kubernetes version: v1.11.1 [preflight] running pre-flight checks I0730 15:17:50.330589 23504 kernel_validator.go:81] Validating kernel version I0730 15:17:50.330701 23504 kernel_validator.go:96] Validating kernel config
[WARNING SystemVerification]: docker version is greater than the most
recently validated version. Docker version: 17.12.1-ce. Max validated
version: 17.03 [preflight] Some fatal errors occurred: [ERROR Swap]: running with swap on is not supported. Please disable swap [preflight] If you know what you are doing, you can make a check non-fatal with `–ignore-preflight-errors=…` root@umaster:~# doswapoff -a then try again kubeadm init… wait for images to be pulled etc – takes a while
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
I’ll write about this in more detail in another post…
Please note that none of this is production grade or recommended, it’s simply what I have done to suit my needs in my home lab. My focus is on automating Kubernetes processes and deployments, not creating highly available bullet-proof production systems.
To reset and restore a ‘new’ cluster, first on the master instance – reboot and as a normal user (I’m using an “ansible” user with sudo throughout):
I’m passing that CIDR address as I’m using Flannel for pod networking (details follow) – if you use something else you may not need that, but may well need something else.
That should be the MASTER started, with a message to add nodes with:
which all sounds good, but the first most basic check produces the following error:
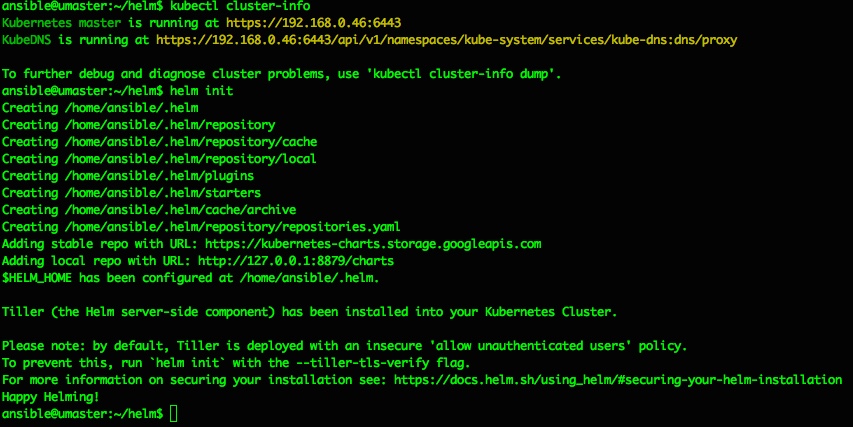
ansible@umaster:~$ kubectl cluster-info
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'. Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
which I think is due to the kubeadm reset cleaning up the previous config, but can be easily fixed with this:
ansible@umaster:~$ sudo kubectl cluster-info Kubernetes master is running at https://192.168.0.46:6443 KubeDNS is running at https://192.168.0.46:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
————- ADD NODES ——————
Use the command and token provided by the master on the worker node(s) (in my case that’s “ubuntu01” to “ubuntu04”). Again I’m running as the ansible user everywhere, and I’m disabling swap and doing a kubeadm reset first as I want this repeatable:
Or, as I’ve just found out, the more recent versions ok k8s provide “kubeadm token create –print-join-command”, which provide output like the following example that you can save to a file/variable/whatever:
I believe options to specify json or alternative output formatting is in the works too.
That’s all that is needed, if you’ve not used this node already it may take a while to pull things in but if you have it should be pretty much instant.
When ready, running a quick check on the MASTER shows the connected node (ubuntu01) and the Master (umaster) and their status:
ansible@umaster:~$ sudo kubectl get nodes --all-namespaces NAME STATUS ROLES AGE VERSION ubuntu01 NotReady <none> 27s v1.13.1 umaster NotReady master 8m26s v1.13
The NotReady status is because there’s no pod network available – see here for details and options:
so apply a pod network (I’m using flannel) like this on the Master only:
ansible@umaster:~$ sudo kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/bc79dd1505b0c8681ece4de4c0d86c5cd2643275/Documentation/kube-flannel.yml clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.extensions/kube-flannel-ds-amd64 created daemonset.extensions/kube-flannel-ds-arm64 created daemonset.extensions/kube-flannel-ds-arm created daemonset.extensions/kube-flannel-ds-ppc64le created daemonset.extensions/kube-flannel-ds-s390x created
Then check again and things should look better now they can communicate…
ansible@umaster:~$ sudo kubectl get nodes --all-namespaces NAME STATUS ROLES AGE VERSION ubuntu01 Ready <none> 2m23s v1.13.1 umaster Ready master 10m v1.13.1 ansible@umaster:~$
Adding any number of subsequent nodes is very easy and exactly the same (the pod networking setup is a one-off step on the master only). I added all 4 of my worker vms and checked they were all Ready and “schedulable”. My server coped with this no problem at all. Note that by default you can’t schedule tasks on the Master, but this can be changed if you want to.
That’s the very basic “reset and restore” steps done. I plan to add this process to a Jenkins Pipeline, so that I can chain a complete cluster destroy/reprovision and application build, deploy and test process together.
The next steps I did were to:
install the Kubernetes Dashboard to the cluster
configure the Kubernetes Dashboard and fix permissions
deploy a sample application, replicaset & service and expose it to the network
configure Heapster
which I’ll post more on soonish… and I’ll add the precursor to this post on the host provisioning and kubeadm setup too.