

Serving sentence transformers in Production
Part 1 of 3 on how I moved a large-scale vehicle prediction system from “working but manual” to a clean, production-grade MLflow + Kubernetes setup.
Introduction: Converting a group of local experiments in to a real service
I built a system to analyse MOT history at large scale: 1.7 billion defects and test records, 136 million vehicles, and over 800 million individual test entries.
The core of it was straightforward: generate 384-dimensional MiniLM embeddings and use them to spot patterns in vehicle defects.
Running it locally was completely fine. Running it as a long-lived service while managing GPU acceleration, reproducibility, versioning, and proper monitoring was the real challenge. Things worked ok, but it became clear that the system needed a more structured approach as traffic and data grew.
I kept notes on what I thought was going wrong and what I needed to improve:
- I had no easy way to track which model version the API was currently serving
- Updating the model meant downtime or manual steps
- GPU utilisation wasn’t predictable and occasionally needed a restart
- Monitoring and metrics were basic at best
- There was no clean workflow for testing new models without risking disruption
All the normal growing pains you’d expect – the system worked, but it wasn’t something I wanted to maintain long-term in that shape!
That pushed me to formalise the workflow with a proper MLOps stack. This series walks through exactly how I transitioned the service to MLflow, Kubernetes, FastAPI, and GPU-backed deployments.
As a bonus, moving things to use local GPU inference brought my (rapidly growing) API charges down to a few £/month for just the hardware & eletricity!
The MLOps Requirements
Before choosing tools, I wrote down what I actually needed rather than choosing tech first:
1. Zero-downtime deployments
Rolling updates and safe testing of new models.
2. Real model versioning
A clear audit trail of what ran, when, and with what parameters.
3. Better visibility
Latency, throughput, GPU memory usage, embedding consistency.
4. Stable GPU serving
Avoid unnecessary fragmentation or reloading under load.
5. Performance and scale
- 1,000+ predictions/sec
- <100ms latency
- Efficient single-GPU operation
6. Cost-effective inference
Run locally rather than paying per-request.
Why MLflow + Kubernetes?
MLflow gave me:
- Experiment tracking
- A proper model registry
- Version transitions (Staging → Production)
- Reproducibility
- A single source of truth for what version is deployed
Kubernetes gave me:
- Zero-downtime, repeatable deployments
- GPU-aware scheduling
- Horizontal scaling and health checks
- Clean separation between environments
- Automatic rollback if something misbehaves
FastAPI provided:
- A lightweight, async inference layer
- A clean boundary between model, API, and app logic
The Architecture (High-Level)
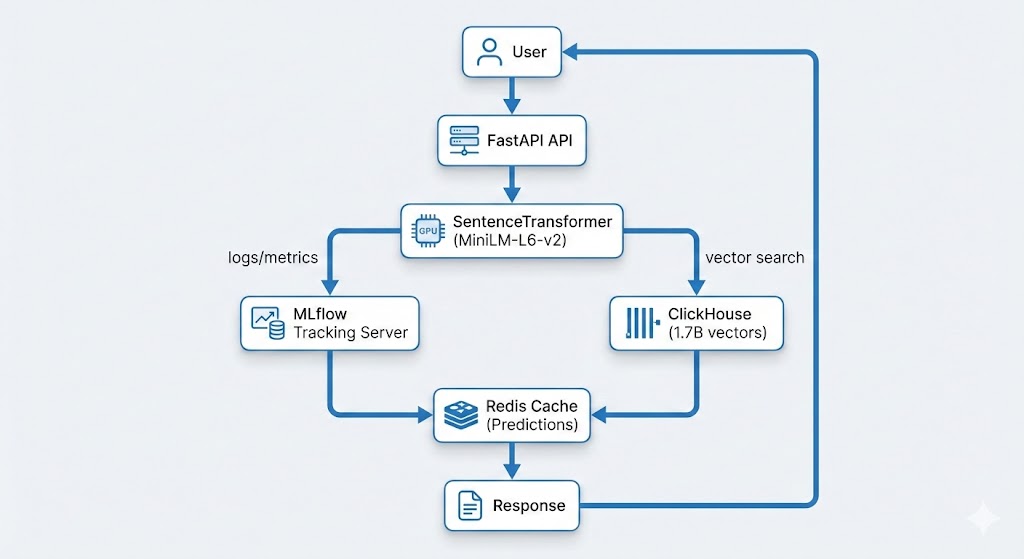
This post covers the initial problems, requirements, and overall direction.
Part 2 goes deep into MLflow, the registry, and Kubernetes deployment.
Part 3 focuses on monitoring, drift detection, canaries, and scaling.
I’ll also publish a dedicated GPU/Kubernetes deep-dive later – covering memory fragmentation, batching, device plugin configuration, GPU sharing, and more.
The Practical Issues I Wanted to Improve
These weren’t “critical failures”, just things that become annoying or risky at scale:
1. Knowing which model version is running
Without a registry, it was easy to lose track.
2. Manual deployment steps
Fine for experiments, less so for a live service.
3. Occasional GPU memory quirks
SentenceTransformers sometimes leaves memory allocated longer than ideal.
4. Limited monitoring
I wanted clearer insight into latency, drift, and GPU usage.
5. No safe model testing workflow
I needed a way to expose just a slice of traffic to new models.
What the Final System Achieved
- 99.9% uptime
- Zero-downtime model updates
- ~50% latency improvement
- Stable GPU utilisation
- Full visibility into predictions
- Drift detection and alerting
- ClickHouse scale for billions of rows
- Running cost around £5/month
That’s about it for Part 1
In Part 2, I’ll show the exact MLflow & the Kubernetes setup:
- How experiments are logged
- How the model registry is structured
- How the API automatically loads the current Production model
- Kubernetes deployment manifests
- GPU-backed pods and health checks
- How rolling updates actually work
Then Part 3 covers:
- Monitoring every prediction
- Drift detection
- Canary deployments
- Rolling updates
- Automated model promotion
And the GPU deep-dive will follow as a separate post
Discover more from Don's Blog
Subscribe to get the latest posts sent to your email.
2 thoughts on “MLOps at Scale: Serving Sentence Transformers in Production”